 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSViewFusion: Few-Shots View Generation of Novel Objects
Mar 13, 2024



Novel view synthesis has observed tremendous developments since the arrival of NeRFs. However, Nerf models overfit on a single scene, lacking generalization to out of distribution objects. Recently, diffusion models have exhibited remarkable performance on introducing generalization in view synthesis. Inspired by these advancements, we explore the capabilities of a pretrained stable diffusion model for view synthesis without explicit 3D priors. Specifically, we base our method on a personalized text to image model, Dreambooth, given its strong ability to adapt to specific novel objects with a few shots. Our research reveals two interesting findings. First, we observe that Dreambooth can learn the high level concept of a view, compared to arguably more complex strategies which involve finetuning diffusions on large amounts of multi-view data. Second, we establish that the concept of a view can be disentangled and transferred to a novel object irrespective of the original object's identify from which the views are learnt. Motivated by this, we introduce a learning strategy, FSViewFusion, which inherits a specific view through only one image sample of a single scene, and transfers the knowledge to a novel object, learnt from few shots, using low rank adapters. Through extensive experiments we demonstrate that our method, albeit simple, is efficient in generating reliable view samples for in the wild images. Code and models will be released.
Prompting classes: Exploring the Power of Prompt Class Learning in Weakly Supervised Semantic Segmentation
Jul 08, 2023Recently, CLIP-based approaches have exhibited remarkable performance on generalization and few-shot learning tasks, fueled by the power of contrastive language-vision pre-training. In particular, prompt tuning has emerged as an effective strategy to adapt the pre-trained language-vision models to downstream tasks by employing task-related textual tokens. Motivated by this progress, in this work we question whether other fundamental problems, such as weakly supervised semantic segmentation (WSSS), can benefit from prompt tuning. Our findings reveal two interesting observations that shed light on the impact of prompt tuning on WSSS. First, modifying only the class token of the text prompt results in a greater impact on the Class Activation Map (CAM), compared to arguably more complex strategies that optimize the context. And second, the class token associated with the image ground truth does not necessarily correspond to the category that yields the best CAM. Motivated by these observations, we introduce a novel approach based on a PrOmpt cLass lEarning (POLE) strategy. Through extensive experiments we demonstrate that our simple, yet efficient approach achieves SOTA performance in a well-known WSSS benchmark. These results highlight not only the benefits of language-vision models in WSSS but also the potential of prompt learning for this problem. The code is available at https://github.com/rB080/WSS_POLE.
UT-Net: Combining U-Net and Transformer for Joint Optic Disc and Cup Segmentation and Glaucoma Detection
Mar 08, 2023



Glaucoma is a chronic visual disease that may cause permanent irreversible blindness. Measurement of the cup-to-disc ratio (CDR) plays a pivotal role in the detection of glaucoma in its early stage, preventing visual disparities. Therefore, accurate and automatic segmentation of optic disc (OD) and optic cup (OC) from retinal fundus images is a fundamental requirement. Existing CNN-based segmentation frameworks resort to building deep encoders with aggressive downsampling layers, which suffer from a general limitation on modeling explicit long-range dependency. To this end, in this paper, we propose a new segmentation pipeline, called UT-Net, availing the advantages of U-Net and transformer both in its encoding layer, followed by an attention-gated bilinear fusion scheme. In addition to this, we incorporate Multi-Head Contextual attention to enhance the regular self-attention used in traditional vision transformers. Thus low-level features along with global dependencies are captured in a shallow manner. Besides, we extract context information at multiple encoding layers for better exploration of receptive fields, and to aid the model to learn deep hierarchical representations. Finally, an enhanced mixing loss is proposed to tightly supervise the overall learning process. The proposed model has been implemented for joint OD and OC segmentation on three publicly available datasets: DRISHTI-GS, RIM-ONE R3, and REFUGE. Additionally, to validate our proposal, we have performed exhaustive experimentation on Glaucoma detection from all three datasets by measuring the Cup to Disc Ratio (CDR) value. Experimental results demonstrate the superiority of UT-Net as compared to the state-of-the-art methods.
An Embarrassingly Simple Consistency Regularization Method for Semi-Supervised Medical Image Segmentation
Feb 03, 2022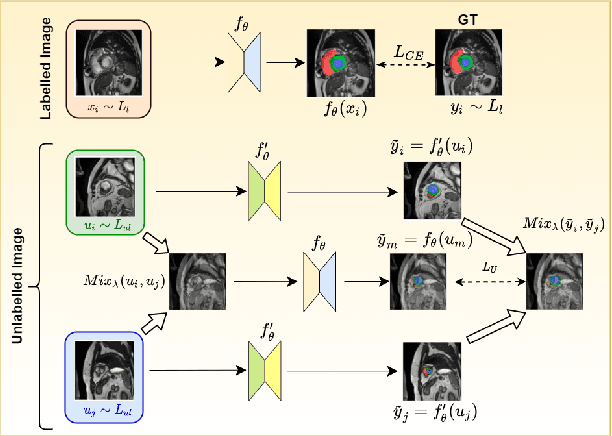

