 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOracle Teacher: Towards Better Knowledge Distillation
Paper and Code
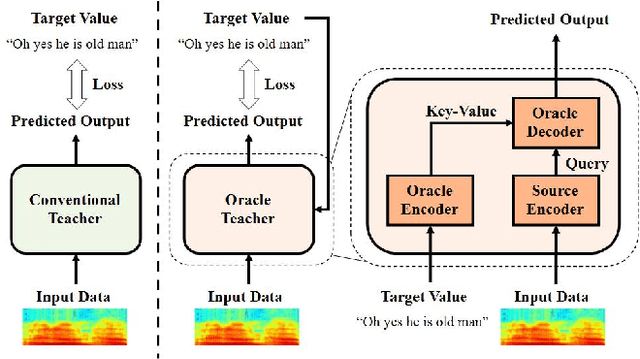
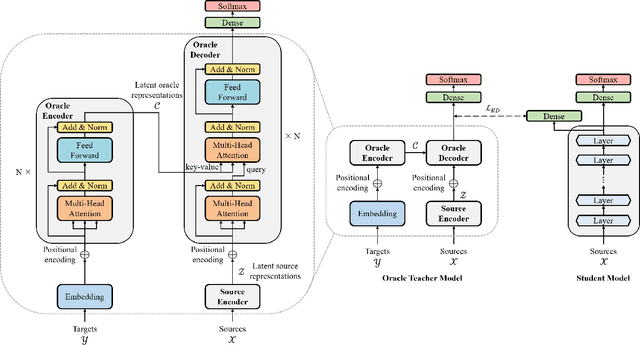
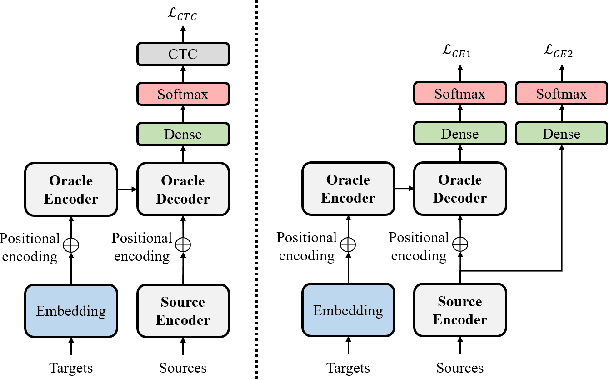

Knowledge distillation (KD), best known as an effective method for model compression, aims at transferring the knowledge of a bigger network (teacher) to a much smaller network (student). Conventional KD methods usually employ the teacher model trained in a supervised manner, where output labels are treated only as targets. Extending this supervised scheme further, we introduce a new type of teacher model for KD, namely Oracle Teacher, that utilizes the embeddings of both the source inputs and the output labels to extract a more accurate knowledge to be transferred to the student. The proposed model follows the encoder-decoder attention structure of the Transformer network, which allows the model to attend to related information from the output labels. Extensive experiments are conducted on three different sequence learning tasks: speech recognition, scene text recognition, and machine translation. From the experimental results, we empirically show that the proposed model improves the students across these tasks while achieving a considerable speed-up in the teacher model's training time.