 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Coreference Alignment: Enabling Reliable Information Transfer in Omni-LLMs
Apr 07, 2026Omni Large Language Models (Omni-LLMs) have demonstrated impressive capabilities in holistic multi-modal perception, yet they consistently falter in complex scenarios requiring synergistic omni-modal reasoning. Beyond understanding global multimodal context, effective reasoning also hinges on fine-grained cross-modal alignment, especially identifying shared referents across modalities, yet this aspect has been largely overlooked. To bridge this gap, we formalize the challenge as a cross-modal coreference problem, where a model must localize a referent in a source modality and re-identify it in a target modality. Building on this paradigm, we introduce CrossOmni, a dataset comprising nine tasks equipped with human-designed reasoning rationales to evaluate and enhance this capability. Experiments on 13 Omni-LLMs reveal systematic weaknesses in cross-modal coreference, which we attribute to the absence of coreference-aware thinking patterns. To address this, we enhance cross-modal alignment via two strategies: a training-free In-Context Learning method and a training-based SFT+GRPO framework designed to induce such thinking patterns. Both approaches yield substantial performance gains and generalize effectively to collaborative reasoning tasks. Overall, our findings highlight cross-modal coreference as a crucial missing piece for advancing robust omni-modal reasoning.
Selecting Auxiliary Data via Neural Tangent Kernels for Low-Resource Domains
Nov 10, 2025Large language models (LLMs) have achieved remarkable success across widespread tasks, yet their application in low-resource domains remains a significant challenge due to data scarcity and the high risk of overfitting. While in-domain data is limited, there exist vast amounts of similar general-domain data, and our initial findings reveal that they could potentially serve as auxiliary supervision for domain enhancement. This observation leads us to our central research question: \textbf{\textit{how to effectively select the most valuable auxiliary data to maximize domain-specific performance}}, particularly when traditional methods are inapplicable due to a lack of large in-domain data pools or validation sets. To address this, we propose \textbf{NTK-Selector}, a principled and efficient framework for selecting general-domain auxiliary data to enhance domain-specific performance via neural tangent kernels (NTK). Our method tackles two challenges of directly applying NTK to LLMs, theoretical assumptions and prohibitive computational cost, by empirically demonstrating a stable NTK-like behavior in LLMs during LoRA fine-tuning and proposing a Jacobian-free approximation method. Extensive experiments across four low-resource domains (medical, financial, legal, and psychological) demonstrate that NTK-Selector consistently improves downstream performance. Specifically, fine-tuning on 1,000 in-domain samples alone only yielded +0.8 points for Llama3-8B-Instruct and +0.9 points for Qwen3-8B. In contrast, enriching with 9,000 auxiliary samples selected by NTK-Selector led to substantial \textbf{gains of +8.7 and +5.1 points}, which corresponds to a \textbf{10.9x and 5.7x improvement} over the domain-only setting.
Bridging the Dynamic Perception Gap: Training-Free Draft Chain-of-Thought for Dynamic Multimodal Spatial Reasoning
May 22, 2025While chains-of-thought (CoT) have advanced complex reasoning in multimodal large language models (MLLMs), existing methods remain confined to text or static visual domains, often faltering in dynamic spatial reasoning tasks. To bridge this gap, we present GRASSLAND, a novel maze navigation benchmark designed to evaluate dynamic spatial reasoning. Our experiments show that augmenting textual reasoning chains with dynamic visual drafts, overlaid on input images, significantly outperforms conventional approaches, offering new insights into spatial reasoning in evolving environments. To generalize this capability, we propose D2R (Dynamic Draft-Augmented Reasoning), a training-free framework that seamlessly integrates textual CoT with corresponding visual drafts into MLLMs. Extensive evaluations demonstrate that D2R consistently enhances performance across diverse tasks, establishing a robust baseline for dynamic spatial reasoning without requiring model fine-tuning. Project is open at https://github.com/Cratileo/D2R.
