 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Selection for Large-Scale Pre-Training Data via Policy Gradient-based Mask Learning
Dec 30, 2025A fine-grained data recipe is crucial for pre-training large language models, as it can significantly enhance training efficiency and model performance. One important ingredient in the recipe is to select samples based on scores produced by defined rules, LLM judgment, or statistical information in embeddings, which can be roughly categorized into quality and diversity metrics. Due to the high computational cost when applied to trillion-scale token pre-training datasets such as FineWeb and DCLM, these two or more types of metrics are rarely considered jointly in a single selection process. However, in our empirical study, selecting samples based on quality metrics exhibit severe diminishing returns during long-term pre-training, while selecting on diversity metrics removes too many valuable high-quality samples, both of which limit pre-trained LLMs' capabilities. Therefore, we introduce DATAMASK, a novel and efficient joint learning framework designed for large-scale pre-training data selection that can simultaneously optimize multiple types of metrics in a unified process, with this study focusing specifically on quality and diversity metrics. DATAMASK approaches the selection process as a mask learning problem, involving iterative sampling of data masks, computation of policy gradients based on predefined objectives with sampled masks, and updating of mask sampling logits. Through policy gradient-based optimization and various acceleration enhancements, it significantly reduces selection time by 98.9% compared to greedy algorithm, enabling our study to explore joint learning within trillion-scale tokens. With DATAMASK, we select a subset of about 10% from the 15 trillion-token FineWeb dataset, termed FineWeb-Mask. Evaluated across 12 diverse tasks, we achieves significant improvements of 3.2% on a 1.5B dense model and 1.9% on a 7B MoE model.
Selecting Auxiliary Data via Neural Tangent Kernels for Low-Resource Domains
Nov 10, 2025Large language models (LLMs) have achieved remarkable success across widespread tasks, yet their application in low-resource domains remains a significant challenge due to data scarcity and the high risk of overfitting. While in-domain data is limited, there exist vast amounts of similar general-domain data, and our initial findings reveal that they could potentially serve as auxiliary supervision for domain enhancement. This observation leads us to our central research question: \textbf{\textit{how to effectively select the most valuable auxiliary data to maximize domain-specific performance}}, particularly when traditional methods are inapplicable due to a lack of large in-domain data pools or validation sets. To address this, we propose \textbf{NTK-Selector}, a principled and efficient framework for selecting general-domain auxiliary data to enhance domain-specific performance via neural tangent kernels (NTK). Our method tackles two challenges of directly applying NTK to LLMs, theoretical assumptions and prohibitive computational cost, by empirically demonstrating a stable NTK-like behavior in LLMs during LoRA fine-tuning and proposing a Jacobian-free approximation method. Extensive experiments across four low-resource domains (medical, financial, legal, and psychological) demonstrate that NTK-Selector consistently improves downstream performance. Specifically, fine-tuning on 1,000 in-domain samples alone only yielded +0.8 points for Llama3-8B-Instruct and +0.9 points for Qwen3-8B. In contrast, enriching with 9,000 auxiliary samples selected by NTK-Selector led to substantial \textbf{gains of +8.7 and +5.1 points}, which corresponds to a \textbf{10.9x and 5.7x improvement} over the domain-only setting.
ChestX-Reasoner: Advancing Radiology Foundation Models with Reasoning through Step-by-Step Verification
Apr 29, 2025Recent advances in reasoning-enhanced large language models (LLMs) and multimodal LLMs (MLLMs) have significantly improved performance in complex tasks, yet medical AI models often overlook the structured reasoning processes inherent in clinical practice. In this work, we present ChestX-Reasoner, a radiology diagnosis MLLM designed to leverage process supervision mined directly from clinical reports, reflecting the step-by-step reasoning followed by radiologists. We construct a large dataset by extracting and refining reasoning chains from routine radiology reports. Our two-stage training framework combines supervised fine-tuning and reinforcement learning guided by process rewards to better align model reasoning with clinical standards. We introduce RadRBench-CXR, a comprehensive benchmark featuring 59K visual question answering samples with 301K clinically validated reasoning steps, and propose RadRScore, a metric evaluating reasoning factuality, completeness, and effectiveness. ChestX-Reasoner outperforms existing medical and general-domain MLLMs in both diagnostic accuracy and reasoning ability, achieving 16%, 5.9%, and 18% improvements in reasoning ability compared to the best medical MLLM, the best general MLLM, and its base model, respectively, as well as 3.3%, 24%, and 27% improvements in outcome accuracy. All resources are open-sourced to facilitate further research in medical reasoning MLLMs.
