 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSapAugment: Learning A Sample Adaptive Policy for Data Augmentation
Nov 02, 2020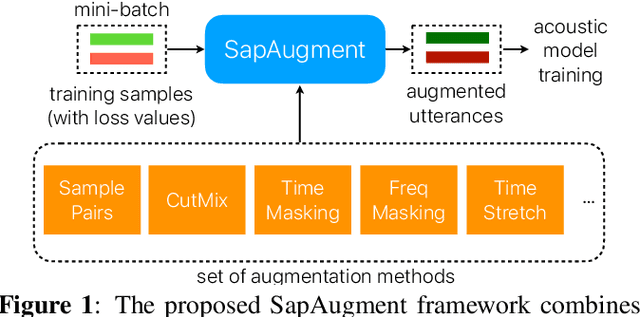
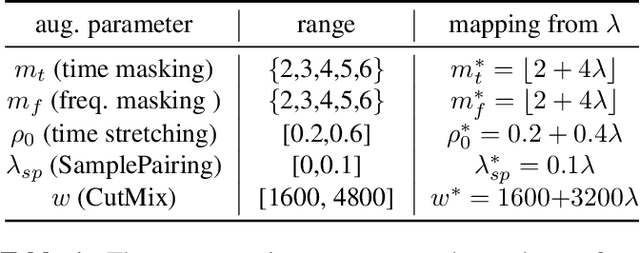
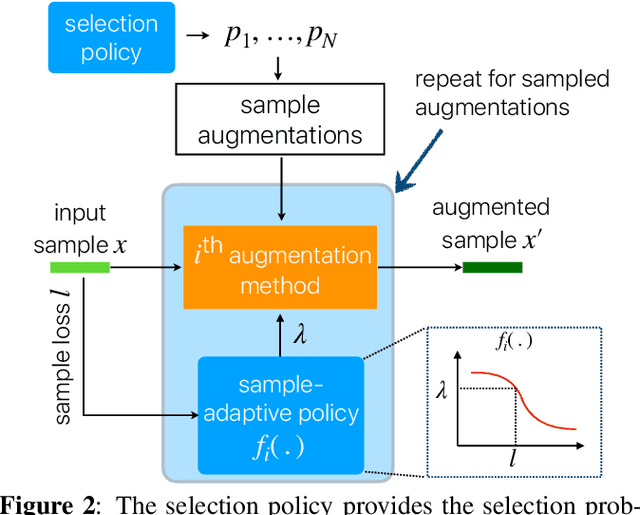
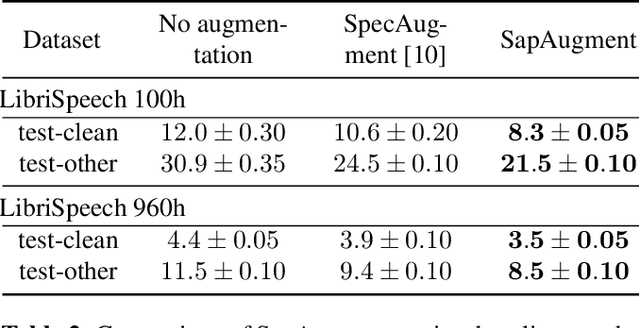
Data augmentation methods usually apply the same augmentation (or a mix of them) to all the training samples. For example, to perturb data with noise, the noise is sampled from a Normal distribution with a fixed standard deviation, for all samples. We hypothesize that a hard sample with high training loss already provides strong training signal to update the model parameters and should be perturbed with mild or no augmentation. Perturbing a hard sample with a strong augmentation may also make it too hard to learn from. Furthermore, a sample with low training loss should be perturbed by a stronger augmentation to provide more robustness to a variety of conditions. To formalize these intuitions, we propose a novel method to learn a Sample-Adaptive Policy for Augmentation -- SapAugment. Our policy adapts the augmentation parameters based on the training loss of the data samples. In the example of Gaussian noise, a hard sample will be perturbed with a low variance noise and an easy sample with a high variance noise. Furthermore, the proposed method combines multiple augmentation methods into a methodical policy learning framework and obviates hand-crafting augmentation parameters by trial-and-error. We apply our method on an automatic speech recognition (ASR) task, and combine existing and novel augmentations using the proposed framework. We show substantial improvement, up to 21% relative reduction in word error rate on LibriSpeech dataset, over the state-of-the-art speech augmentation method.