Combatting Dimensional Collapse in LLM Pre-Training Data via Diversified File Selection
Apr 29, 2025Selecting high-quality pre-training data for large language models (LLMs) is crucial for enhancing their overall performance under limited computation budget, improving both training and sample efficiency. Recent advancements in file selection primarily rely on using an existing or trained proxy model to assess the similarity of samples to a target domain, such as high quality sources BookCorpus and Wikipedia. However, upon revisiting these methods, the domain-similarity selection criteria demonstrates a diversity dilemma, i.e.dimensional collapse in the feature space, improving performance on the domain-related tasks but causing severe degradation on generic performance. To prevent collapse and enhance diversity, we propose a DiverSified File selection algorithm (DiSF), which selects the most decorrelated text files in the feature space. We approach this with a classical greedy algorithm to achieve more uniform eigenvalues in the feature covariance matrix of the selected texts, analyzing its approximation to the optimal solution under a formulation of $\gamma$-weakly submodular optimization problem. Empirically, we establish a benchmark and conduct extensive experiments on the TinyLlama architecture with models from 120M to 1.1B parameters. Evaluating across nine tasks from the Harness framework, DiSF demonstrates a significant improvement on overall performance. Specifically, DiSF saves 98.5% of 590M training files in SlimPajama, outperforming the full-data pre-training within a 50B training budget, and achieving about 1.5x training efficiency and 5x data efficiency.
DSVD: Dynamic Self-Verify Decoding for Faithful Generation in Large Language Models
Mar 05, 2025The reliability of large language models remains a critical challenge, particularly due to their susceptibility to hallucinations and factual inaccuracies during text generation. Existing solutions either underutilize models' self-correction with preemptive strategies or use costly post-hoc verification. To further explore the potential of real-time self-verification and correction, we present Dynamic Self-Verify Decoding (DSVD), a novel decoding framework that enhances generation reliability through real-time hallucination detection and efficient error correction. DSVD integrates two key components: (1) parallel self-verification architecture for continuous quality assessment, (2) dynamic rollback mechanism for targeted error recovery. Extensive experiments across five benchmarks demonstrate DSVD's effectiveness, achieving significant improvement in truthfulness (Quesetion-Answering) and factual accuracy (FActScore). Results show the DSVD can be further incorporated with existing faithful decoding methods to achieve stronger performance. Our work establishes that real-time self-verification during generation offers a viable path toward more trustworthy language models without sacrificing practical deployability.
Towards Omni-RAG: Comprehensive Retrieval-Augmented Generation for Large Language Models in Medical Applications
