 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Agnostic Robust Representation Learning
Mar 15, 2022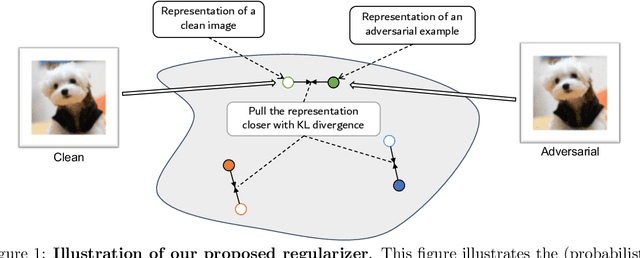
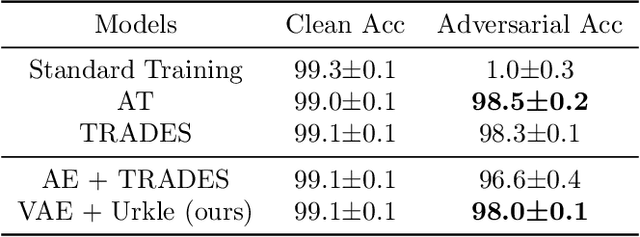

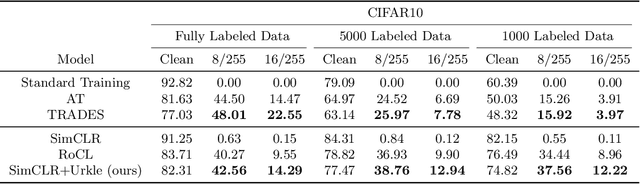
It has been reported that deep learning models are extremely vulnerable to small but intentionally chosen perturbations of its input. In particular, a deep network, despite its near-optimal accuracy on the clean images, often mis-classifies an image with a worst-case but humanly imperceptible perturbation (so-called adversarial examples). To tackle this problem, a great amount of research has been done to study the training procedure of a network to improve its robustness. However, most of the research so far has focused on the case of supervised learning. With the increasing popularity of self-supervised learning methods, it is also important to study and improve the robustness of their resulting representation on the downstream tasks. In this paper, we study the problem of robust representation learning with unlabeled data in a task-agnostic manner. Specifically, we first derive an upper bound on the adversarial loss of a prediction model (which is based on the learned representation) on any downstream task, using its loss on the clean data and a robustness regularizer. Moreover, the regularizer is task-independent, thus we propose to minimize it directly during the representation learning phase to make the downstream prediction model more robust. Extensive experiments show that our method achieves preferable adversarial performance compared to relevant baselines.
Offline Neural Contextual Bandits: Pessimism, Optimization and Generalization
Nov 27, 2021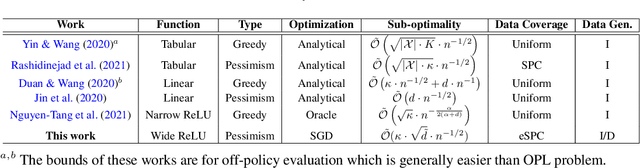
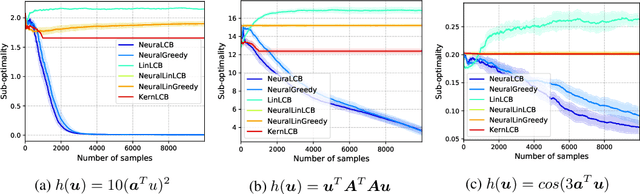
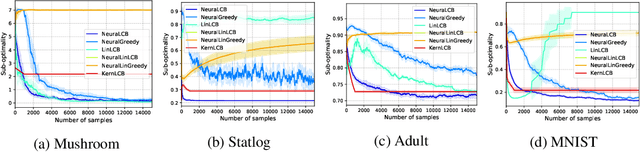

Offline policy learning (OPL) leverages existing data collected a priori for policy optimization without any active exploration. Despite the prevalence and recent interest in this problem, its theoretical and algorithmic foundations in function approximation settings remain under-developed. In this paper, we consider this problem on the axes of distributional shift, optimization, and generalization in offline contextual bandits with neural networks. In particular, we propose a provably efficient offline contextual bandit with neural network function approximation that does not require any functional assumption on the reward. We show that our method provably generalizes over unseen contexts under a milder condition for distributional shift than the existing OPL works. Notably, unlike any other OPL method, our method learns from the offline data in an online manner using stochastic gradient descent, allowing us to leverage the benefits of online learning into an offline setting. Moreover, we show that our method is more computationally efficient and has a better dependence on the effective dimension of the neural network than an online counterpart. Finally, we demonstrate the empirical effectiveness of our method in a range of synthetic and real-world OPL problems.
KL Guided Domain Adaptation
Jun 14, 2021
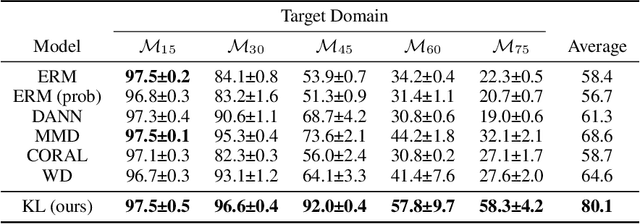

