 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentSM: Semantic Memory for Agentic Text-to-SQL
Jan 22, 2026Recent advances in LLM-based Text-to-SQL have achieved remarkable gains on public benchmarks such as BIRD and Spider. Yet, these systems struggle to scale in realistic enterprise settings with large, complex schemas, diverse SQL dialects, and expensive multi-step reasoning. Emerging agentic approaches show potential for adaptive reasoning but often suffer from inefficiency and instability-repeating interactions with databases, producing inconsistent outputs, and occasionally failing to generate valid answers. To address these challenges, we introduce Agent Semantic Memory (AgentSM), an agentic framework for Text-to-SQL that builds and leverages interpretable semantic memory. Instead of relying on raw scratchpads or vector retrieval, AgentSM captures prior execution traces-or synthesizes curated ones-as structured programs that directly guide future reasoning. This design enables systematic reuse of reasoning paths, which allows agents to scale to larger schemas, more complex questions, and longer trajectories efficiently and reliably. Compared to state-of-the-art systems, AgentSM achieves higher efficiency by reducing average token usage and trajectory length by 25% and 35%, respectively, on the Spider 2.0 benchmark. It also improves execution accuracy, reaching a state-of-the-art accuracy of 44.8% on the Spider 2.0 Lite benchmark.
SQLens: An End-to-End Framework for Error Detection and Correction in Text-to-SQL
Jun 04, 2025Text-to-SQL systems translate natural language (NL) questions into SQL queries, enabling non-technical users to interact with structured data. While large language models (LLMs) have shown promising results on the text-to-SQL task, they often produce semantically incorrect yet syntactically valid queries, with limited insight into their reliability. We propose SQLens, an end-to-end framework for fine-grained detection and correction of semantic errors in LLM-generated SQL. SQLens integrates error signals from both the underlying database and the LLM to identify potential semantic errors within SQL clauses. It further leverages these signals to guide query correction. Empirical results on two public benchmarks show that SQLens outperforms the best LLM-based self-evaluation method by 25.78% in F1 for error detection, and improves execution accuracy of out-of-the-box text-to-SQL systems by up to 20%.
TailorSQL: An NL2SQL System Tailored to Your Query Workload
May 29, 2025NL2SQL (natural language to SQL) translates natural language questions into SQL queries, thereby making structured data accessible to non-technical users, serving as the foundation for intelligent data applications. State-of-the-art NL2SQL techniques typically perform translation by retrieving database-specific information, such as the database schema, and invoking a pre-trained large language model (LLM) using the question and retrieved information to generate the SQL query. However, existing NL2SQL techniques miss a key opportunity which is present in real-world settings: NL2SQL is typically applied on existing databases which have already served many SQL queries in the past. The past query workload implicitly contains information which is helpful for accurate NL2SQL translation and is not apparent from the database schema alone, such as common join paths and the semantics of obscurely-named tables and columns. We introduce TailorSQL, a NL2SQL system that takes advantage of information in the past query workload to improve both the accuracy and latency of translating natural language questions into SQL. By specializing to a given workload, TailorSQL achieves up to 2$\times$ improvement in execution accuracy on standardized benchmarks.
ODIN: A NL2SQL Recommender to Handle Schema Ambiguity
May 25, 2025NL2SQL (natural language to SQL) systems translate natural language into SQL queries, allowing users with no technical background to interact with databases and create tools like reports or visualizations. While recent advancements in large language models (LLMs) have significantly improved NL2SQL accuracy, schema ambiguity remains a major challenge in enterprise environments with complex schemas, where multiple tables and columns with semantically similar names often co-exist. To address schema ambiguity, we introduce ODIN, a NL2SQL recommendation engine. Instead of producing a single SQL query given a natural language question, ODIN generates a set of potential SQL queries by accounting for different interpretations of ambiguous schema components. ODIN dynamically adjusts the number of suggestions based on the level of ambiguity, and ODIN learns from user feedback to personalize future SQL query recommendations. Our evaluation shows that ODIN improves the likelihood of generating the correct SQL query by 1.5-2$\times$ compared to baselines.