Jan 05, 2025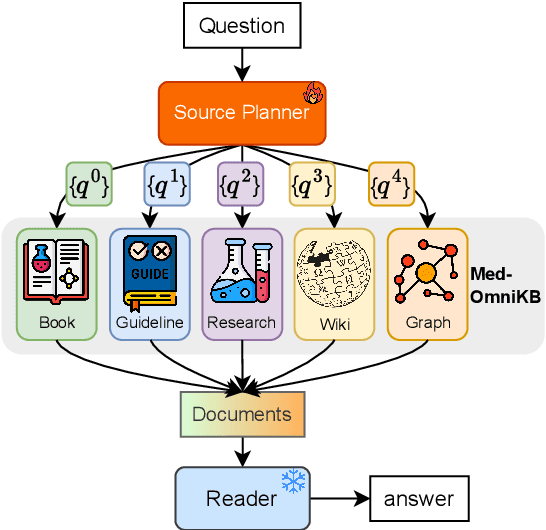
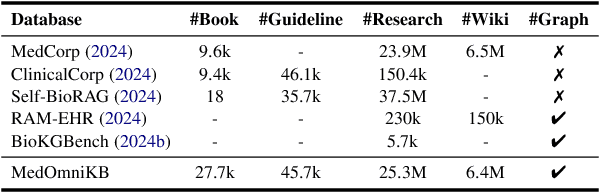
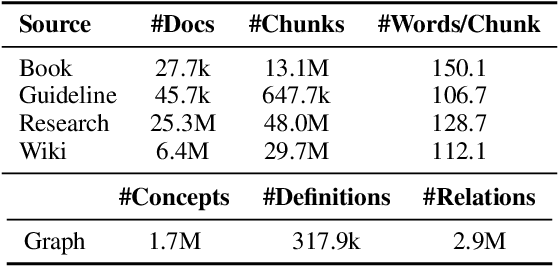
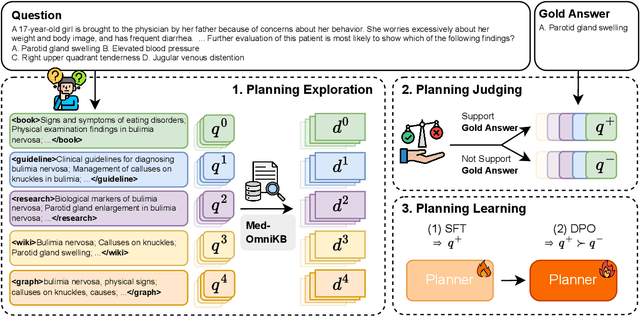
Large language models (LLMs) hold promise for addressing healthcare challenges but often generate hallucinations due to limited integration of medical knowledge. Incorporating external medical knowledge is therefore critical, especially considering the breadth and complexity of medical content, which necessitates effective multi-source knowledge acquisition. We address this challenge by framing it as a source planning problem, where the task is to formulate context-appropriate queries tailored to the attributes of diverse knowledge sources. Existing approaches either overlook source planning or fail to achieve it effectively due to misalignment between the model's expectation of the sources and their actual content. To bridge this gap, we present MedOmniKB, a comprehensive repository comprising multigenre and multi-structured medical knowledge sources. Leveraging these sources, we propose the Source Planning Optimisation (SPO) method, which enhances multi-source utilisation through explicit planning optimisation. Our approach involves enabling an expert model to explore and evaluate potential plans while training a smaller model to learn source alignment using positive and negative planning samples. Experimental results demonstrate that our method substantially improves multi-source planning performance, enabling the optimised small model to achieve state-of-the-art results in leveraging diverse medical knowledge sources.
AuscultaBase: A Foundational Step Towards AI-Powered Body Sound Diagnostics
Nov 12, 2024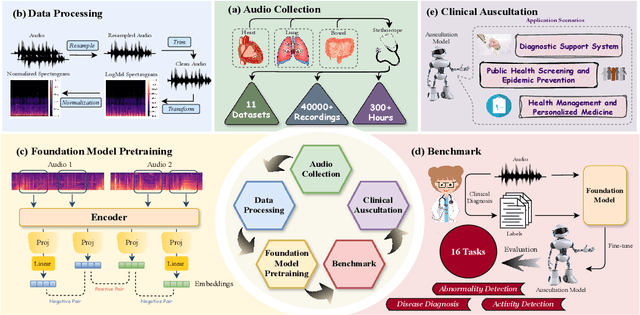
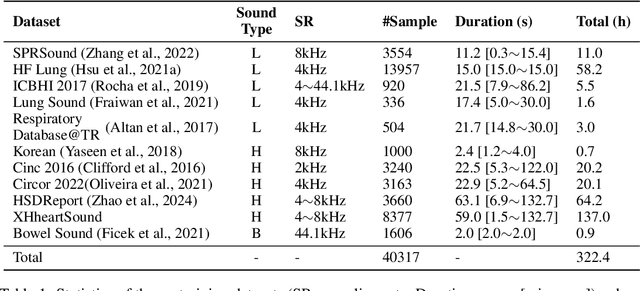
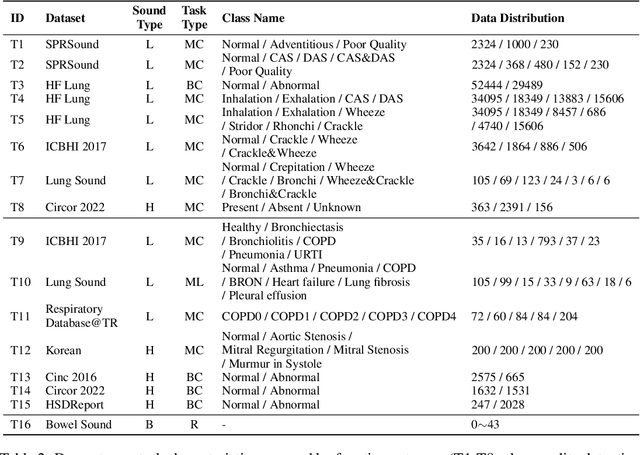
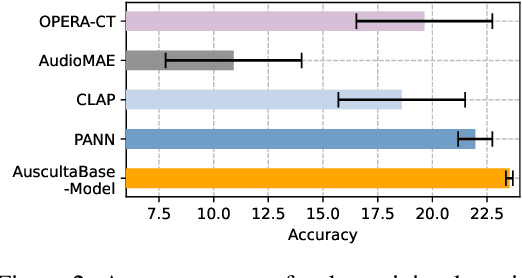
Auscultation of internal body sounds is essential for diagnosing a range of health conditions, yet its effectiveness is often limited by clinicians' expertise and the acoustic constraints of human hearing, restricting its use across various clinical scenarios. To address these challenges, we introduce AuscultaBase, a foundational framework aimed at advancing body sound diagnostics through innovative data integration and contrastive learning techniques. Our contributions include the following: First, we compile AuscultaBase-Corpus, a large-scale, multi-source body sound database encompassing 11 datasets with 40,317 audio recordings and totaling 322.4 hours of heart, lung, and bowel sounds. Second, we develop AuscultaBase-Model, a foundational diagnostic model for body sounds, utilizing contrastive learning on the compiled corpus. Third, we establish AuscultaBase-Bench, a comprehensive benchmark containing 16 sub-tasks, assessing the performance of various open-source acoustic pre-trained models. Evaluation results indicate that our model outperforms all other open-source models in 12 out of 16 tasks, demonstrating the efficacy of our approach in advancing diagnostic capabilities for body sound analysis.