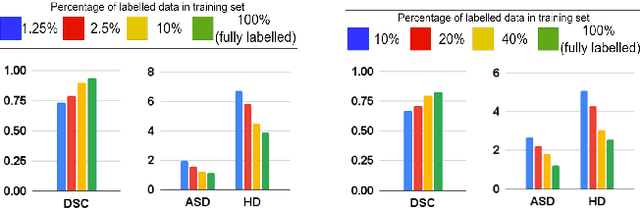
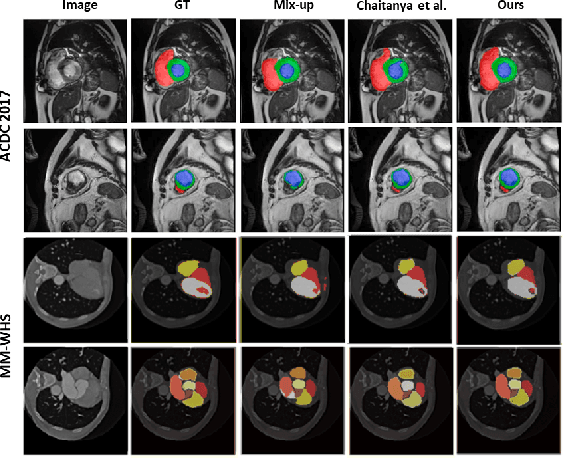
The scarcity of pixel-level annotation is a prevalent problem in medical image segmentation tasks. In this paper, we introduce a novel regularization strategy involving interpolation-based mixing for semi-supervised medical image segmentation. The proposed method is a new consistency regularization strategy that encourages segmentation of interpolation of two unlabelled data to be consistent with the interpolation of segmentation maps of those data. This method represents a specific type of data-adaptive regularization paradigm which aids to minimize the overfitting of labelled data under high confidence values. The proposed method is advantageous over adversarial and generative models as it requires no additional computation. Upon evaluation on two publicly available MRI datasets: ACDC and MMWHS, experimental results demonstrate the superiority of the proposed method in comparison to existing semi-supervised models. Code is available at: https://github.com/hritam-98/ICT-MedSeg
DFENet: A Novel Dimension Fusion Edge Guided Network for Brain MRI Segmentation
May 21, 2021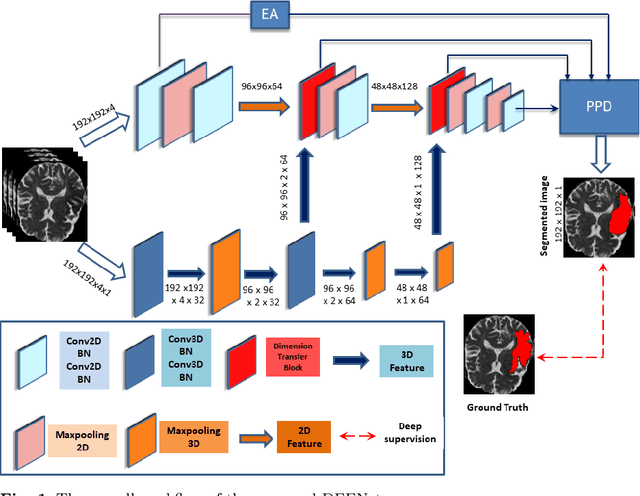


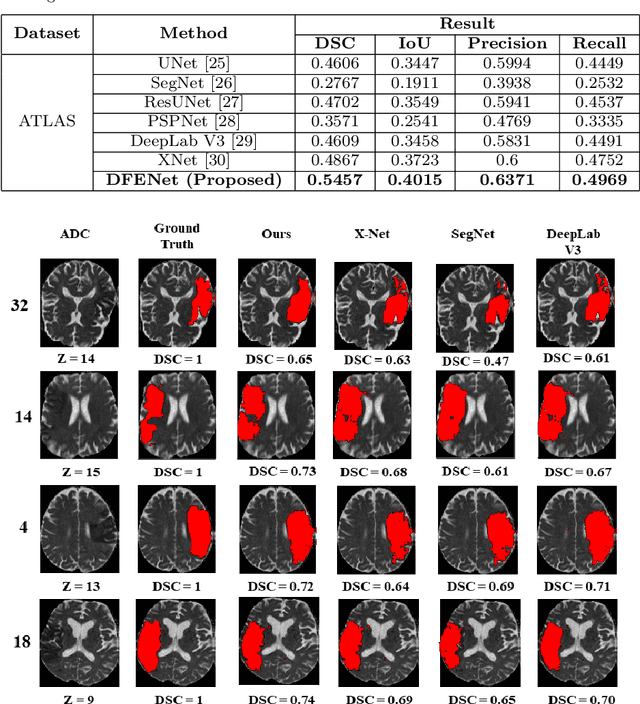
The rapid increment of morbidity of brain stroke in the last few years have been a driving force towards fast and accurate segmentation of stroke lesions from brain MRI images. With the recent development of deep-learning, computer-aided and segmentation methods of ischemic stroke lesions have been useful for clinicians in early diagnosis and treatment planning. However, most of these methods suffer from inaccurate and unreliable segmentation results because of their inability to capture sufficient contextual features from the MRI volumes. To meet these requirements, 3D convolutional neural networks have been proposed, which, however, suffer from huge computational requirements. To mitigate these problems, we propose a novel Dimension Fusion Edge-guided network (DFENet) that can meet both of these requirements by fusing the features of 2D and 3D CNNs. Unlike other methods, our proposed network uses a parallel partial decoder (PPD) module for aggregating and upsampling selected features, rich in important contextual information. Additionally, we use an edge-guidance and enhanced mixing loss for constantly supervising and improvising the learning process of the network. The proposed method is evaluated on publicly available Anatomical Tracings of Lesions After Stroke (ATLAS) dataset, resulting in mean DSC, IoU, Precision and Recall values of 0.5457, 0.4015, 0.6371, and 0.4969 respectively. The results, when compared to other state-of-the-art methods, outperforms them by a significant margin. Therefore, the proposed model is robust, accurate, superior to the existing methods, and can be relied upon for biomedical applications.