 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoMo: A Large-Scale, Richly Organized Dataset and Semantic Taxonomy for Human Motion Generation
May 25, 2026Success in generative modeling across language, image, and video demonstrates that large, well-curated datasets are the key driver for building capable models. 3D Human motion, however, has lagged behind, constrained by an unsatisfying choice between small, high-fidelity motion capture datasets and large-scale in-the-wild collections dominated by static or low-quality sequences. We introduce RoMo, a rich, large-scale, carefully curated dataset of in-the-wild human motions that resolves these tradeoffs. To ensure quality, we introduce a taxonomy-aware filtering pipeline that aggressively removes static and artifact-prone sequences. Every sequence is annotated with detailed captions and organized by a novel three-level semantic taxonomy. This hierarchical structure enables fine-grained, per-category evaluation, that reveals model strengths and weaknesses obscured by global metrics. We demonstrate that models trained on RoMo achieve state-of-the-art fidelity and diversity while gaining a superior understanding of complex, subtle text prompts. Finally, we release the Motion Toolbox to standardize metrics, data conversion, and visualization, establishing a foundation for reproducible and interpretable motion generation research.
Attention based on-device streaming speech recognition with large speech corpus
Jan 02, 2020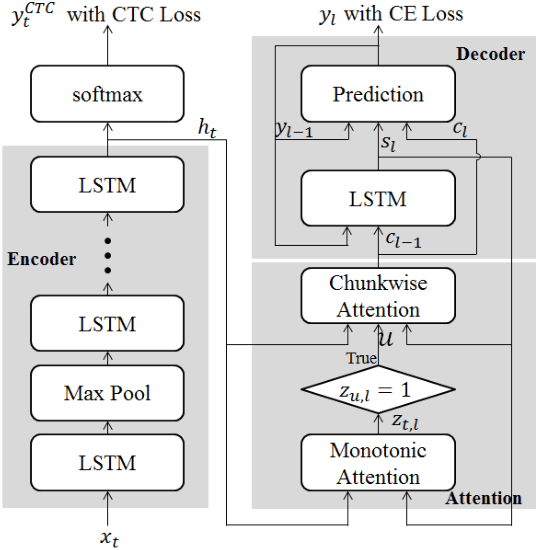
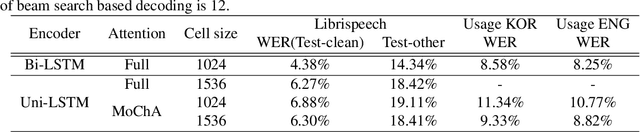

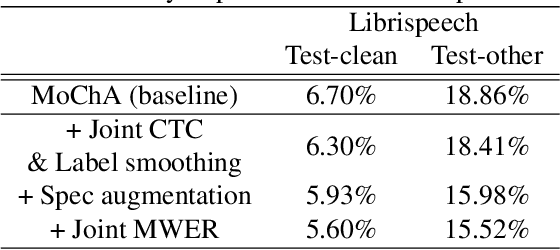
In this paper, we present a new on-device automatic speech recognition (ASR) system based on monotonic chunk-wise attention (MoChA) models trained with large (> 10K hours) corpus. We attained around 90% of a word recognition rate for general domain mainly by using joint training of connectionist temporal classifier (CTC) and cross entropy (CE) losses, minimum word error rate (MWER) training, layer-wise pre-training and data augmentation methods. In addition, we compressed our models by more than 3.4 times smaller using an iterative hyper low-rank approximation (LRA) method while minimizing the degradation in recognition accuracy. The memory footprint was further reduced with 8-bit quantization to bring down the final model size to lower than 39 MB. For on-demand adaptation, we fused the MoChA models with statistical n-gram models, and we could achieve a relatively 36% improvement on average in word error rate (WER) for target domains including the general domain.