Generative Knowledge Transfer for Neural Language Models
Feb 28, 2017



In this paper, we propose a generative knowledge transfer technique that trains an RNN based language model (student network) using text and output probabilities generated from a previously trained RNN (teacher network). The text generation can be conducted by either the teacher or the student network. We can also improve the performance by taking the ensemble of soft labels obtained from multiple teacher networks. This method can be used for privacy conscious language model adaptation because no user data is directly used for training. Especially, when the soft labels of multiple devices are aggregated via a trusted third party, we can expect very strong privacy protection.
Character-Level Language Modeling with Hierarchical Recurrent Neural Networks
Feb 02, 2017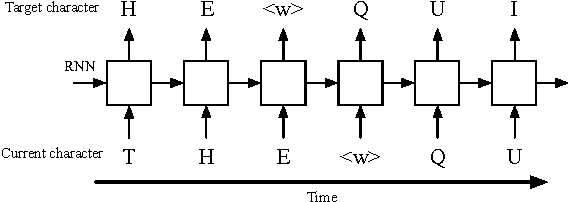
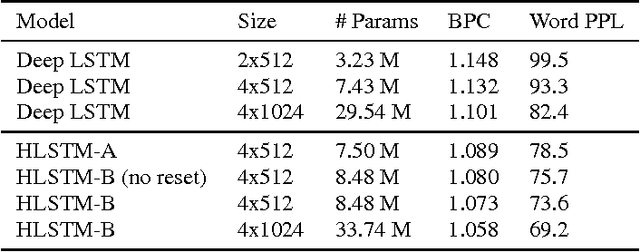
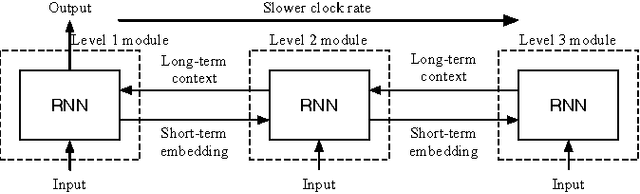

Recurrent neural network (RNN) based character-level language models (CLMs) are extremely useful for modeling out-of-vocabulary words by nature. However, their performance is generally much worse than the word-level language models (WLMs), since CLMs need to consider longer history of tokens to properly predict the next one. We address this problem by proposing hierarchical RNN architectures, which consist of multiple modules with different timescales. Despite the multi-timescale structures, the input and output layers operate with the character-level clock, which allows the existing RNN CLM training approaches to be directly applicable without any modifications. Our CLM models show better perplexity than Kneser-Ney (KN) 5-gram WLMs on the One Billion Word Benchmark with only 2% of parameters. Also, we present real-time character-level end-to-end speech recognition examples on the Wall Street Journal (WSJ) corpus, where replacing traditional mono-clock RNN CLMs with the proposed models results in better recognition accuracies even though the number of parameters are reduced to 30%.
