 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Routing Framework: Fully Capsule Network-based Speech Recognition
Paper and Code
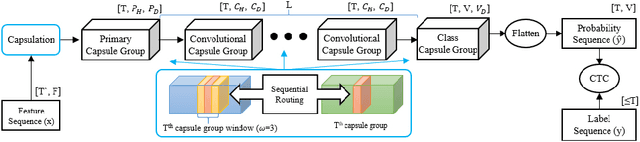
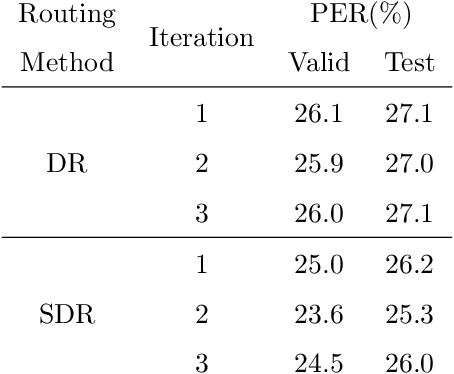
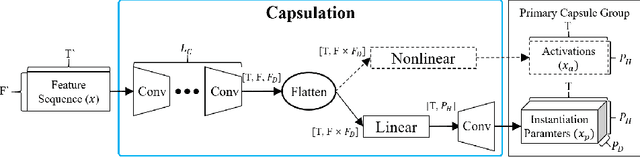
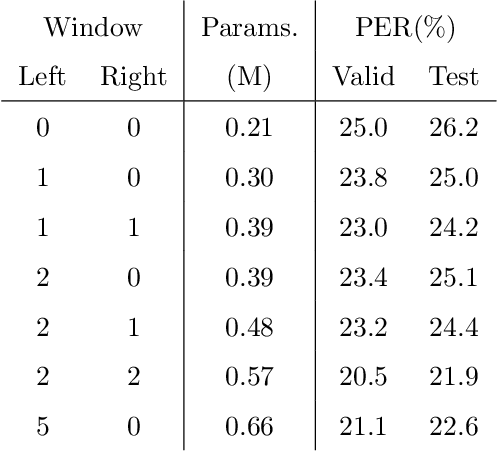
Capsule networks (CapsNets) have recently gotten attention as alternatives for convolutional neural networks (CNNs) with their greater hierarchical representation capabilities. In this paper, we introduce the sequential routing framework (SRF) which we believe is the first method to adapt a CapsNet-only structure to sequence-to-sequence recognition. In SRF, input sequences are capsulized then sliced by the window size. Each sliced window is classified to a label at the corresponding time through iterative routing mechanisms. Afterwards, training losses are computed using connectionist temporal classification (CTC). During routing, two kinds of information, learnable weights and iteration outputs are shared across the slices. By sharing the information, the required parameter numbers can be controlled by the given window size regardless of the length of sequences. Moreover, the method can minimize decoding speed degradation caused by the routing iterations since it can operate in a non-iterative manner at inference time without dropping accuracy. We empirically proved the validity of our method by performing phoneme sequence recognition tasks on the TIMIT corpus. The proposed method attains an 82.6% phoneme recognition rate. It is 0.8% more accurate than that of CNN-based CTC networks and on par with that of recurrent neural network transducers (RNN-Ts). Even more, the method requires less than half the parameters compared to the two architectures.