 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Then Embed: Generative Context Improves Multimodal Embedding
Oct 06, 2025There is a growing interest in Universal Multimodal Embeddings (UME), where models are required to generate task-specific representations. While recent studies show that Multimodal Large Language Models (MLLMs) perform well on such tasks, they treat MLLMs solely as encoders, overlooking their generative capacity. However, such an encoding paradigm becomes less effective as instructions become more complex and require compositional reasoning. Inspired by the proven effectiveness of chain-of-thought reasoning, we propose a general Think-Then-Embed (TTE) framework for UME, composed of a reasoner and an embedder. The reasoner MLLM first generates reasoning traces that explain complex queries, followed by an embedder that produces representations conditioned on both the original query and the intermediate reasoning. This explicit reasoning step enables more nuanced understanding of complex multimodal instructions. Our contributions are threefold. First, by leveraging a powerful MLLM reasoner, we achieve state-of-the-art performance on the MMEB-V2 benchmark, surpassing proprietary models trained on massive in-house datasets. Second, to reduce the dependency on large MLLM reasoners, we finetune a smaller MLLM reasoner using high-quality embedding-centric reasoning traces, achieving the best performance among open-source models with a 7% absolute gain over recently proposed models. Third, we investigate strategies for integrating the reasoner and embedder into a unified model for improved efficiency without sacrificing performance.
What can Off-the-Shelves Large Multi-Modal Models do for Dynamic Scene Graph Generation?
Mar 20, 2025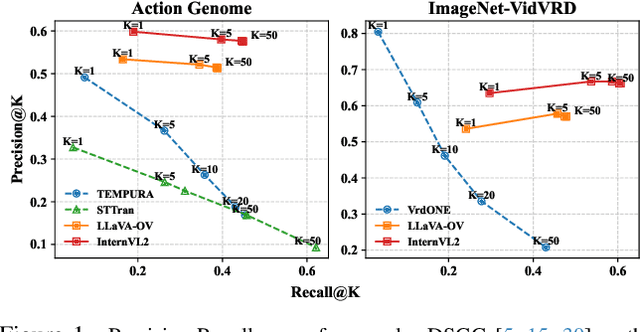
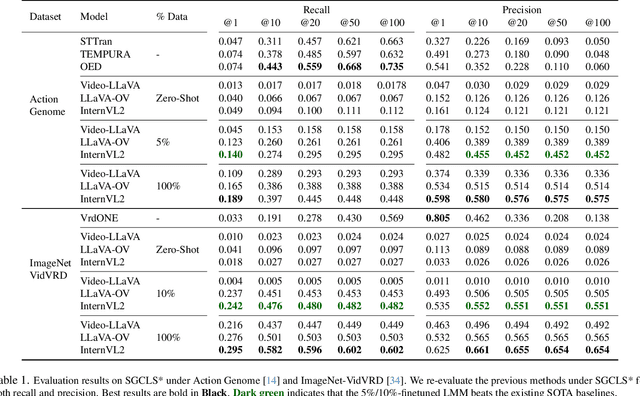

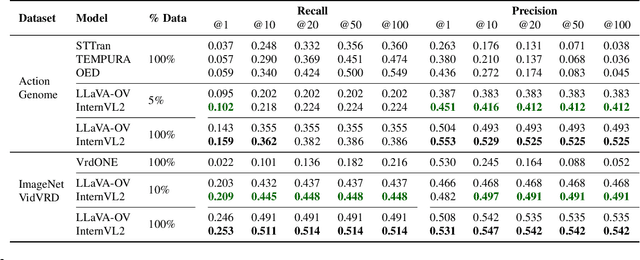
Dynamic Scene Graph Generation (DSGG) for videos is a challenging task in computer vision. While existing approaches often focus on sophisticated architectural design and solely use recall during evaluation, we take a closer look at their predicted scene graphs and discover three critical issues with existing DSGG methods: severe precision-recall trade-off, lack of awareness on triplet importance, and inappropriate evaluation protocols. On the other hand, recent advances of Large Multimodal Models (LMMs) have shown great capabilities in video understanding, yet they have not been tested on fine-grained, frame-wise understanding tasks like DSGG. In this work, we conduct the first systematic analysis of Video LMMs for performing DSGG. Without relying on sophisticated architectural design, we show that LMMs with simple decoder-only structure can be turned into State-of-the-Art scene graph generators that effectively overcome the aforementioned issues, while requiring little finetuning (5-10% training data).
AirSketch: Generative Motion to Sketch
Jul 12, 2024Illustration is a fundamental mode of human expression and communication. Certain types of motion that accompany speech can provide this illustrative mode of communication. While Augmented and Virtual Reality technologies (AR/VR) have introduced tools for producing drawings with hand motions (air drawing), they typically require costly hardware and additional digital markers, thereby limiting their accessibility and portability. Furthermore, air drawing demands considerable skill to achieve aesthetic results. To address these challenges, we introduce the concept of AirSketch, aimed at generating faithful and visually coherent sketches directly from hand motions, eliminating the need for complicated headsets or markers. We devise a simple augmentation-based self-supervised training procedure, enabling a controllable image diffusion model to learn to translate from highly noisy hand tracking images to clean, aesthetically pleasing sketches, while preserving the essential visual cues from the original tracking data. We present two air drawing datasets to study this problem. Our findings demonstrate that beyond producing photo-realistic images from precise spatial inputs, controllable image diffusion can effectively produce a refined, clear sketch from a noisy input. Our work serves as an initial step towards marker-less air drawing and reveals distinct applications of controllable diffusion models to AirSketch and AR/VR in general.
On the Robustness of Large Multimodal Models Against Image Adversarial Attacks
Dec 08, 2023Recent advances in instruction tuning have led to the development of State-of-the-Art Large Multimodal Models (LMMs). Given the novelty of these models, the impact of visual adversarial attacks on LMMs has not been thoroughly examined. We conduct a comprehensive study of the robustness of various LMMs against different adversarial attacks, evaluated across tasks including image classification, image captioning, and Visual Question Answer (VQA). We find that in general LMMs are not robust to visual adversarial inputs. However, our findings suggest that context provided to the model via prompts, such as questions in a QA pair helps to mitigate the effects of visual adversarial inputs. Notably, the LMMs evaluated demonstrated remarkable resilience to such attacks on the ScienceQA task with only an 8.10% drop in performance compared to their visual counterparts which dropped 99.73%. We also propose a new approach to real-world image classification which we term query decomposition. By incorporating existence queries into our input prompt we observe diminished attack effectiveness and improvements in image classification accuracy. This research highlights a previously under-explored facet of LMM robustness and sets the stage for future work aimed at strengthening the resilience of multimodal systems in adversarial environments.