 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVersatile and Fast Location-Based Private Information Retrieval with Fully Homomorphic Encryption over the Torus
Jun 15, 2025Location-based services often require users to share sensitive locational data, raising privacy concerns due to potential misuse or exploitation by untrusted servers. In response, we present VeLoPIR, a versatile location-based private information retrieval (PIR) system designed to preserve user privacy while enabling efficient and scalable query processing. VeLoPIR introduces three operational modes-interval validation, coordinate validation, and identifier matching-that support a broad range of real-world applications, including information and emergency alerts. To enhance performance, VeLoPIR incorporates multi-level algorithmic optimizations with parallel structures, achieving significant scalability across both CPU and GPU platforms. We also provide formal security and privacy proofs, confirming the system's robustness under standard cryptographic assumptions. Extensive experiments on real-world datasets demonstrate that VeLoPIR achieves up to 11.55 times speed-up over a prior baseline. The implementation of VeLoPIR is publicly available at https://github.com/PrivStatBool/VeLoPIR.
FADEL: Uncertainty-aware Fake Audio Detection with Evidential Deep Learning
Apr 22, 2025Recently, fake audio detection has gained significant attention, as advancements in speech synthesis and voice conversion have increased the vulnerability of automatic speaker verification (ASV) systems to spoofing attacks. A key challenge in this task is generalizing models to detect unseen, out-of-distribution (OOD) attacks. Although existing approaches have shown promising results, they inherently suffer from overconfidence issues due to the usage of softmax for classification, which can produce unreliable predictions when encountering unpredictable spoofing attempts. To deal with this limitation, we propose a novel framework called fake audio detection with evidential learning (FADEL). By modeling class probabilities with a Dirichlet distribution, FADEL incorporates model uncertainty into its predictions, thereby leading to more robust performance in OOD scenarios. Experimental results on the ASVspoof2019 Logical Access (LA) and ASVspoof2021 LA datasets indicate that the proposed method significantly improves the performance of baseline models. Furthermore, we demonstrate the validity of uncertainty estimation by analyzing a strong correlation between average uncertainty and equal error rate (EER) across different spoofing algorithms.
Towards Maximum Likelihood Training for Transducer-based Streaming Speech Recognition
Nov 26, 2024

Transducer neural networks have emerged as the mainstream approach for streaming automatic speech recognition (ASR), offering state-of-the-art performance in balancing accuracy and latency. In the conventional framework, streaming transducer models are trained to maximize the likelihood function based on non-streaming recursion rules. However, this approach leads to a mismatch between training and inference, resulting in the issue of deformed likelihood and consequently suboptimal ASR accuracy. We introduce a mathematical quantification of the gap between the actual likelihood and the deformed likelihood, namely forward variable causal compensation (FoCC). We also present its estimator, FoCCE, as a solution to estimate the exact likelihood. Through experiments on the LibriSpeech dataset, we show that FoCCE training improves the accuracy of the streaming transducers.
Speed-up of Data Analysis with Kernel Trick in Encrypted Domain
Jun 14, 2024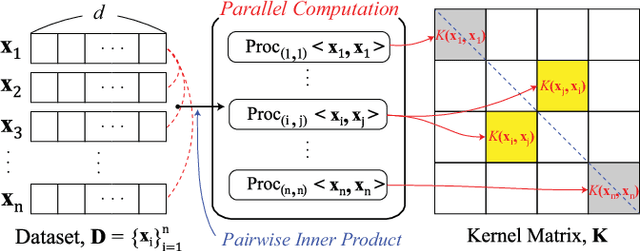
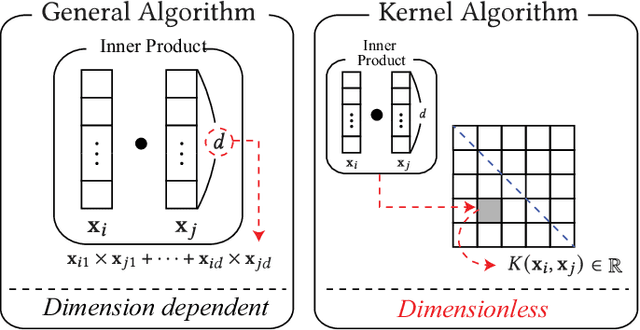

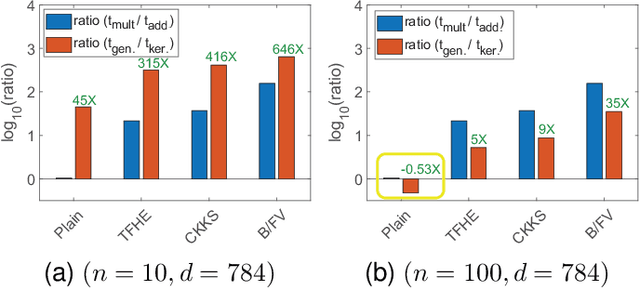
Homomorphic encryption (HE) is pivotal for secure computation on encrypted data, crucial in privacy-preserving data analysis. However, efficiently processing high-dimensional data in HE, especially for machine learning and statistical (ML/STAT) algorithms, poses a challenge. In this paper, we present an effective acceleration method using the kernel method for HE schemes, enhancing time performance in ML/STAT algorithms within encrypted domains. This technique, independent of underlying HE mechanisms and complementing existing optimizations, notably reduces costly HE multiplications, offering near constant time complexity relative to data dimension. Aimed at accessibility, this method is tailored for data scientists and developers with limited cryptography background, facilitating advanced data analysis in secure environments.