HSDreport: Heart Sound Diagnosis with Echocardiography Reports
Aug 16, 2024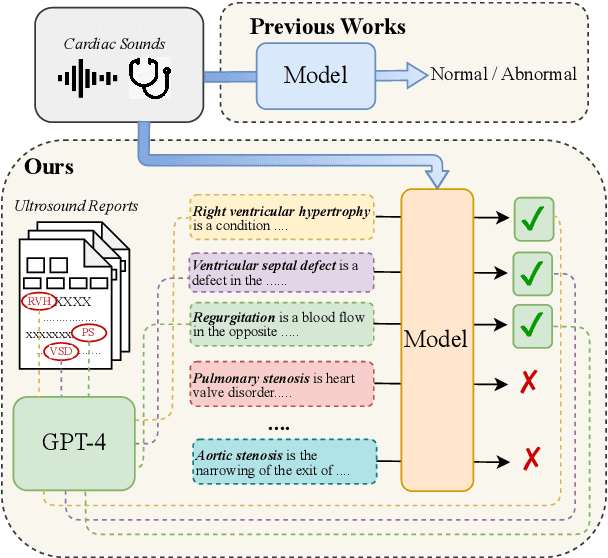
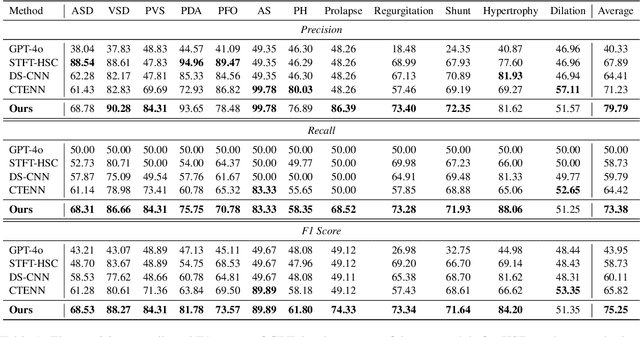
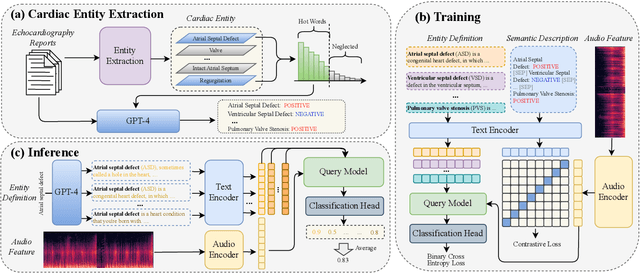

Heart sound auscultation holds significant importance in the diagnosis of congenital heart disease. However, existing methods for Heart Sound Diagnosis (HSD) tasks are predominantly limited to a few fixed categories, framing the HSD task as a rigid classification problem that does not fully align with medical practice and offers only limited information to physicians. Besides, such methods do not utilize echocardiography reports, the gold standard in the diagnosis of related diseases. To tackle this challenge, we introduce HSDreport, a new benchmark for HSD, which mandates the direct utilization of heart sounds obtained from auscultation to predict echocardiography reports. This benchmark aims to merge the convenience of auscultation with the comprehensive nature of echocardiography reports. First, we collect a new dataset for this benchmark, comprising 2,275 heart sound samples along with their corresponding reports. Subsequently, we develop a knowledge-aware query-based transformer to handle this task. The intent is to leverage the capabilities of medically pre-trained models and the internal knowledge of large language models (LLMs) to address the task's inherent complexity and variability, thereby enhancing the robustness and scientific validity of the method. Furthermore, our experimental results indicate that our method significantly outperforms traditional HSD approaches and existing multimodal LLMs in detecting key abnormalities in heart sounds.
