 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPGA-Based Low-Power Speech Recognition with Recurrent Neural Networks
Sep 30, 2016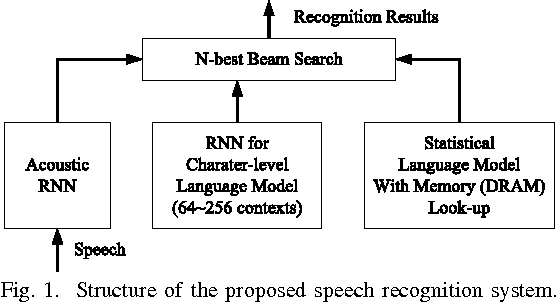
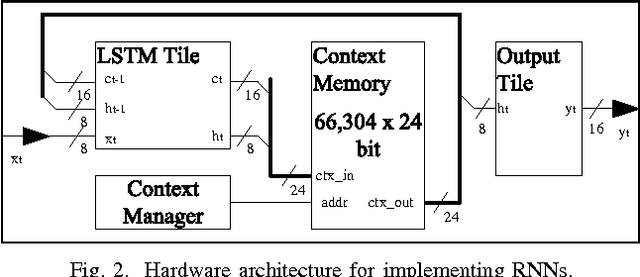
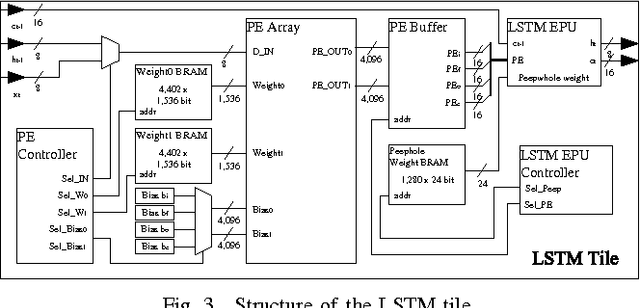
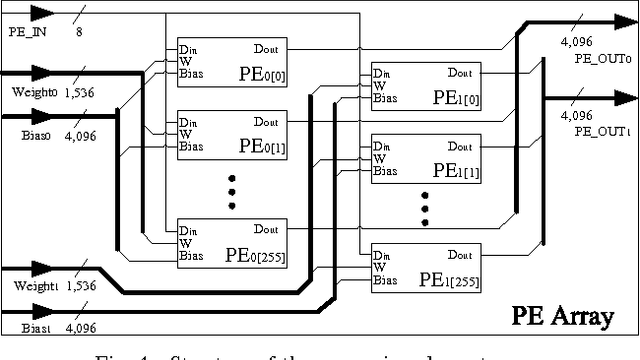
In this paper, a neural network based real-time speech recognition (SR) system is developed using an FPGA for very low-power operation. The implemented system employs two recurrent neural networks (RNNs); one is a speech-to-character RNN for acoustic modeling (AM) and the other is for character-level language modeling (LM). The system also employs a statistical word-level LM to improve the recognition accuracy. The results of the AM, the character-level LM, and the word-level LM are combined using a fairly simple N-best search algorithm instead of the hidden Markov model (HMM) based network. The RNNs are implemented using massively parallel processing elements (PEs) for low latency and high throughput. The weights are quantized to 6 bits to store all of them in the on-chip memory of an FPGA. The proposed algorithm is implemented on a Xilinx XC7Z045, and the system can operate much faster than real-time.