 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2K-VDG: Model-Adaptive Multimodal Knowledge Anchor Enhanced Video-grounded Dialogue Generation
Paper and Code

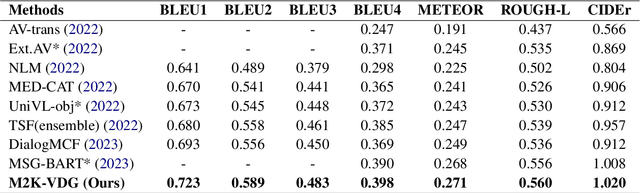
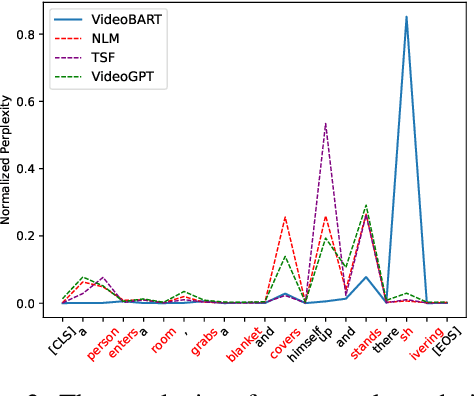
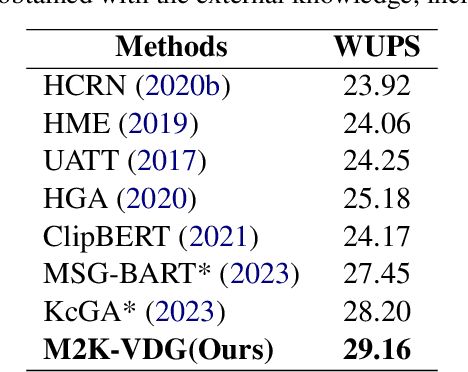
Video-grounded dialogue generation (VDG) requires the system to generate a fluent and accurate answer based on multimodal knowledge. However, the difficulty in multimodal knowledge utilization brings serious hallucinations to VDG models in practice. Although previous works mitigate the hallucination in a variety of ways, they hardly take notice of the importance of the multimodal knowledge anchor answer tokens. In this paper, we reveal via perplexity that different VDG models experience varying hallucinations and exhibit diverse anchor tokens. Based on this observation, we propose M2K-VDG, a model-adaptive multimodal knowledge anchor enhancement framework for hallucination reduction. Furthermore, we introduce the counterfactual effect for more accurate anchor token detection. The experimental results on three popular benchmarks exhibit the superiority of our approach over state-of-the-art methods, demonstrating its effectiveness in reducing hallucinations.