 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResiliency of Deep Neural Networks under Quantization
Paper and Code
Jan 07, 2016
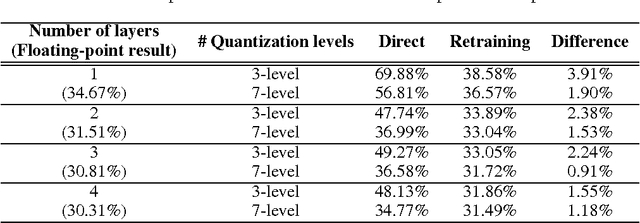


The complexity of deep neural network algorithms for hardware implementation can be much lowered by optimizing the word-length of weights and signals. Direct quantization of floating-point weights, however, does not show good performance when the number of bits assigned is small. Retraining of quantized networks has been developed to relieve this problem. In this work, the effects of retraining are analyzed for a feedforward deep neural network (FFDNN) and a convolutional neural network (CNN). The network complexity is controlled to know their effects on the resiliency of quantized networks by retraining. The complexity of the FFDNN is controlled by varying the unit size in each hidden layer and the number of layers, while that of the CNN is done by modifying the feature map configuration. We find that the performance gap between the floating-point and the retrain-based ternary (+1, 0, -1) weight neural networks exists with a fair amount in 'complexity limited' networks, but the discrepancy almost vanishes in fully complex networks whose capability is limited by the training data, rather than by the number of connections. This research shows that highly complex DNNs have the capability of absorbing the effects of severe weight quantization through retraining, but connection limited networks are less resilient. This paper also presents the effective compression ratio to guide the trade-off between the network size and the precision when the hardware resource is limited.