 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVocalBench-zh: Decomposing and Benchmarking the Speech Conversational Abilities in Mandarin Context
Nov 17, 2025



The development of multi-modal large language models (LLMs) leads to intelligent approaches capable of speech interactions. As one of the most widely spoken languages globally, Mandarin is supported by most models to enhance their applicability and reach. However, the scarcity of comprehensive speech-to-speech (S2S) benchmarks in Mandarin contexts impedes systematic evaluation for developers and hinders fair model comparison for users. In this work, we propose VocalBench-zh, an ability-level divided evaluation suite adapted to Mandarin context consisting of 10 well-crafted subsets and over 10K high-quality instances, covering 12 user-oriented characters. The evaluation experiment on 14 mainstream models reveals the common challenges for current routes, and highlights the need for new insights into next-generation speech interactive systems. The evaluation codes and datasets will be available at https://github.com/SJTU-OmniAgent/VocalBench-zh.
Selecting Auxiliary Data via Neural Tangent Kernels for Low-Resource Domains
Nov 10, 2025Large language models (LLMs) have achieved remarkable success across widespread tasks, yet their application in low-resource domains remains a significant challenge due to data scarcity and the high risk of overfitting. While in-domain data is limited, there exist vast amounts of similar general-domain data, and our initial findings reveal that they could potentially serve as auxiliary supervision for domain enhancement. This observation leads us to our central research question: \textbf{\textit{how to effectively select the most valuable auxiliary data to maximize domain-specific performance}}, particularly when traditional methods are inapplicable due to a lack of large in-domain data pools or validation sets. To address this, we propose \textbf{NTK-Selector}, a principled and efficient framework for selecting general-domain auxiliary data to enhance domain-specific performance via neural tangent kernels (NTK). Our method tackles two challenges of directly applying NTK to LLMs, theoretical assumptions and prohibitive computational cost, by empirically demonstrating a stable NTK-like behavior in LLMs during LoRA fine-tuning and proposing a Jacobian-free approximation method. Extensive experiments across four low-resource domains (medical, financial, legal, and psychological) demonstrate that NTK-Selector consistently improves downstream performance. Specifically, fine-tuning on 1,000 in-domain samples alone only yielded +0.8 points for Llama3-8B-Instruct and +0.9 points for Qwen3-8B. In contrast, enriching with 9,000 auxiliary samples selected by NTK-Selector led to substantial \textbf{gains of +8.7 and +5.1 points}, which corresponds to a \textbf{10.9x and 5.7x improvement} over the domain-only setting.
Bridging the Dynamic Perception Gap: Training-Free Draft Chain-of-Thought for Dynamic Multimodal Spatial Reasoning
May 22, 2025While chains-of-thought (CoT) have advanced complex reasoning in multimodal large language models (MLLMs), existing methods remain confined to text or static visual domains, often faltering in dynamic spatial reasoning tasks. To bridge this gap, we present GRASSLAND, a novel maze navigation benchmark designed to evaluate dynamic spatial reasoning. Our experiments show that augmenting textual reasoning chains with dynamic visual drafts, overlaid on input images, significantly outperforms conventional approaches, offering new insights into spatial reasoning in evolving environments. To generalize this capability, we propose D2R (Dynamic Draft-Augmented Reasoning), a training-free framework that seamlessly integrates textual CoT with corresponding visual drafts into MLLMs. Extensive evaluations demonstrate that D2R consistently enhances performance across diverse tasks, establishing a robust baseline for dynamic spatial reasoning without requiring model fine-tuning. Project is open at https://github.com/Cratileo/D2R.
