 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCR-Data2vec 2.0: Improving Self-supervised Speech Pre-training via Model-level Consistency Regularization
Paper and Code
Jun 14, 2023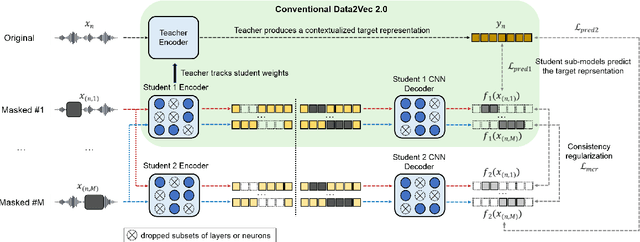
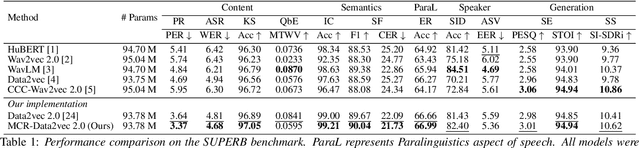
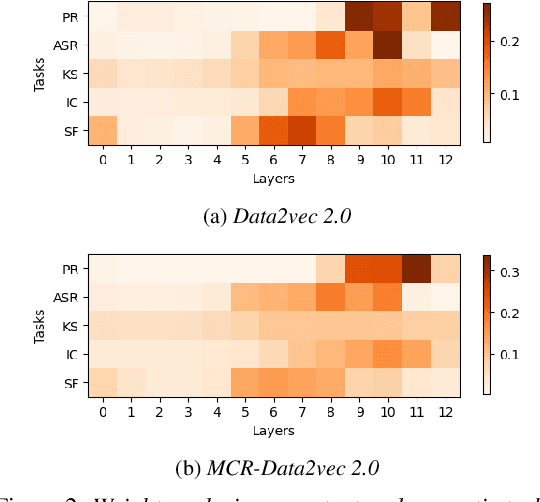
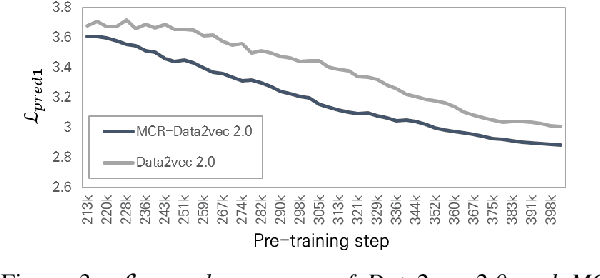
Self-supervised learning (SSL) has shown significant progress in speech processing tasks. However, despite the intrinsic randomness in the Transformer structure, such as dropout variants and layer-drop, improving the model-level consistency remains under-explored in the speech SSL literature. To address this, we propose a new pre-training method that uses consistency regularization to improve Data2vec 2.0, the recent state-of-the-art (SOTA) SSL model. Specifically, the proposed method involves sampling two different student sub-models within the Data2vec 2.0 framework, enabling two output variants derived from a single input without additional parameters. Subsequently, we regularize the outputs from the student sub-models to be consistent and require them to predict the representation of the teacher model. Our experimental results demonstrate that the proposed approach improves the SSL model's robustness and generalization ability, resulting in SOTA results on the SUPERB benchmark.