 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat can Off-the-Shelves Large Multi-Modal Models do for Dynamic Scene Graph Generation?
Mar 20, 2025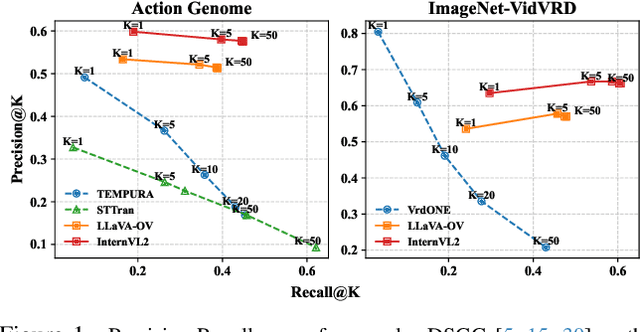
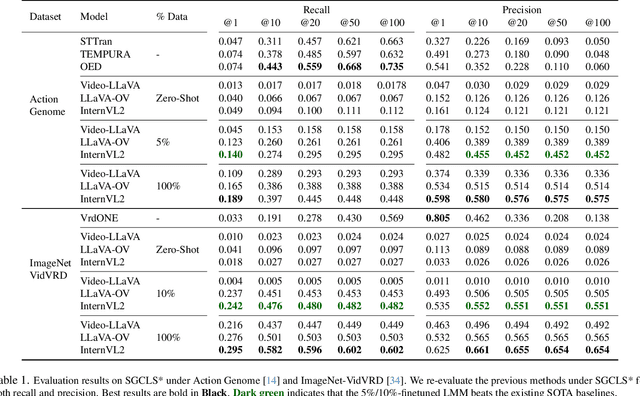

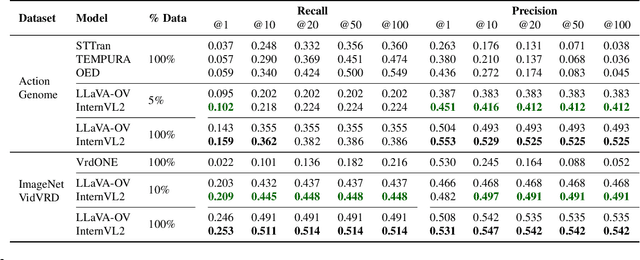
Dynamic Scene Graph Generation (DSGG) for videos is a challenging task in computer vision. While existing approaches often focus on sophisticated architectural design and solely use recall during evaluation, we take a closer look at their predicted scene graphs and discover three critical issues with existing DSGG methods: severe precision-recall trade-off, lack of awareness on triplet importance, and inappropriate evaluation protocols. On the other hand, recent advances of Large Multimodal Models (LMMs) have shown great capabilities in video understanding, yet they have not been tested on fine-grained, frame-wise understanding tasks like DSGG. In this work, we conduct the first systematic analysis of Video LMMs for performing DSGG. Without relying on sophisticated architectural design, we show that LMMs with simple decoder-only structure can be turned into State-of-the-Art scene graph generators that effectively overcome the aforementioned issues, while requiring little finetuning (5-10% training data).