Improving DBMS Scheduling Decisions with Fine-grained Performance Prediction on Concurrent Queries -- Extended
Jan 27, 2025Query scheduling is a critical task that directly impacts query performance in database management systems (DBMS). Deeply integrated schedulers, which require changes to DBMS internals, are usually customized for a specific engine and can take months to implement. In contrast, non-intrusive schedulers make coarse-grained decisions, such as controlling query admission and re-ordering query execution, without requiring modifications to DBMS internals. They require much less engineering effort and can be applied across a wide range of DBMS engines, offering immediate benefits to end users. However, most existing non-intrusive scheduling systems rely on simplified cost models and heuristics that cannot accurately model query interactions under concurrency and different system states, possibly leading to suboptimal scheduling decisions. This work introduces IconqSched, a new, principled non-intrusive scheduler that optimizes the execution order and timing of queries to enhance total end-to-end runtime as experienced by the user query queuing time plus system runtime. Unlike previous approaches, IconqSched features a novel fine-grained predictor, Iconq, which treats the DBMS as a black box and accurately estimates the system runtime of concurrently executed queries under different system states. Using these predictions, IconqSched is able to capture system runtime variations across different query mixes and system loads. It then employs a greedy scheduling algorithm to effectively determine which queries to submit and when to submit them. We compare IconqSched to other schedulers in terms of end-to-end runtime using real workload traces. On Postgres, IconqSched reduces end-to-end runtime by 16.2%-28.2% on average and 33.6%-38.9% in the tail. Similarly, on Redshift, it reduces end-to-end runtime by 10.3%-14.1% on average and 14.9%-22.2% in the tail.
Predict-and-Critic: Accelerated End-to-End Predictive Control for Cloud Computing through Reinforcement Learning
Dec 02, 2022Cloud computing holds the promise of reduced costs through economies of scale. To realize this promise, cloud computing vendors typically solve sequential resource allocation problems, where customer workloads are packed on shared hardware. Virtual machines (VM) form the foundation of modern cloud computing as they help logically abstract user compute from shared physical infrastructure. Traditionally, VM packing problems are solved by predicting demand, followed by a Model Predictive Control (MPC) optimization over a future horizon. We introduce an approximate formulation of an industrial VM packing problem as an MILP with soft-constraints parameterized by the predictions. Recently, predict-and-optimize (PnO) was proposed for end-to-end training of prediction models by back-propagating the cost of decisions through the optimization problem. But, PnO is unable to scale to the large prediction horizons prevalent in cloud computing. To tackle this issue, we propose the Predict-and-Critic (PnC) framework that outperforms PnO with just a two-step horizon by leveraging reinforcement learning. PnC jointly trains a prediction model and a terminal Q function that approximates cost-to-go over a long horizon, by back-propagating the cost of decisions through the optimization problem \emph{and from the future}. The terminal Q function allows us to solve a much smaller two-step horizon optimization problem than the multi-step horizon necessary in PnO. We evaluate PnO and the PnC framework on two datasets, three workloads, and with disturbances not modeled in the optimization problem. We find that PnC significantly improves decision quality over PnO, even when the optimization problem is not a perfect representation of reality. We also find that hardening the soft constraints of the MILP and back-propagating through the constraints improves decision quality for both PnO and PnC.
Zero-Shot Learning for Joint Intent and Slot Labeling
Nov 29, 2022It is expensive and difficult to obtain the large number of sentence-level intent and token-level slot label annotations required to train neural network (NN)-based Natural Language Understanding (NLU) components of task-oriented dialog systems, especially for the many real world tasks that have a large and growing number of intents and slot types. While zero shot learning approaches that require no labeled examples -- only features and auxiliary information -- have been proposed only for slot labeling, we show that one can profitably perform joint zero-shot intent classification and slot labeling. We demonstrate the value of capturing dependencies between intents and slots, and between different slots in an utterance in the zero shot setting. We describe NN architectures that translate between word and sentence embedding spaces, and demonstrate that these modifications are required to enable zero shot learning for this task. We show a substantial improvement over strong baselines and explain the intuition behind each architectural modification through visualizations and ablation studies.
