 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynt++: Utilizing Imperfect Synthetic Data to Improve Speech Recognition
Oct 21, 2021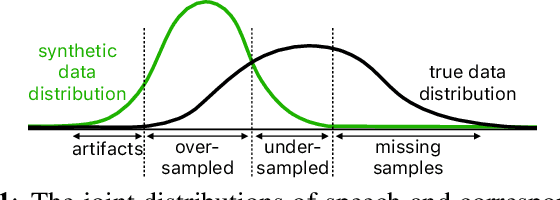
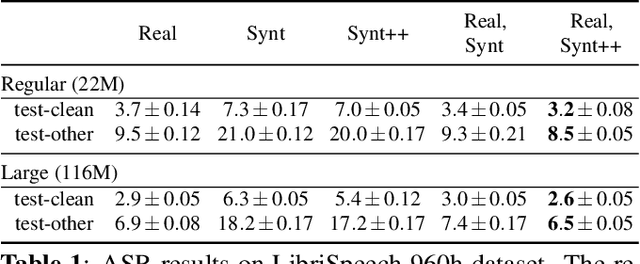
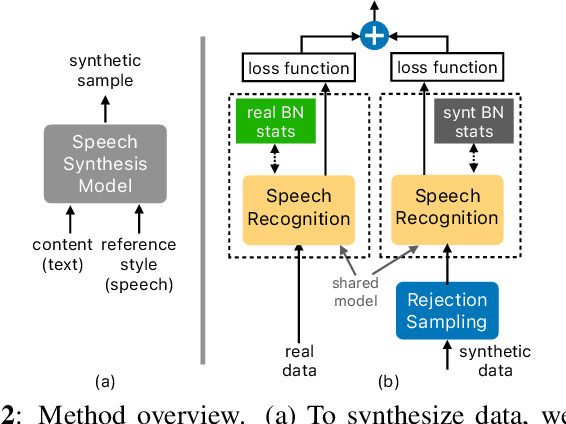
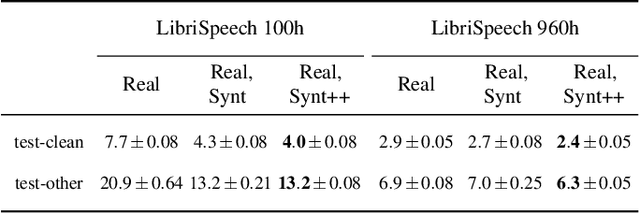
With recent advances in speech synthesis, synthetic data is becoming a viable alternative to real data for training speech recognition models. However, machine learning with synthetic data is not trivial due to the gap between the synthetic and the real data distributions. Synthetic datasets may contain artifacts that do not exist in real data such as structured noise, content errors, or unrealistic speaking styles. Moreover, the synthesis process may introduce a bias due to uneven sampling of the data manifold. We propose two novel techniques during training to mitigate the problems due to the distribution gap: (i) a rejection sampling algorithm and (ii) using separate batch normalization statistics for the real and the synthetic samples. We show that these methods significantly improve the training of speech recognition models using synthetic data. We evaluate the proposed approach on keyword detection and Automatic Speech Recognition (ASR) tasks, and observe up to 18% and 13% relative error reduction, respectively, compared to naively using the synthetic data.
SapAugment: Learning A Sample Adaptive Policy for Data Augmentation
Nov 02, 2020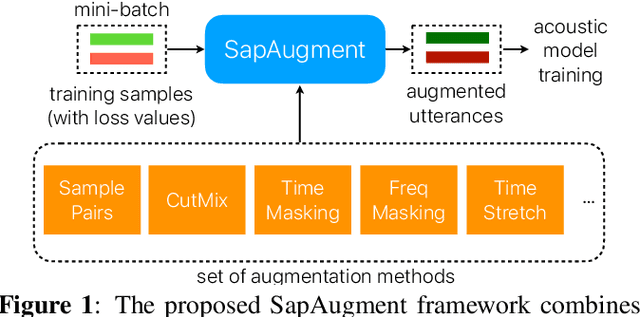
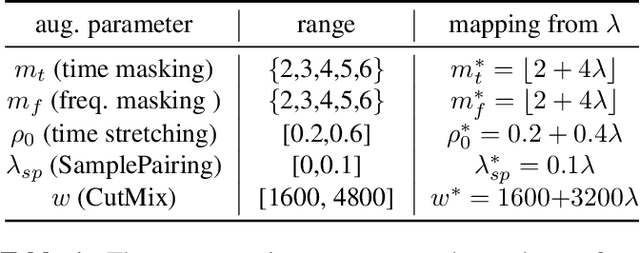
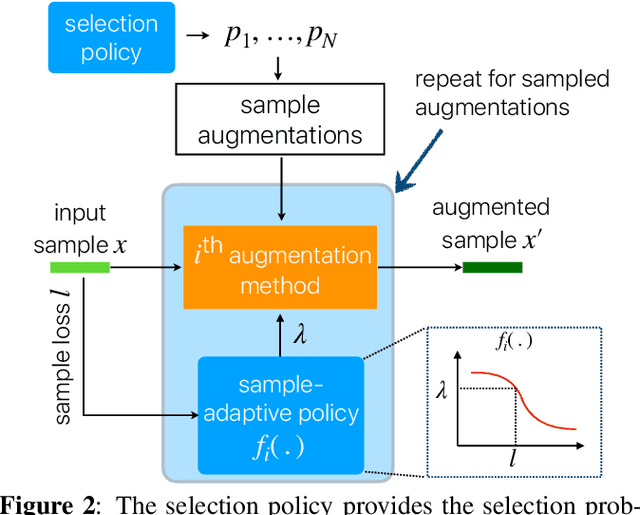
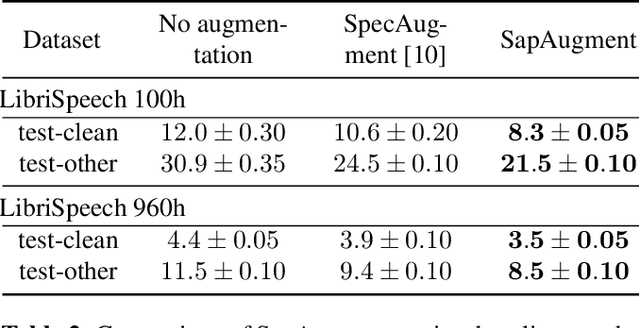
Data augmentation methods usually apply the same augmentation (or a mix of them) to all the training samples. For example, to perturb data with noise, the noise is sampled from a Normal distribution with a fixed standard deviation, for all samples. We hypothesize that a hard sample with high training loss already provides strong training signal to update the model parameters and should be perturbed with mild or no augmentation. Perturbing a hard sample with a strong augmentation may also make it too hard to learn from. Furthermore, a sample with low training loss should be perturbed by a stronger augmentation to provide more robustness to a variety of conditions. To formalize these intuitions, we propose a novel method to learn a Sample-Adaptive Policy for Augmentation -- SapAugment. Our policy adapts the augmentation parameters based on the training loss of the data samples. In the example of Gaussian noise, a hard sample will be perturbed with a low variance noise and an easy sample with a high variance noise. Furthermore, the proposed method combines multiple augmentation methods into a methodical policy learning framework and obviates hand-crafting augmentation parameters by trial-and-error. We apply our method on an automatic speech recognition (ASR) task, and combine existing and novel augmentations using the proposed framework. We show substantial improvement, up to 21% relative reduction in word error rate on LibriSpeech dataset, over the state-of-the-art speech augmentation method.