 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHSDreport: Heart Sound Diagnosis with Echocardiography Reports
Paper and Code
Aug 16, 2024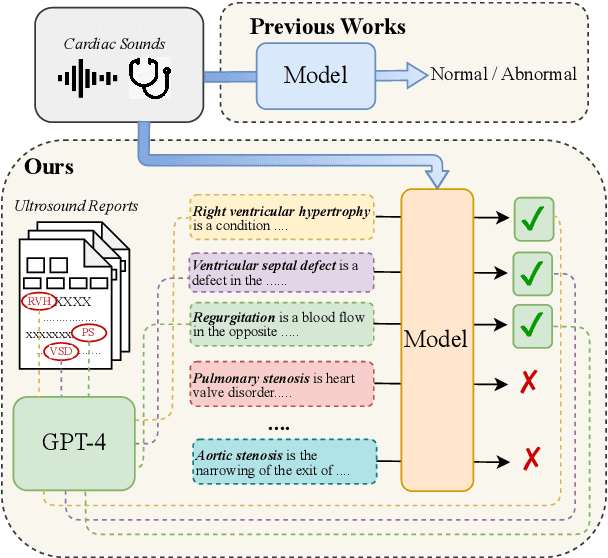
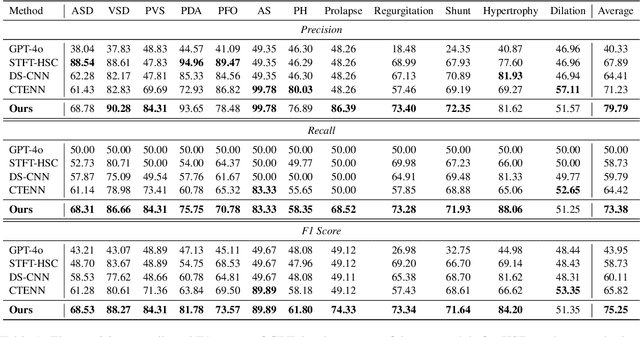
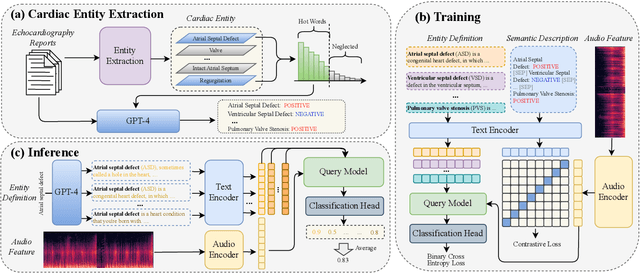

Heart sound auscultation holds significant importance in the diagnosis of congenital heart disease. However, existing methods for Heart Sound Diagnosis (HSD) tasks are predominantly limited to a few fixed categories, framing the HSD task as a rigid classification problem that does not fully align with medical practice and offers only limited information to physicians. Besides, such methods do not utilize echocardiography reports, the gold standard in the diagnosis of related diseases. To tackle this challenge, we introduce HSDreport, a new benchmark for HSD, which mandates the direct utilization of heart sounds obtained from auscultation to predict echocardiography reports. This benchmark aims to merge the convenience of auscultation with the comprehensive nature of echocardiography reports. First, we collect a new dataset for this benchmark, comprising 2,275 heart sound samples along with their corresponding reports. Subsequently, we develop a knowledge-aware query-based transformer to handle this task. The intent is to leverage the capabilities of medically pre-trained models and the internal knowledge of large language models (LLMs) to address the task's inherent complexity and variability, thereby enhancing the robustness and scientific validity of the method. Furthermore, our experimental results indicate that our method significantly outperforms traditional HSD approaches and existing multimodal LLMs in detecting key abnormalities in heart sounds.