EM-Network: Oracle Guided Self-distillation for Sequence Learning
Jun 14, 2023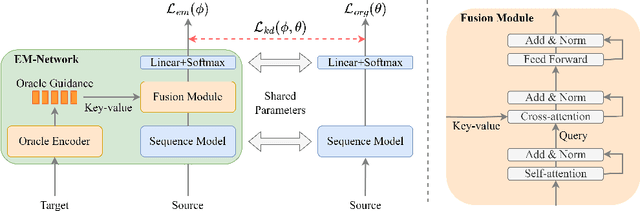
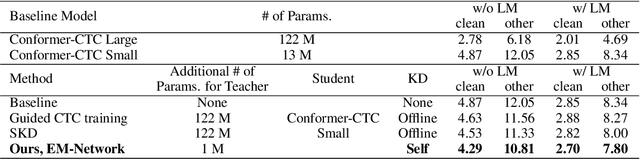
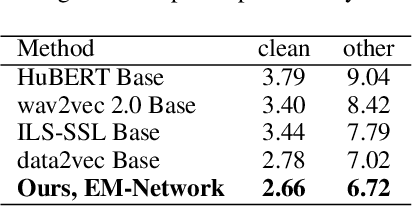
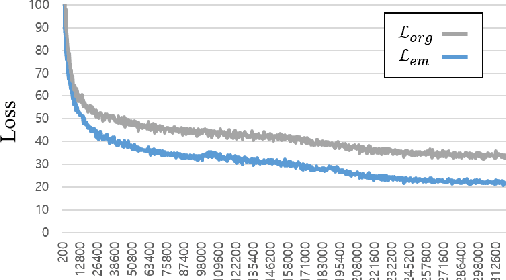
We introduce EM-Network, a novel self-distillation approach that effectively leverages target information for supervised sequence-to-sequence (seq2seq) learning. In contrast to conventional methods, it is trained with oracle guidance, which is derived from the target sequence. Since the oracle guidance compactly represents the target-side context that can assist the sequence model in solving the task, the EM-Network achieves a better prediction compared to using only the source input. To allow the sequence model to inherit the promising capability of the EM-Network, we propose a new self-distillation strategy, where the original sequence model can benefit from the knowledge of the EM-Network in a one-stage manner. We conduct comprehensive experiments on two types of seq2seq models: connectionist temporal classification (CTC) for speech recognition and attention-based encoder-decoder (AED) for machine translation. Experimental results demonstrate that the EM-Network significantly advances the current state-of-the-art approaches, improving over the best prior work on speech recognition and establishing state-of-the-art performance on WMT'14 and IWSLT'14.