ORL: Reinforcement Learning Benchmarks for Online Stochastic Optimization Problems
Dec 01, 2019
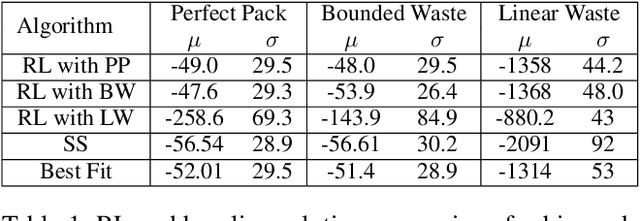
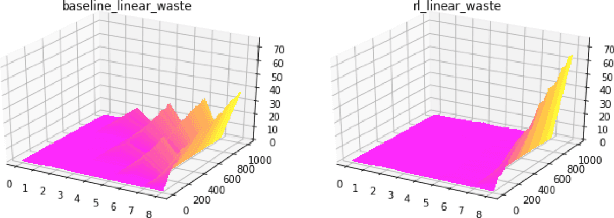
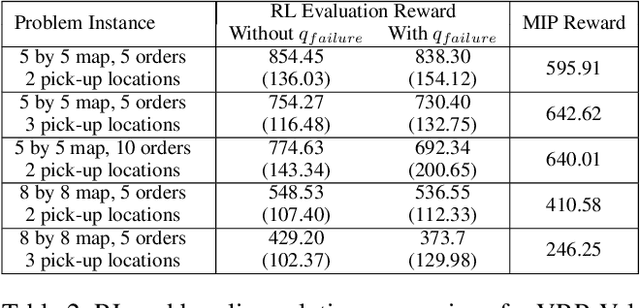
Reinforcement Learning (RL) has achieved state-of-the-art results in domains such as robotics and games. We build on this previous work by applying RL algorithms to a selection of canonical online stochastic optimization problems with a range of practical applications: Bin Packing, Newsvendor, and Vehicle Routing. While there is a nascent literature that applies RL to these problems, there are no commonly accepted benchmarks which can be used to compare proposed approaches rigorously in terms of performance, scale, or generalizability. This paper aims to fill that gap. For each problem we apply both standard approaches as well as newer RL algorithms and analyze results. In each case, the performance of the trained RL policy is competitive with or superior to the corresponding baselines, while not requiring much in the way of domain knowledge. This highlights the potential of RL in real-world dynamic resource allocation problems.
A Multi-Horizon Quantile Recurrent Forecaster
Jun 28, 2018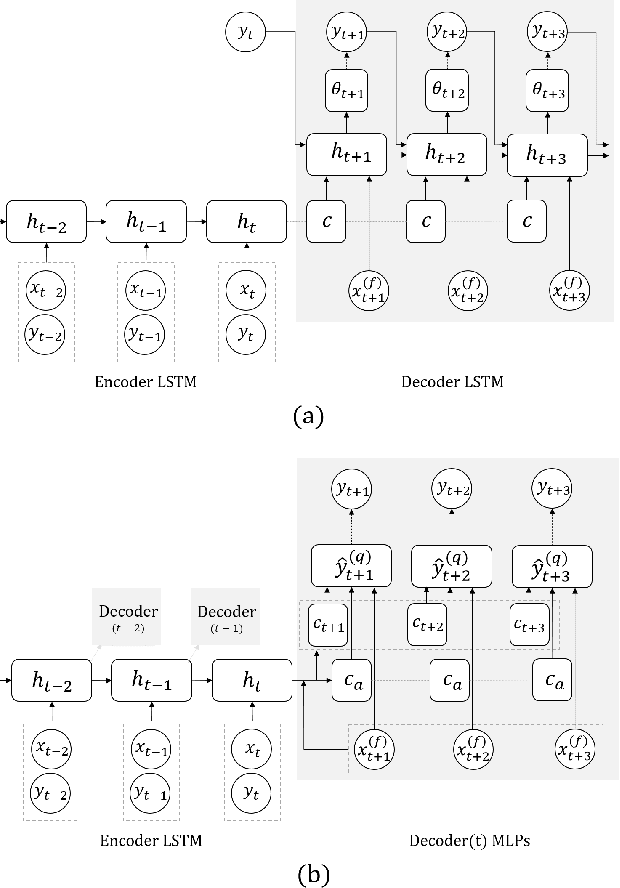
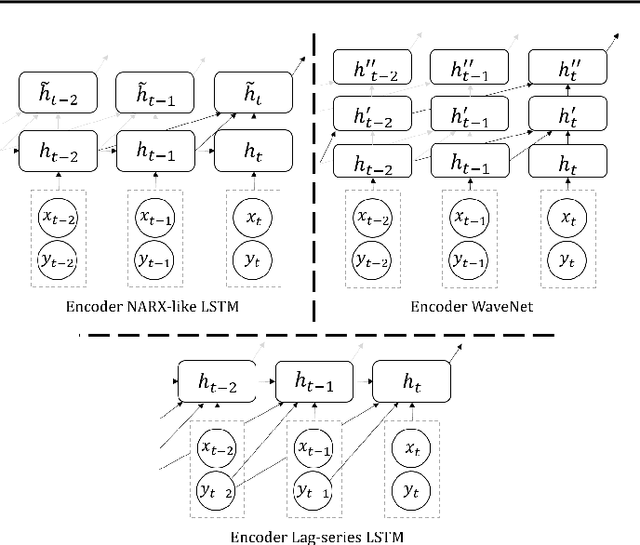
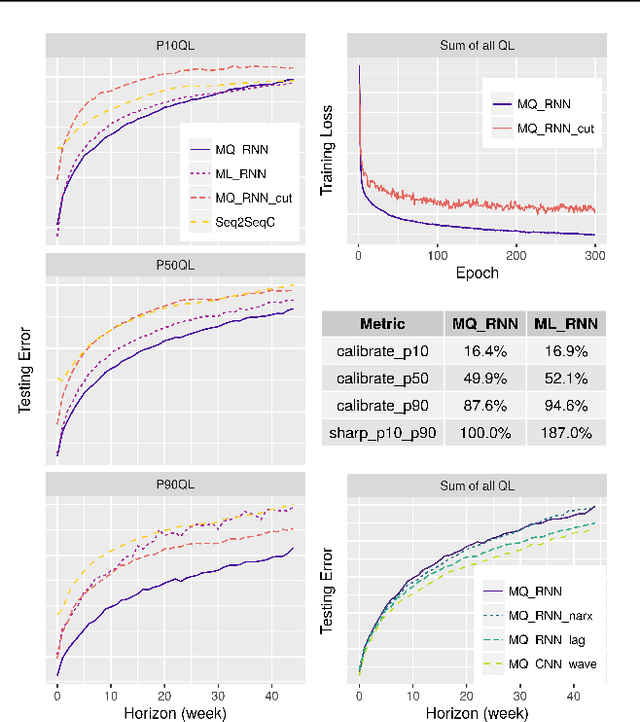
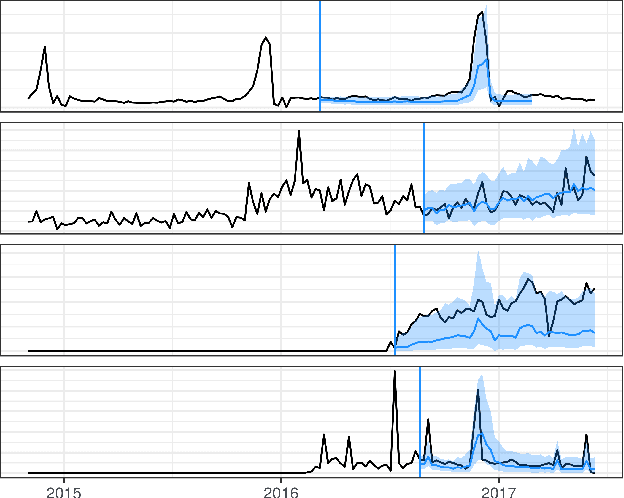
We propose a framework for general probabilistic multi-step time series regression. Specifically, we exploit the expressiveness and temporal nature of Sequence-to-Sequence Neural Networks (e.g. recurrent and convolutional structures), the nonparametric nature of Quantile Regression and the efficiency of Direct Multi-Horizon Forecasting. A new training scheme, *forking-sequences*, is designed for sequential nets to boost stability and performance. We show that the approach accommodates both temporal and static covariates, learning across