Combatting Dimensional Collapse in LLM Pre-Training Data via Diversified File Selection
Apr 29, 2025Selecting high-quality pre-training data for large language models (LLMs) is crucial for enhancing their overall performance under limited computation budget, improving both training and sample efficiency. Recent advancements in file selection primarily rely on using an existing or trained proxy model to assess the similarity of samples to a target domain, such as high quality sources BookCorpus and Wikipedia. However, upon revisiting these methods, the domain-similarity selection criteria demonstrates a diversity dilemma, i.e.dimensional collapse in the feature space, improving performance on the domain-related tasks but causing severe degradation on generic performance. To prevent collapse and enhance diversity, we propose a DiverSified File selection algorithm (DiSF), which selects the most decorrelated text files in the feature space. We approach this with a classical greedy algorithm to achieve more uniform eigenvalues in the feature covariance matrix of the selected texts, analyzing its approximation to the optimal solution under a formulation of $\gamma$-weakly submodular optimization problem. Empirically, we establish a benchmark and conduct extensive experiments on the TinyLlama architecture with models from 120M to 1.1B parameters. Evaluating across nine tasks from the Harness framework, DiSF demonstrates a significant improvement on overall performance. Specifically, DiSF saves 98.5% of 590M training files in SlimPajama, outperforming the full-data pre-training within a 50B training budget, and achieving about 1.5x training efficiency and 5x data efficiency.
Continual Task Learning through Adaptive Policy Self-Composition
Nov 18, 2024



Training a generalizable agent to continually learn a sequence of tasks from offline trajectories is a natural requirement for long-lived agents, yet remains a significant challenge for current offline reinforcement learning (RL) algorithms. Specifically, an agent must be able to rapidly adapt to new tasks using newly collected trajectories (plasticity), while retaining knowledge from previously learned tasks (stability). However, systematic analyses of this setting are scarce, and it remains unclear whether conventional continual learning (CL) methods are effective in continual offline RL (CORL) scenarios. In this study, we develop the Offline Continual World benchmark and demonstrate that traditional CL methods struggle with catastrophic forgetting, primarily due to the unique distribution shifts inherent to CORL scenarios. To address this challenge, we introduce CompoFormer, a structure-based continual transformer model that adaptively composes previous policies via a meta-policy network. Upon encountering a new task, CompoFormer leverages semantic correlations to selectively integrate relevant prior policies alongside newly trained parameters, thereby enhancing knowledge sharing and accelerating the learning process. Our experiments reveal that CompoFormer outperforms conventional CL methods, particularly in longer task sequences, showcasing a promising balance between plasticity and stability.
Task-Aware Harmony Multi-Task Decision Transformer for Offline Reinforcement Learning
Nov 02, 2024



The purpose of offline multi-task reinforcement learning (MTRL) is to develop a unified policy applicable to diverse tasks without the need for online environmental interaction. Recent advancements approach this through sequence modeling, leveraging the Transformer architecture's scalability and the benefits of parameter sharing to exploit task similarities. However, variations in task content and complexity pose significant challenges in policy formulation, necessitating judicious parameter sharing and management of conflicting gradients for optimal policy performance. Furthermore, identifying the optimal parameter subspace for each task often necessitates prior knowledge of the task identifier during inference, limiting applicability in real-world scenarios with variable task content and unknown current tasks. In this work, we introduce the Harmony Multi-Task Decision Transformer (HarmoDT), a novel solution designed to identify an optimal harmony subspace of parameters for each task. We formulate this as a bi-level optimization problem within a meta-learning framework, where the upper level learns masks to define the harmony subspace, while the inner level focuses on updating parameters to improve the overall performance of the unified policy. To eliminate the need for task identifiers, we further design a group-wise variant (G-HarmoDT) that clusters tasks into coherent groups based on gradient information, and utilizes a gating network to determine task identifiers during inference. Empirical evaluations across various benchmarks highlight the superiority of our approach, demonstrating its effectiveness in the multi-task context with specific improvements of 8% gain in task-provided settings, 5% in task-agnostic settings, and 10% in unseen settings.
Reconstruct the Pruned Model without Any Retraining
Jul 18, 2024Structured pruning is a promising hardware-friendly compression technique for large language models (LLMs), which is expected to be retraining-free to avoid the enormous retraining cost. This retraining-free paradigm involves (1) pruning criteria to define the architecture and (2) distortion reconstruction to restore performance. However, existing methods often emphasize pruning criteria while using reconstruction techniques that are specific to certain modules or criteria, resulting in limited generalizability. To address this, we introduce the Linear Interpolation-based Adaptive Reconstruction (LIAR) framework, which is both efficient and effective. LIAR does not require back-propagation or retraining and is compatible with various pruning criteria and modules. By applying linear interpolation to the preserved weights, LIAR minimizes reconstruction error and effectively reconstructs the pruned output. Our evaluations on benchmarks such as GLUE, SQuAD, WikiText, and common sense reasoning show that LIAR enables a BERT model to maintain 98% accuracy even after removing 50% of its parameters and achieves top performance for LLaMA in just a few minutes.