MCR-Data2vec 2.0: Improving Self-supervised Speech Pre-training via Model-level Consistency Regularization
Jun 14, 2023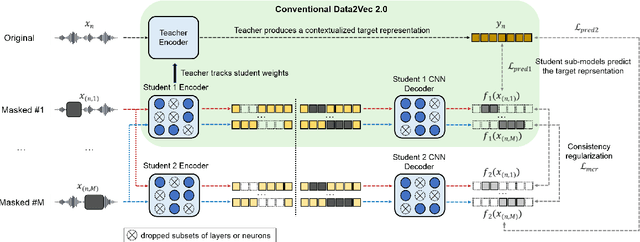
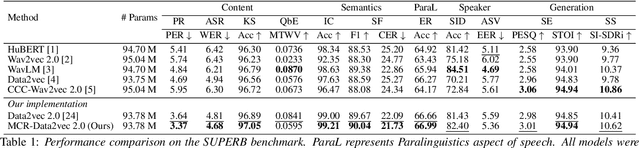
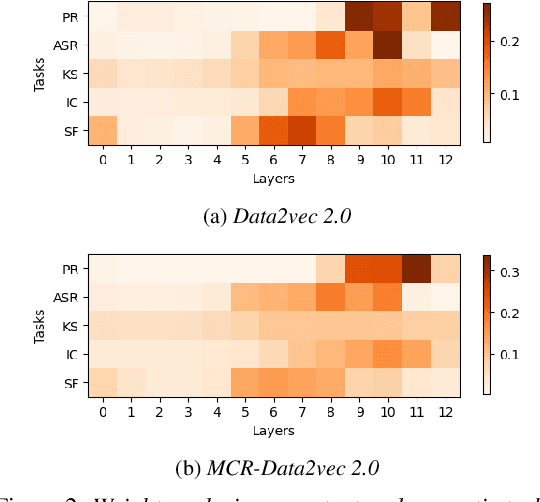
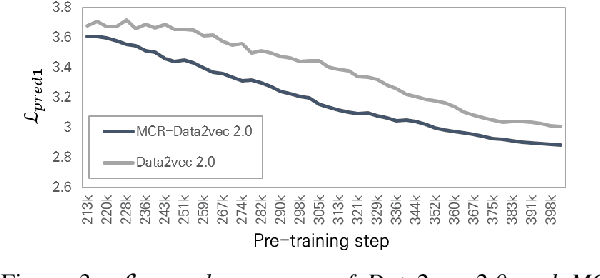
Self-supervised learning (SSL) has shown significant progress in speech processing tasks. However, despite the intrinsic randomness in the Transformer structure, such as dropout variants and layer-drop, improving the model-level consistency remains under-explored in the speech SSL literature. To address this, we propose a new pre-training method that uses consistency regularization to improve Data2vec 2.0, the recent state-of-the-art (SOTA) SSL model. Specifically, the proposed method involves sampling two different student sub-models within the Data2vec 2.0 framework, enabling two output variants derived from a single input without additional parameters. Subsequently, we regularize the outputs from the student sub-models to be consistent and require them to predict the representation of the teacher model. Our experimental results demonstrate that the proposed approach improves the SSL model's robustness and generalization ability, resulting in SOTA results on the SUPERB benchmark.
Development of deep biological ages aware of morbidity and mortality based on unsupervised and semi-supervised deep learning approaches
Feb 01, 2023



Background: While deep learning technology, which has the capability of obtaining latent representations based on large-scale data, can be a potential solution for the discovery of a novel aging biomarker, existing deep learning methods for biological age estimation usually depend on chronological ages and lack of consideration of mortality and morbidity that are the most significant outcomes of aging. Methods: This paper proposes a novel deep learning model to learn latent representations of biological aging in regard to subjects' morbidity and mortality. The model utilizes health check-up data in addition to morbidity and mortality information to learn the complex relationships between aging and measured clinical attributes. Findings: The proposed model is evaluated on a large dataset of general populations compared with KDM and other learning-based models. Results demonstrate that biological ages obtained by the proposed model have superior discriminability of subjects' morbidity and mortality.