Drawing the Line: Enhancing Trustworthiness of MLLMs Through the Power of Refusal
Dec 15, 2024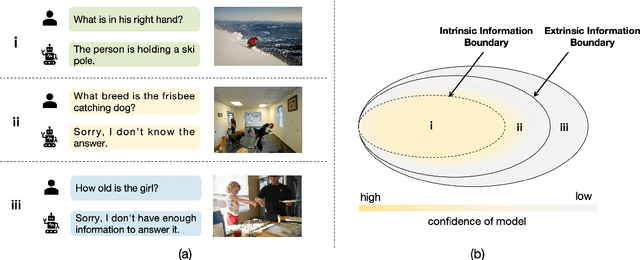
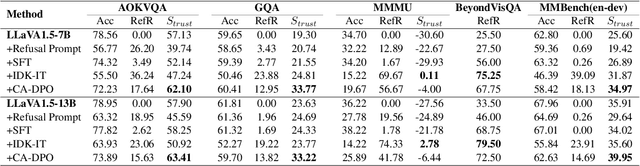
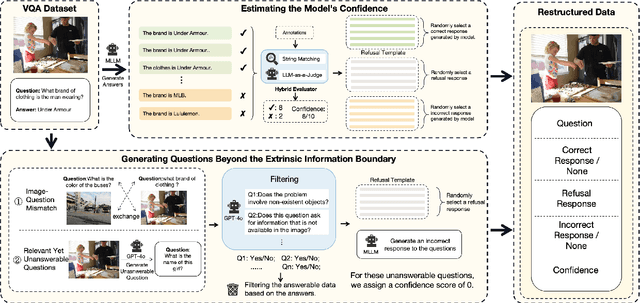
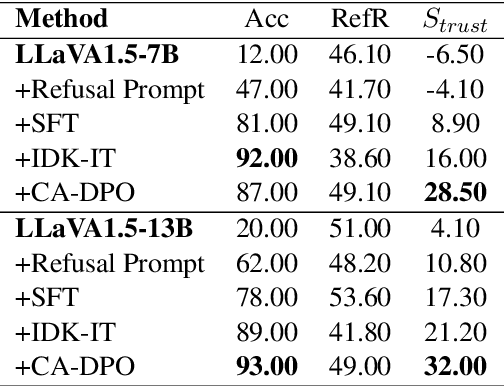
Multimodal large language models (MLLMs) excel at multimodal perception and understanding, yet their tendency to generate hallucinated or inaccurate responses undermines their trustworthiness. Existing methods have largely overlooked the importance of refusal responses as a means of enhancing MLLMs reliability. To bridge this gap, we present the Information Boundary-aware Learning Framework (InBoL), a novel approach that empowers MLLMs to refuse to answer user queries when encountering insufficient information. To the best of our knowledge, InBoL is the first framework that systematically defines the conditions under which refusal is appropriate for MLLMs using the concept of information boundaries proposed in our paper. This framework introduces a comprehensive data generation pipeline and tailored training strategies to improve the model's ability to deliver appropriate refusal responses. To evaluate the trustworthiness of MLLMs, we further propose a user-centric alignment goal along with corresponding metrics. Experimental results demonstrate a significant improvement in refusal accuracy without noticeably compromising the model's helpfulness, establishing InBoL as a pivotal advancement in building more trustworthy MLLMs.
Med-PMC: Medical Personalized Multi-modal Consultation with a Proactive Ask-First-Observe-Next Paradigm
Aug 16, 2024



The application of the Multi-modal Large Language Models (MLLMs) in medical clinical scenarios remains underexplored. Previous benchmarks only focus on the capacity of the MLLMs in medical visual question-answering (VQA) or report generation and fail to assess the performance of the MLLMs on complex clinical multi-modal tasks. In this paper, we propose a novel Medical Personalized Multi-modal Consultation (Med-PMC) paradigm to evaluate the clinical capacity of the MLLMs. Med-PMC builds a simulated clinical environment where the MLLMs are required to interact with a patient simulator to complete the multi-modal information-gathering and decision-making task. Specifically, the patient simulator is decorated with personalized actors to simulate diverse patients in real scenarios. We conduct extensive experiments to access 12 types of MLLMs, providing a comprehensive view of the MLLMs' clinical performance. We found that current MLLMs fail to gather multimodal information and show potential bias in the decision-making task when consulted with the personalized patient simulators. Further analysis demonstrates the effectiveness of Med-PMC, showing the potential to guide the development of robust and reliable clinical MLLMs. Code and data are available at https://github.com/LiuHC0428/Med-PMC.
Decoding Linguistic Representations of Human Brain
Jul 30, 2024



Language, as an information medium created by advanced organisms, has always been a concern of neuroscience regarding how it is represented in the brain. Decoding linguistic representations in the evoked brain has shown groundbreaking achievements, thanks to the rapid improvement of neuroimaging, medical technology, life sciences and artificial intelligence. In this work, we present a taxonomy of brain-to-language decoding of both textual and speech formats. This work integrates two types of research: neuroscience focusing on language understanding and deep learning-based brain decoding. Generating discernible language information from brain activity could not only help those with limited articulation, especially amyotrophic lateral sclerosis (ALS) patients but also open up a new way for the next generation's brain-computer interface (BCI). This article will help brain scientists and deep-learning researchers to gain a bird's eye view of fine-grained language perception, and thus facilitate their further investigation and research of neural process and language decoding.
Stochastic First-Order Methods with Non-smooth and Non-Euclidean Proximal Terms for Nonconvex High-Dimensional Stochastic Optimization
Jun 27, 2024When the nonconvex problem is complicated by stochasticity, the sample complexity of stochastic first-order methods may depend linearly on the problem dimension, which is undesirable for large-scale problems. In this work, we propose dimension-insensitive stochastic first-order methods (DISFOMs) to address nonconvex optimization with expected-valued objective function. Our algorithms allow for non-Euclidean and non-smooth distance functions as the proximal terms. Under mild assumptions, we show that DISFOM using minibatches to estimate the gradient enjoys sample complexity of $ \mathcal{O} ( (\log d) / \epsilon^4 ) $ to obtain an $\epsilon$-stationary point. Furthermore, we prove that DISFOM employing variance reduction can sharpen this bound to $\mathcal{O} ( (\log d)^{2/3}/\epsilon^{10/3} )$, which perhaps leads to the best-known sample complexity result in terms of $d$. We provide two choices of the non-smooth distance functions, both of which allow for closed-form solutions to the proximal step. Numerical experiments are conducted to illustrate the dimension insensitive property of the proposed frameworks.