multiple related series, shifting seasonality, future planned event spikes and cold-starts in real life large-scale forecasting. The performance of the framework is demonstrated in an application to predict the future demand of items sold on Amazon.com, and in a public probabilistic forecasting competition to predict electricity price and load.
Achieving Fluency and Coherency in Task-oriented Dialog
Apr 11, 2018
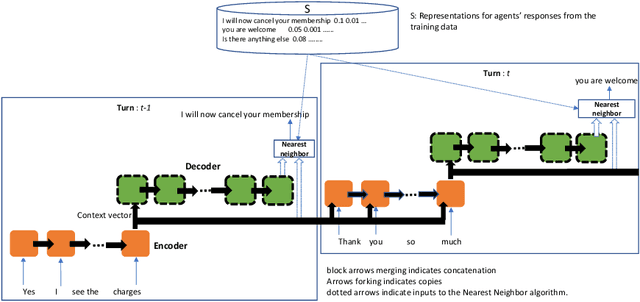


We consider real world task-oriented dialog settings, where agents need to generate both fluent natural language responses and correct external actions like database queries and updates. We demonstrate that, when applied to customer support chat transcripts, Sequence to Sequence (Seq2Seq) models often generate short, incoherent and ungrammatical natural language responses that are dominated by words that occur with high frequency in the training data. These phenomena do not arise in synthetic datasets such as bAbI, where we show Seq2Seq models are nearly perfect. We develop techniques to learn embeddings that succinctly capture relevant information from the dialog history, and demonstrate that nearest neighbor based approaches in this learned neural embedding space generate more fluent responses. However, we see that these methods are not able to accurately predict when to execute an external action. We show how to combine nearest neighbor and Seq2Seq methods in a hybrid model, where nearest neighbor is used to generate fluent responses and Seq2Seq type models ensure dialog coherency and generate accurate external actions. We show that this approach is well suited for customer support scenarios, where agents' responses are typically script-driven, and correct external actions are critically important. The hybrid model on the customer support data achieves a 78% relative improvement in fluency scores, and a 130% improvement in accuracy of external calls.