Federated Learning with Bilateral Curation for Partially Class-Disjoint Data
May 29, 2024Partially class-disjoint data (PCDD), a common yet under-explored data formation where each client contributes a part of classes (instead of all classes) of samples, severely challenges the performance of federated algorithms. Without full classes, the local objective will contradict the global objective, yielding the angle collapse problem for locally missing classes and the space waste problem for locally existing classes. As far as we know, none of the existing methods can intrinsically mitigate PCDD challenges to achieve holistic improvement in the bilateral views (both global view and local view) of federated learning. To address this dilemma, we are inspired by the strong generalization of simplex Equiangular Tight Frame~(ETF) on the imbalanced data, and propose a novel approach called FedGELA where the classifier is globally fixed as a simplex ETF while locally adapted to the personal distributions. Globally, FedGELA provides fair and equal discrimination for all classes and avoids inaccurate updates of the classifier, while locally it utilizes the space of locally missing classes for locally existing classes. We conduct extensive experiments on a range of datasets to demonstrate that our FedGELA achieves promising performance~(averaged improvement of 3.9% to FedAvg and 1.5% to best baselines) and provide both local and global convergence guarantees. Source code is available at:https://github.com/MediaBrain-SJTU/FedGELA.git.
Locally Estimated Global Perturbations are Better than Local Perturbations for Federated Sharpness-aware Minimization
May 29, 2024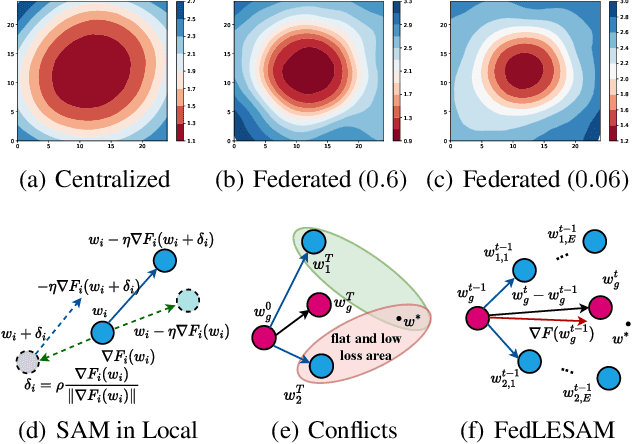



In federated learning (FL), the multi-step update and data heterogeneity among clients often lead to a loss landscape with sharper minima, degenerating the performance of the resulted global model. Prevalent federated approaches incorporate sharpness-aware minimization (SAM) into local training to mitigate this problem. However, the local loss landscapes may not accurately reflect the flatness of global loss landscape in heterogeneous environments; as a result, minimizing local sharpness and calculating perturbations on client data might not align the efficacy of SAM in FL with centralized training. To overcome this challenge, we propose FedLESAM, a novel algorithm that locally estimates the direction of global perturbation on client side as the difference between global models received in the previous active and current rounds. Besides the improved quality, FedLESAM also speed up federated SAM-based approaches since it only performs once backpropagation in each iteration. Theoretically, we prove a slightly tighter bound than its original FedSAM by ensuring consistent perturbation. Empirically, we conduct comprehensive experiments on four federated benchmark datasets under three partition strategies to demonstrate the superior performance and efficiency of FedLESAM.
Federated Learning under Partially Class-Disjoint Data via Manifold Reshaping
May 29, 2024Statistical heterogeneity severely limits the performance of federated learning (FL), motivating several explorations e.g., FedProx, MOON and FedDyn, to alleviate this problem. Despite effectiveness, their considered scenario generally requires samples from almost all classes during the local training of each client, although some covariate shifts may exist among clients. In fact, the natural case of partially class-disjoint data (PCDD), where each client contributes a few classes (instead of all classes) of samples, is practical yet underexplored. Specifically, the unique collapse and invasion characteristics of PCDD can induce the biased optimization direction in local training, which prevents the efficiency of federated learning. To address this dilemma, we propose a manifold reshaping approach called FedMR to calibrate the feature space of local training. Our FedMR adds two interplaying losses to the vanilla federated learning: one is intra-class loss to decorrelate feature dimensions for anti-collapse; and the other one is inter-class loss to guarantee the proper margin among categories in the feature expansion. We conduct extensive experiments on a range of datasets to demonstrate that our FedMR achieves much higher accuracy and better communication efficiency. Source code is available at: https://github.com/MediaBrain-SJTU/FedMR.git.