Inter-KD: Intermediate Knowledge Distillation for CTC-Based Automatic Speech Recognition
Nov 28, 2022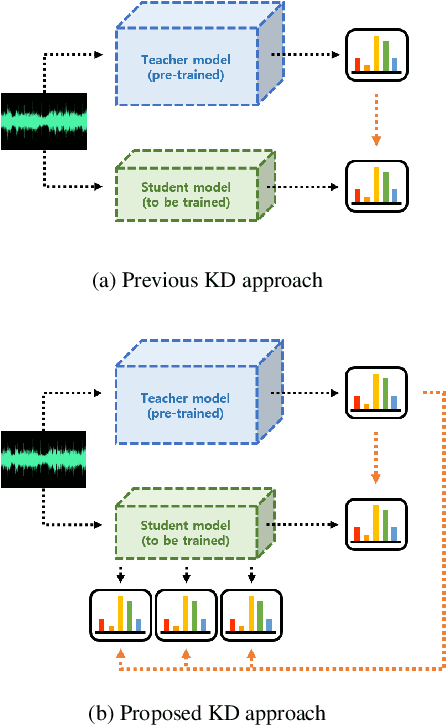
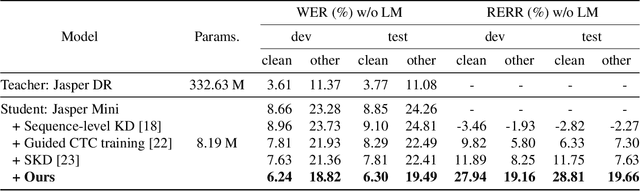
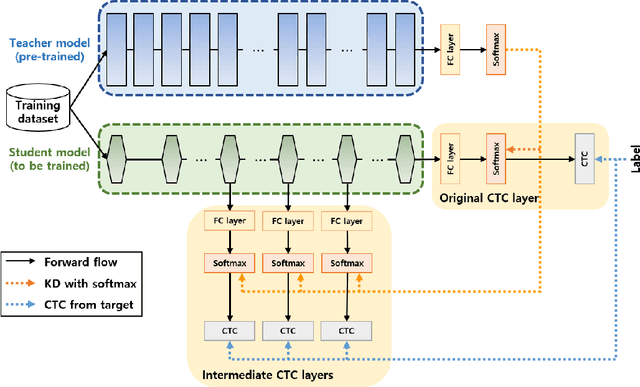

Recently, the advance in deep learning has brought a considerable improvement in the end-to-end speech recognition field, simplifying the traditional pipeline while producing promising results. Among the end-to-end models, the connectionist temporal classification (CTC)-based model has attracted research interest due to its non-autoregressive nature. However, such CTC models require a heavy computational cost to achieve outstanding performance. To mitigate the computational burden, we propose a simple yet effective knowledge distillation (KD) for the CTC framework, namely Inter-KD, that additionally transfers the teacher's knowledge to the intermediate CTC layers of the student network. From the experimental results on the LibriSpeech, we verify that the Inter-KD shows better achievements compared to the conventional KD methods. Without using any language model (LM) and data augmentation, Inter-KD improves the word error rate (WER) performance from 8.85 % to 6.30 % on the test-clean.
HuBERT-EE: Early Exiting HuBERT for Efficient Speech Recognition
Apr 13, 2022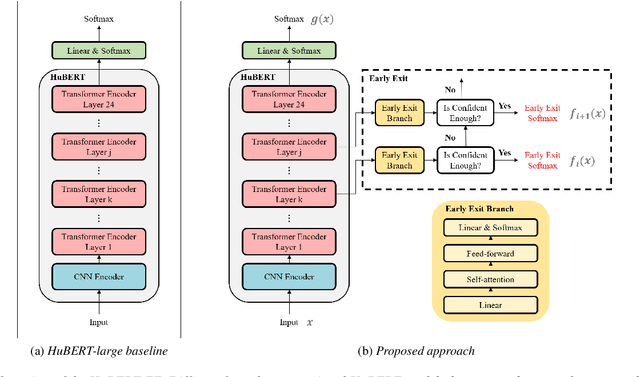
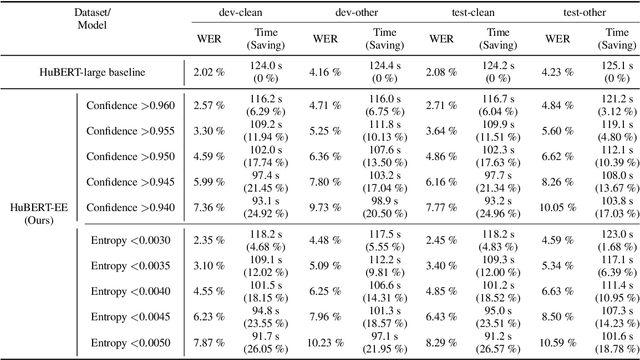

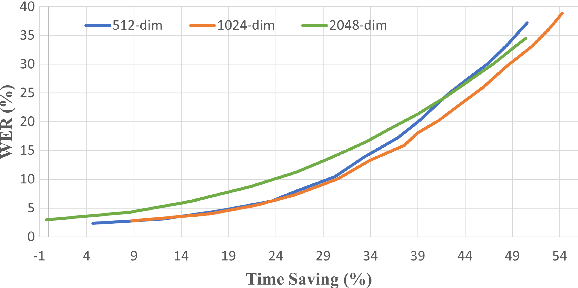
Pre-training with self-supervised models, such as Hidden-unit BERT (HuBERT) and wav2vec 2.0, has brought significant improvements in automatic speech recognition (ASR). However, these models usually require an expensive computational cost to achieve outstanding performance, slowing down the inference speed. To improve the model efficiency, we propose an early exit scheme for ASR, namely HuBERT-EE, that allows the model to stop the inference dynamically. In HuBERT-EE, multiple early exit branches are added at the intermediate layers, and each branch is used to decide whether a prediction can be exited early. Experimental results on the LibriSpeech dataset show that HuBERT-EE can accelerate the inference of a large-scale HuBERT model while simultaneously balancing the trade-off between the word error rate (WER) performance and the latency.