Reconstruct the Pruned Model without Any Retraining
Jul 18, 2024Structured pruning is a promising hardware-friendly compression technique for large language models (LLMs), which is expected to be retraining-free to avoid the enormous retraining cost. This retraining-free paradigm involves (1) pruning criteria to define the architecture and (2) distortion reconstruction to restore performance. However, existing methods often emphasize pruning criteria while using reconstruction techniques that are specific to certain modules or criteria, resulting in limited generalizability. To address this, we introduce the Linear Interpolation-based Adaptive Reconstruction (LIAR) framework, which is both efficient and effective. LIAR does not require back-propagation or retraining and is compatible with various pruning criteria and modules. By applying linear interpolation to the preserved weights, LIAR minimizes reconstruction error and effectively reconstructs the pruned output. Our evaluations on benchmarks such as GLUE, SQuAD, WikiText, and common sense reasoning show that LIAR enables a BERT model to maintain 98% accuracy even after removing 50% of its parameters and achieves top performance for LLaMA in just a few minutes.
M2K-VDG: Model-Adaptive Multimodal Knowledge Anchor Enhanced Video-grounded Dialogue Generation
Feb 19, 2024
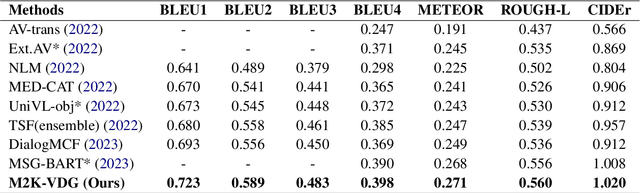
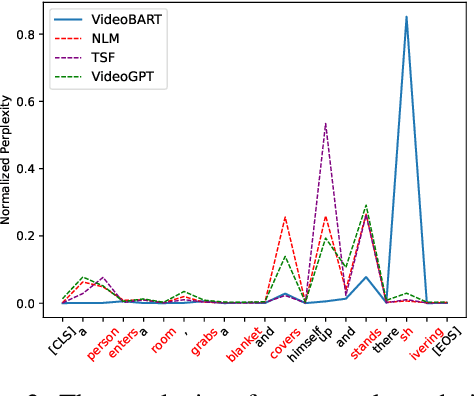
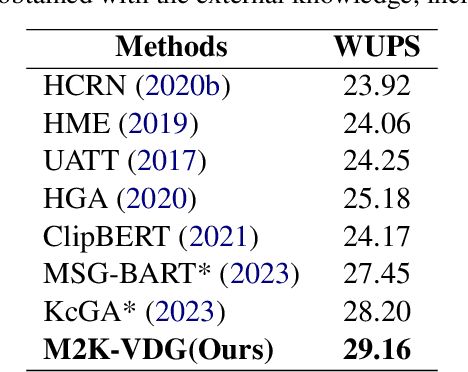
Video-grounded dialogue generation (VDG) requires the system to generate a fluent and accurate answer based on multimodal knowledge. However, the difficulty in multimodal knowledge utilization brings serious hallucinations to VDG models in practice. Although previous works mitigate the hallucination in a variety of ways, they hardly take notice of the importance of the multimodal knowledge anchor answer tokens. In this paper, we reveal via perplexity that different VDG models experience varying hallucinations and exhibit diverse anchor tokens. Based on this observation, we propose M2K-VDG, a model-adaptive multimodal knowledge anchor enhancement framework for hallucination reduction. Furthermore, we introduce the counterfactual effect for more accurate anchor token detection. The experimental results on three popular benchmarks exhibit the superiority of our approach over state-of-the-art methods, demonstrating its effectiveness in reducing hallucinations.