 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Generic Interactive Segmentation Framework to Correct Mispredictions during Clinical Evaluation of Medical Images
Paper and Code
Aug 06, 2021
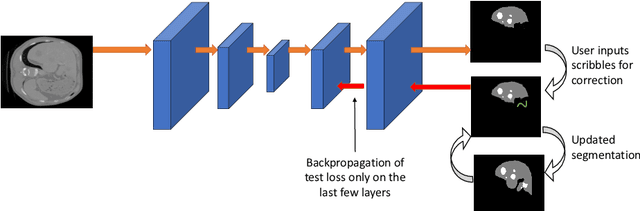
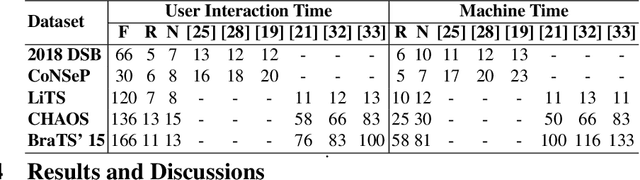

Semantic segmentation of medical images is an essential first step in computer-aided diagnosis systems for many applications. However, given many disparate imaging modalities and inherent variations in the patient data, it is difficult to consistently achieve high accuracy using modern deep neural networks (DNNs). This has led researchers to propose interactive image segmentation techniques where a medical expert can interactively correct the output of a DNN to the desired accuracy. However, these techniques often need separate training data with the associated human interactions, and do not generalize to various diseases, and types of medical images. In this paper, we suggest a novel conditional inference technique for DNNs which takes the intervention by a medical expert as test time constraints and performs inference conditioned upon these constraints. Our technique is generic can be used for medical images from any modality. Unlike other methods, our approach can correct multiple structures simultaneously and add structures missed at initial segmentation. We report an improvement of 13.3, 12.5, 17.8, 10.2, and 12.4 times in user annotation time than full human annotation for the nucleus, multiple cells, liver and tumor, organ, and brain segmentation respectively. We report a time saving of 2.8, 3.0, 1.9, 4.4, and 8.6 fold compared to other interactive segmentation techniques. Our method can be useful to clinicians for diagnosis and post-surgical follow-up with minimal intervention from the medical expert. The source-code and the detailed results are available here [1].