 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePro-Cap: Leveraging a Frozen Vision-Language Model for Hateful Meme Detection
Aug 16, 2023



Hateful meme detection is a challenging multimodal task that requires comprehension of both vision and language, as well as cross-modal interactions. Recent studies have tried to fine-tune pre-trained vision-language models (PVLMs) for this task. However, with increasing model sizes, it becomes important to leverage powerful PVLMs more efficiently, rather than simply fine-tuning them. Recently, researchers have attempted to convert meme images into textual captions and prompt language models for predictions. This approach has shown good performance but suffers from non-informative image captions. Considering the two factors mentioned above, we propose a probing-based captioning approach to leverage PVLMs in a zero-shot visual question answering (VQA) manner. Specifically, we prompt a frozen PVLM by asking hateful content-related questions and use the answers as image captions (which we call Pro-Cap), so that the captions contain information critical for hateful content detection. The good performance of models with Pro-Cap on three benchmarks validates the effectiveness and generalization of the proposed method.
Decoding the Underlying Meaning of Multimodal Hateful Memes
May 28, 2023



Recent studies have proposed models that yielded promising performance for the hateful meme classification task. Nevertheless, these proposed models do not generate interpretable explanations that uncover the underlying meaning and support the classification output. A major reason for the lack of explainable hateful meme methods is the absence of a hateful meme dataset that contains ground truth explanations for benchmarking or training. Intuitively, having such explanations can educate and assist content moderators in interpreting and removing flagged hateful memes. This paper address this research gap by introducing Hateful meme with Reasons Dataset (HatReD), which is a new multimodal hateful meme dataset annotated with the underlying hateful contextual reasons. We also define a new conditional generation task that aims to automatically generate underlying reasons to explain hateful memes and establish the baseline performance of state-of-the-art pre-trained language models on this task. We further demonstrate the usefulness of HatReD by analyzing the challenges of the new conditional generation task in explaining memes in seen and unseen domains. The dataset and benchmark models are made available here: https://github.com/Social-AI-Studio/HatRed
Prompting for Multimodal Hateful Meme Classification
Feb 08, 2023Hateful meme classification is a challenging multimodal task that requires complex reasoning and contextual background knowledge. Ideally, we could leverage an explicit external knowledge base to supplement contextual and cultural information in hateful memes. However, there is no known explicit external knowledge base that could provide such hate speech contextual information. To address this gap, we propose PromptHate, a simple yet effective prompt-based model that prompts pre-trained language models (PLMs) for hateful meme classification. Specifically, we construct simple prompts and provide a few in-context examples to exploit the implicit knowledge in the pre-trained RoBERTa language model for hateful meme classification. We conduct extensive experiments on two publicly available hateful and offensive meme datasets. Our experimental results show that PromptHate is able to achieve a high AUC of 90.96, outperforming state-of-the-art baselines on the hateful meme classification task. We also perform fine-grained analyses and case studies on various prompt settings and demonstrate the effectiveness of the prompts on hateful meme classification.
On Explaining Multimodal Hateful Meme Detection Models
Apr 06, 2022



Hateful meme detection is a new multimodal task that has gained significant traction in academic and industry research communities. Recently, researchers have applied pre-trained visual-linguistic models to perform the multimodal classification task, and some of these solutions have yielded promising results. However, what these visual-linguistic models learn for the hateful meme classification task remains unclear. For instance, it is unclear if these models are able to capture the derogatory or slurs references in multimodality (i.e., image and text) of the hateful memes. To fill this research gap, this paper propose three research questions to improve our understanding of these visual-linguistic models performing the hateful meme classification task. We found that the image modality contributes more to the hateful meme classification task, and the visual-linguistic models are able to perform visual-text slurs grounding to a certain extent. Our error analysis also shows that the visual-linguistic models have acquired biases, which resulted in false-positive predictions.
Disentangling Hate in Online Memes
Aug 09, 2021
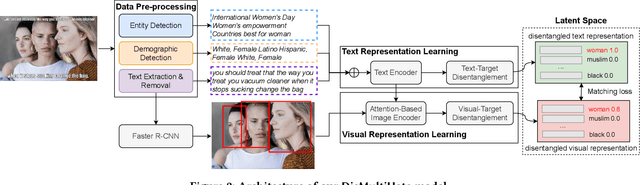
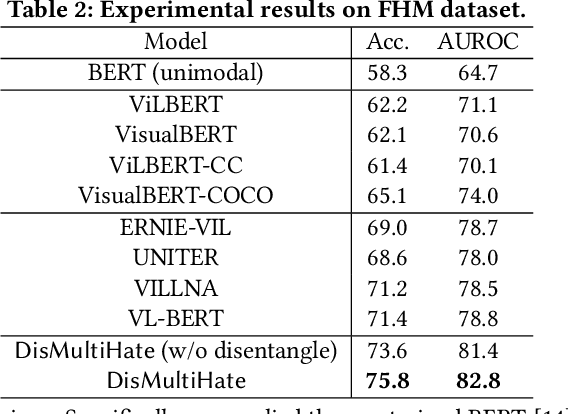

Hateful and offensive content detection has been extensively explored in a single modality such as text. However, such toxic information could also be communicated via multimodal content such as online memes. Therefore, detecting multimodal hateful content has recently garnered much attention in academic and industry research communities. This paper aims to contribute to this emerging research topic by proposing DisMultiHate, which is a novel framework that performed the classification of multimodal hateful content. Specifically, DisMultiHate is designed to disentangle target entities in multimodal memes to improve hateful content classification and explainability. We conduct extensive experiments on two publicly available hateful and offensive memes datasets. Our experiment results show that DisMultiHate is able to outperform state-of-the-art unimodal and multimodal baselines in the hateful meme classification task. Empirical case studies were also conducted to demonstrate DisMultiHate's ability to disentangle target entities in memes and ultimately showcase DisMultiHate's explainability of the multimodal hateful content classification task.