Online Sequence Training of Recurrent Neural Networks with Connectionist Temporal Classification
Feb 02, 2017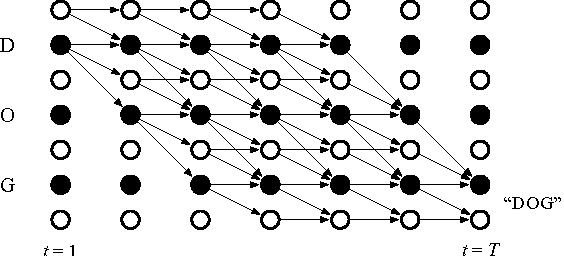

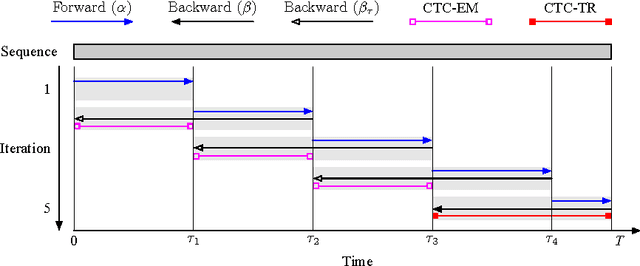

Connectionist temporal classification (CTC) based supervised sequence training of recurrent neural networks (RNNs) has shown great success in many machine learning areas including end-to-end speech and handwritten character recognition. For the CTC training, however, it is required to unroll (or unfold) the RNN by the length of an input sequence. This unrolling requires a lot of memory and hinders a small footprint implementation of online learning or adaptation. Furthermore, the length of training sequences is usually not uniform, which makes parallel training with multiple sequences inefficient on shared memory models such as graphics processing units (GPUs). In this work, we introduce an expectation-maximization (EM) based online CTC algorithm that enables unidirectional RNNs to learn sequences that are longer than the amount of unrolling. The RNNs can also be trained to process an infinitely long input sequence without pre-segmentation or external reset. Moreover, the proposed approach allows efficient parallel training on GPUs. For evaluation, phoneme recognition and end-to-end speech recognition examples are presented on the TIMIT and Wall Street Journal (WSJ) corpora, respectively. Our online model achieves 20.7% phoneme error rate (PER) on the very long input sequence that is generated by concatenating all 192 utterances in the TIMIT core test set. On WSJ, a network can be trained with only 64 times of unrolling while sacrificing 4.5% relative word error rate (WER).
Quantized neural network design under weight capacity constraint
Nov 19, 2016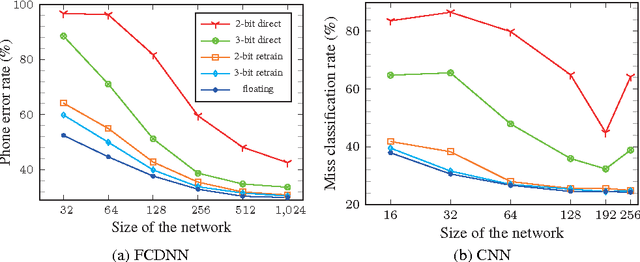

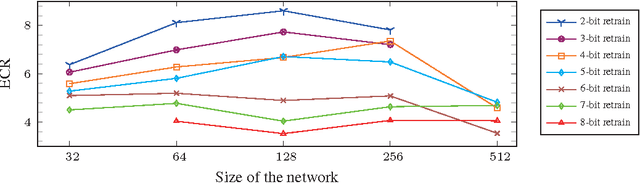
The complexity of deep neural network algorithms for hardware implementation can be lowered either by scaling the number of units or reducing the word-length of weights. Both approaches, however, can accompany the performance degradation although many types of research are conducted to relieve this problem. Thus, it is an important question which one, between the network size scaling and the weight quantization, is more effective for hardware optimization. For this study, the performances of fully-connected deep neural networks (FCDNNs) and convolutional neural networks (CNNs) are evaluated while changing the network complexity and the word-length of weights. Based on these experiments, we present the effective compression ratio (ECR) to guide the trade-off between the network size and the precision of weights when the hardware resource is limited.