Oracle Teacher: Towards Better Knowledge Distillation
Nov 05, 2021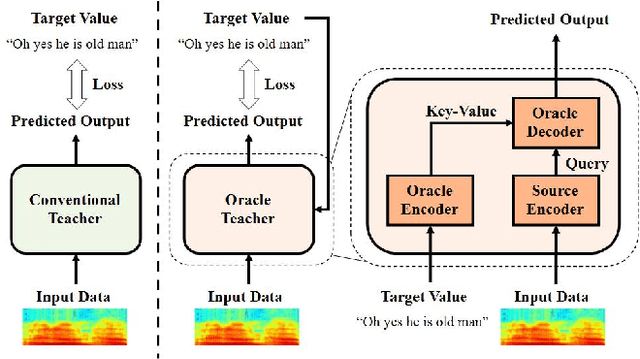
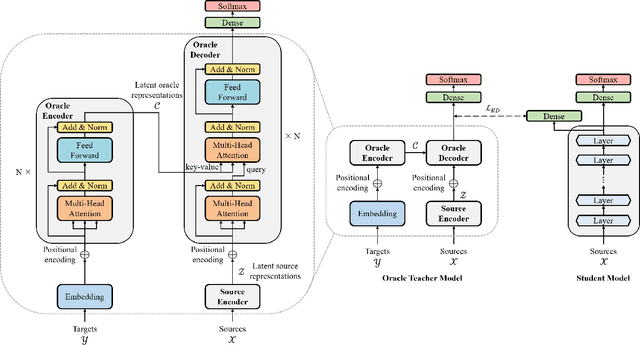
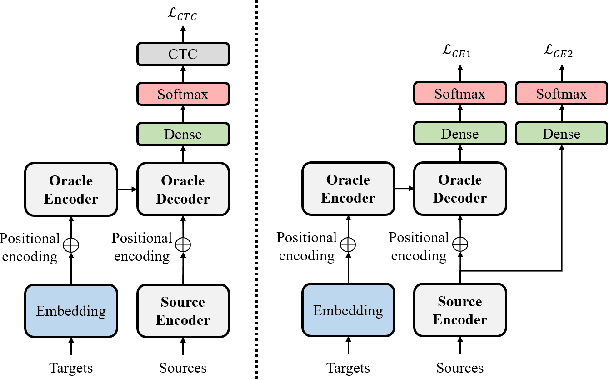

Knowledge distillation (KD), best known as an effective method for model compression, aims at transferring the knowledge of a bigger network (teacher) to a much smaller network (student). Conventional KD methods usually employ the teacher model trained in a supervised manner, where output labels are treated only as targets. Extending this supervised scheme further, we introduce a new type of teacher model for KD, namely Oracle Teacher, that utilizes the embeddings of both the source inputs and the output labels to extract a more accurate knowledge to be transferred to the student. The proposed model follows the encoder-decoder attention structure of the Transformer network, which allows the model to attend to related information from the output labels. Extensive experiments are conducted on three different sequence learning tasks: speech recognition, scene text recognition, and machine translation. From the experimental results, we empirically show that the proposed model improves the students across these tasks while achieving a considerable speed-up in the teacher model's training time.