M$^3$AV: A Multimodal, Multigenre, and Multipurpose Audio-Visual Academic Lecture Dataset
Mar 21, 2024Publishing open-source academic video recordings is an emergent and prevalent approach to sharing knowledge online. Such videos carry rich multimodal information including speech, the facial and body movements of the speakers, as well as the texts and pictures in the slides and possibly even the papers. Although multiple academic video datasets have been constructed and released, few of them support both multimodal content recognition and understanding tasks, which is partially due to the lack of high-quality human annotations. In this paper, we propose a novel multimodal, multigenre, and multipurpose audio-visual academic lecture dataset (M$^3$AV), which has almost 367 hours of videos from five sources covering computer science, mathematics, and medical and biology topics. With high-quality human annotations of the spoken and written words, in particular high-valued name entities, the dataset can be used for multiple audio-visual recognition and understanding tasks. Evaluations performed on contextual speech recognition, speech synthesis, and slide and script generation tasks demonstrate that the diversity of M$^3$AV makes it a challenging dataset.
Automatic Interactive Evaluation for Large Language Models with State Aware Patient Simulator
Mar 14, 2024



Large Language Models (LLMs) have demonstrated remarkable proficiency in human interactions, yet their application within the medical field remains insufficiently explored. Previous works mainly focus on the performance of medical knowledge with examinations, which is far from the realistic scenarios, falling short in assessing the abilities of LLMs on clinical tasks. In the quest to enhance the application of Large Language Models (LLMs) in healthcare, this paper introduces the Automated Interactive Evaluation (AIE) framework and the State-Aware Patient Simulator (SAPS), targeting the gap between traditional LLM evaluations and the nuanced demands of clinical practice. Unlike prior methods that rely on static medical knowledge assessments, AIE and SAPS provide a dynamic, realistic platform for assessing LLMs through multi-turn doctor-patient simulations. This approach offers a closer approximation to real clinical scenarios and allows for a detailed analysis of LLM behaviors in response to complex patient interactions. Our extensive experimental validation demonstrates the effectiveness of the AIE framework, with outcomes that align well with human evaluations, underscoring its potential to revolutionize medical LLM testing for improved healthcare delivery.
M2K-VDG: Model-Adaptive Multimodal Knowledge Anchor Enhanced Video-grounded Dialogue Generation
Feb 19, 2024
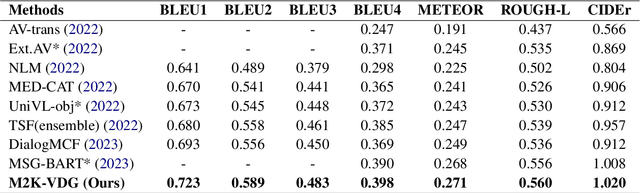
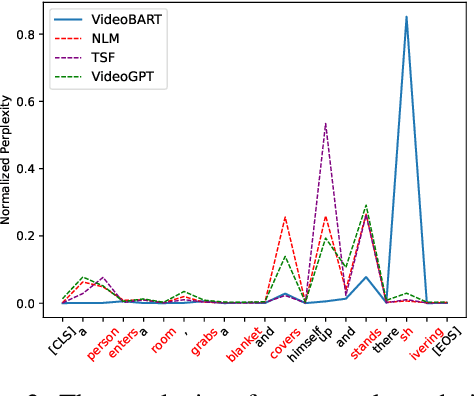
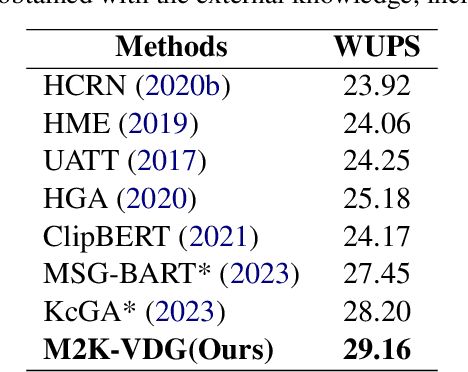
Video-grounded dialogue generation (VDG) requires the system to generate a fluent and accurate answer based on multimodal knowledge. However, the difficulty in multimodal knowledge utilization brings serious hallucinations to VDG models in practice. Although previous works mitigate the hallucination in a variety of ways, they hardly take notice of the importance of the multimodal knowledge anchor answer tokens. In this paper, we reveal via perplexity that different VDG models experience varying hallucinations and exhibit diverse anchor tokens. Based on this observation, we propose M2K-VDG, a model-adaptive multimodal knowledge anchor enhancement framework for hallucination reduction. Furthermore, we introduce the counterfactual effect for more accurate anchor token detection. The experimental results on three popular benchmarks exhibit the superiority of our approach over state-of-the-art methods, demonstrating its effectiveness in reducing hallucinations.