 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolMem: A Cognitive-Driven Benchmark for Multi-Session Dialogue Memory
Jan 07, 2026Despite recent advances in understanding and leveraging long-range conversational memory, existing benchmarks still lack systematic evaluation of large language models(LLMs) across diverse memory dimensions, particularly in multi-session settings. In this work, we propose EvolMem, a new benchmark for assessing multi-session memory capabilities of LLMs and agent systems. EvolMem is grounded in cognitive psychology and encompasses both declarative and non-declarative memory, further decomposed into multiple fine-grained abilities. To construct the benchmark, we introduce a hybrid data synthesis framework that consists of topic-initiated generation and narrative-inspired transformations. This framework enables scalable generation of multi-session conversations with controllable complexity, accompanied by sample-specific evaluation guidelines. Extensive evaluation reveals that no LLM consistently outperforms others across all memory dimensions. Moreover, agent memory mechanisms do not necessarily enhance LLMs' capabilities and often exhibit notable efficiency limitations. Data and code will be released at https://github.com/shenye7436/EvolMem.
Towards Omni-RAG: Comprehensive Retrieval-Augmented Generation for Large Language Models in Medical Applications
Jan 05, 2025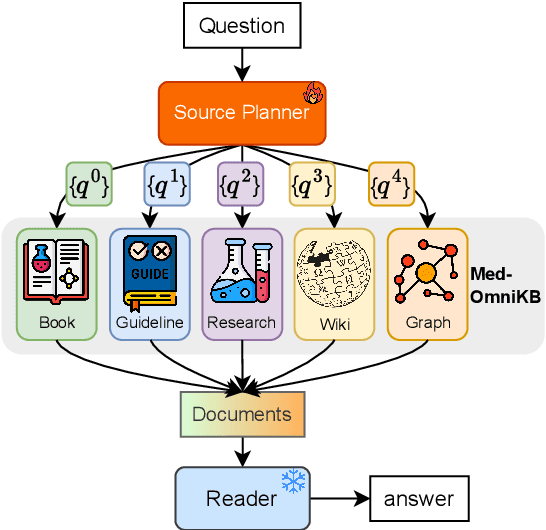
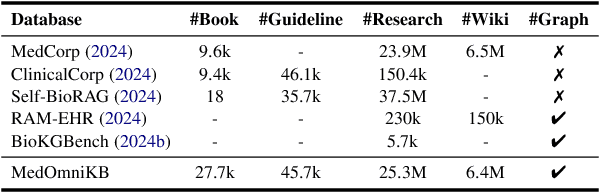
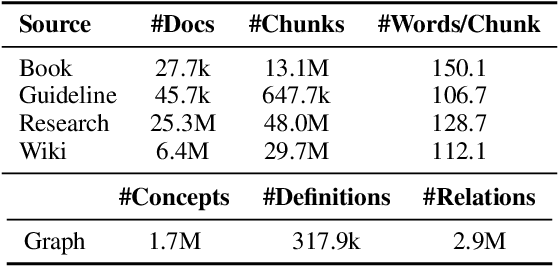
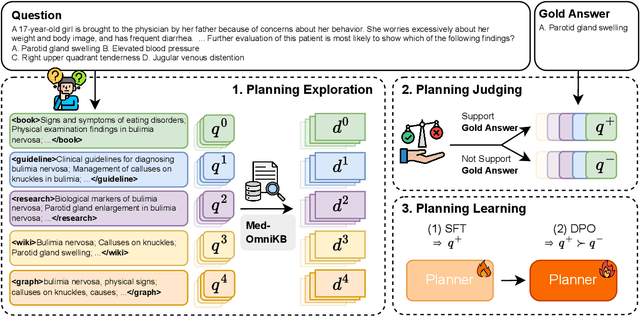
Large language models (LLMs) hold promise for addressing healthcare challenges but often generate hallucinations due to limited integration of medical knowledge. Incorporating external medical knowledge is therefore critical, especially considering the breadth and complexity of medical content, which necessitates effective multi-source knowledge acquisition. We address this challenge by framing it as a source planning problem, where the task is to formulate context-appropriate queries tailored to the attributes of diverse knowledge sources. Existing approaches either overlook source planning or fail to achieve it effectively due to misalignment between the model's expectation of the sources and their actual content. To bridge this gap, we present MedOmniKB, a comprehensive repository comprising multigenre and multi-structured medical knowledge sources. Leveraging these sources, we propose the Source Planning Optimisation (SPO) method, which enhances multi-source utilisation through explicit planning optimisation. Our approach involves enabling an expert model to explore and evaluate potential plans while training a smaller model to learn source alignment using positive and negative planning samples. Experimental results demonstrate that our method substantially improves multi-source planning performance, enabling the optimised small model to achieve state-of-the-art results in leveraging diverse medical knowledge sources.