FPGA-Based Low-Power Speech Recognition with Recurrent Neural Networks
Sep 30, 2016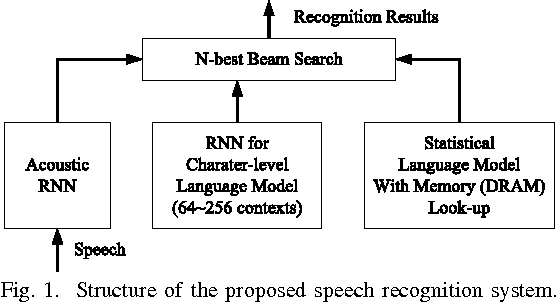
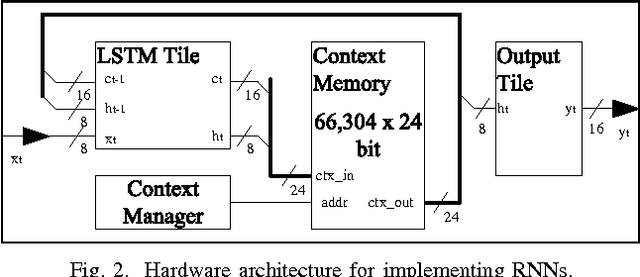
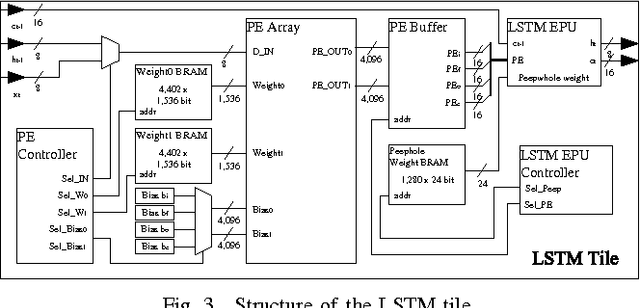
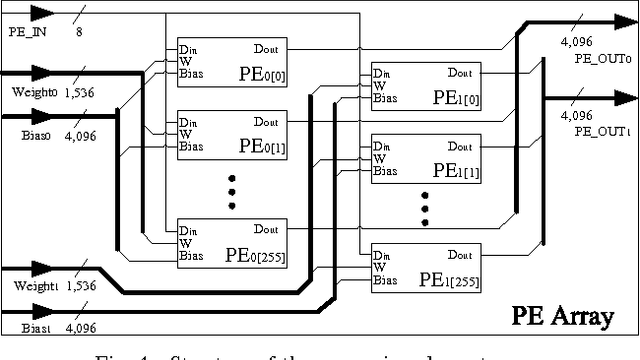
In this paper, a neural network based real-time speech recognition (SR) system is developed using an FPGA for very low-power operation. The implemented system employs two recurrent neural networks (RNNs); one is a speech-to-character RNN for acoustic modeling (AM) and the other is for character-level language modeling (LM). The system also employs a statistical word-level LM to improve the recognition accuracy. The results of the AM, the character-level LM, and the word-level LM are combined using a fairly simple N-best search algorithm instead of the hidden Markov model (HMM) based network. The RNNs are implemented using massively parallel processing elements (PEs) for low latency and high throughput. The weights are quantized to 6 bits to store all of them in the on-chip memory of an FPGA. The proposed algorithm is implemented on a Xilinx XC7Z045, and the system can operate much faster than real-time.
Fixed-Point Performance Analysis of Recurrent Neural Networks
Sep 27, 2016



Recurrent neural networks have shown excellent performance in many applications, however they require increased complexity in hardware or software based implementations. The hardware complexity can be much lowered by minimizing the word-length of weights and signals. This work analyzes the fixed-point performance of recurrent neural networks using a retrain based quantization method. The quantization sensitivity of each layer in RNNs is studied, and the overall fixed-point optimization results minimizing the capacity of weights while not sacrificing the performance are presented. A language model and a phoneme recognition examples are used.
Character-Level Incremental Speech Recognition with Recurrent Neural Networks
Jan 28, 2016
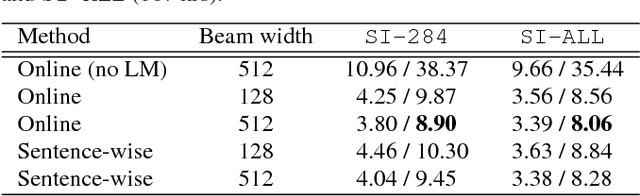
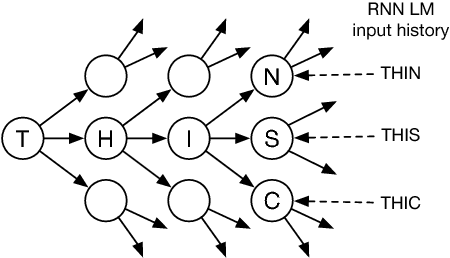

In real-time speech recognition applications, the latency is an important issue. We have developed a character-level incremental speech recognition (ISR) system that responds quickly even during the speech, where the hypotheses are gradually improved while the speaking proceeds. The algorithm employs a speech-to-character unidirectional recurrent neural network (RNN), which is end-to-end trained with connectionist temporal classification (CTC), and an RNN-based character-level language model (LM). The output values of the CTC-trained RNN are character-level probabilities, which are processed by beam search decoding. The RNN LM augments the decoding by providing long-term dependency information. We propose tree-based online beam search with additional depth-pruning, which enables the system to process infinitely long input speech with low latency. This system not only responds quickly on speech but also can dictate out-of-vocabulary (OOV) words according to pronunciation. The proposed model achieves the word error rate (WER) of 8.90% on the Wall Street Journal (WSJ) Nov'92 20K evaluation set when trained on the WSJ SI-284 training set.