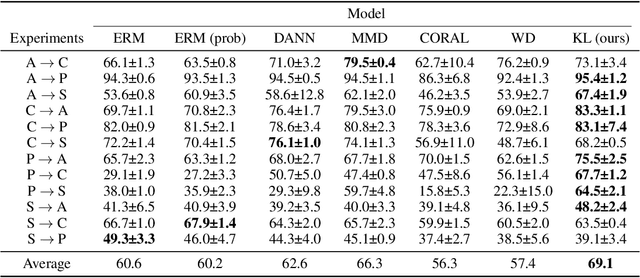
Domain adaptation is an important problem and often needed for real-world applications. In this problem, instead of i.i.d. datapoints, we assume that the source (training) data and the target (testing) data have different distributions. With that setting, the empirical risk minimization training procedure often does not perform well, since it does not account for the change in the distribution. A common approach in the domain adaptation literature is to learn a representation of the input that has the same distributions over the source and the target domain. However, these approaches often require additional networks and/or optimizing an adversarial (minimax) objective, which can be very expensive or unstable in practice. To tackle this problem, we first derive a generalization bound for the target loss based on the training loss and the reverse Kullback-Leibler (KL) divergence between the source and the target representation distributions. Based on this bound, we derive an algorithm that minimizes the KL term to obtain a better generalization to the target domain. We show that with a probabilistic representation network, the KL term can be estimated efficiently via minibatch samples without any additional network or a minimax objective. This leads to a theoretically sound alignment method which is also very efficient and stable in practice. Experimental results also suggest that our method outperforms other representation-alignment approaches.
Domain Invariant Representation Learning with Domain Density Transformations
Feb 14, 2021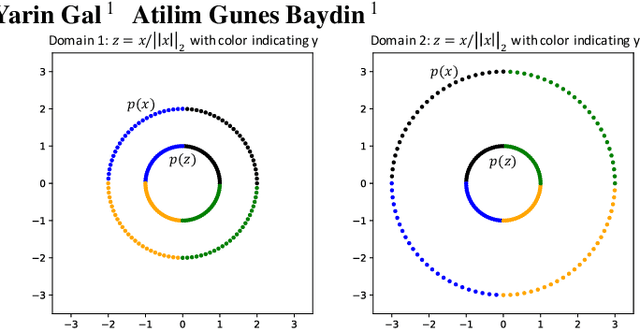
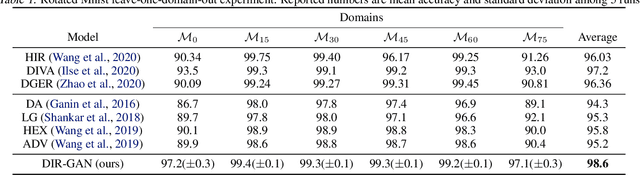
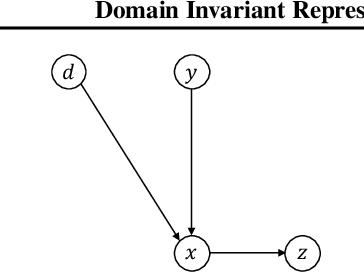
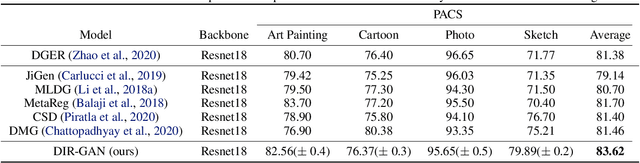
Domain generalization refers to the problem where we aim to train a model on data from a set of source domains so that the model can generalize to unseen target domains. Naively training a model on the aggregate set of data (pooled from all source domains) has been shown to perform suboptimally, since the information learned by that model might be domain-specific and generalize imperfectly to target domains. To tackle this problem, a predominant approach is to find and learn some domain-invariant information in order to use it for the prediction task. In this paper, we propose a theoretically grounded method to learn a domain-invariant representation by enforcing the representation network to be invariant under all transformation functions among domains. We also show how to use generative adversarial networks to learn such domain transformations to implement our method in practice. We demonstrate the effectiveness of our method on several widely used datasets for the domain generalization problem, on all of which we achieve competitive results with state-of-the-art models.