Resiliency of Deep Neural Networks under Quantization
Jan 07, 2016
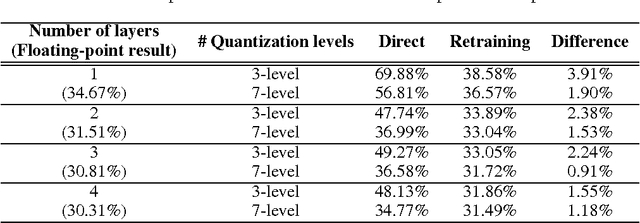


The complexity of deep neural network algorithms for hardware implementation can be much lowered by optimizing the word-length of weights and signals. Direct quantization of floating-point weights, however, does not show good performance when the number of bits assigned is small. Retraining of quantized networks has been developed to relieve this problem. In this work, the effects of retraining are analyzed for a feedforward deep neural network (FFDNN) and a convolutional neural network (CNN). The network complexity is controlled to know their effects on the resiliency of quantized networks by retraining. The complexity of the FFDNN is controlled by varying the unit size in each hidden layer and the number of layers, while that of the CNN is done by modifying the feature map configuration. We find that the performance gap between the floating-point and the retrain-based ternary (+1, 0, -1) weight neural networks exists with a fair amount in 'complexity limited' networks, but the discrepancy almost vanishes in fully complex networks whose capability is limited by the training data, rather than by the number of connections. This research shows that highly complex DNNs have the capability of absorbing the effects of severe weight quantization through retraining, but connection limited networks are less resilient. This paper also presents the effective compression ratio to guide the trade-off between the network size and the precision when the hardware resource is limited.
Online Keyword Spotting with a Character-Level Recurrent Neural Network
Dec 30, 2015
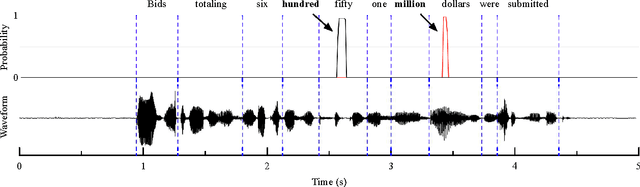
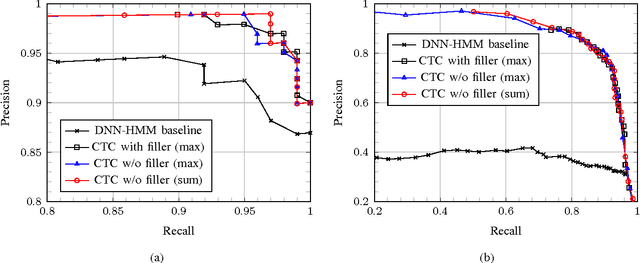
In this paper, we propose a context-aware keyword spotting model employing a character-level recurrent neural network (RNN) for spoken term detection in continuous speech. The RNN is end-to-end trained with connectionist temporal classification (CTC) to generate the probabilities of character and word-boundary labels. There is no need for the phonetic transcription, senone modeling, or system dictionary in training and testing. Also, keywords can easily be added and modified by editing the text based keyword list without retraining the RNN. Moreover, the unidirectional RNN processes an infinitely long input audio streams without pre-segmentation and keywords are detected with low-latency before the utterance is finished. Experimental results show that the proposed keyword spotter significantly outperforms the deep neural network (DNN) and hidden Markov model (HMM) based keyword-filler model even with less computations.