 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPGA Based Implementation of Deep Neural Networks Using On-chip Memory Only
Paper and Code
Aug 29, 2016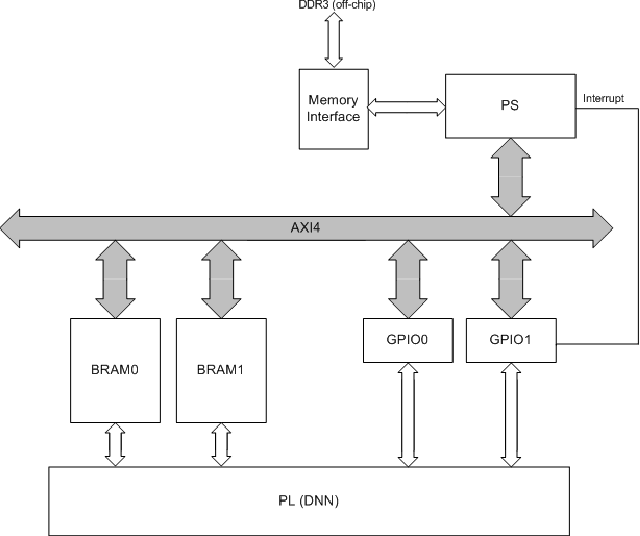



Deep neural networks (DNNs) demand a very large amount of computation and weight storage, and thus efficient implementation using special purpose hardware is highly desired. In this work, we have developed an FPGA based fixed-point DNN system using only on-chip memory not to access external DRAM. The execution time and energy consumption of the developed system is compared with a GPU based implementation. Since the capacity of memory in FPGA is limited, only 3-bit weights are used for this implementation, and training based fixed-point weight optimization is employed. The implementation using Xilinx XC7Z045 is tested for the MNIST handwritten digit recognition benchmark and a phoneme recognition task on TIMIT corpus. The obtained speed is about one quarter of a GPU based implementation and much better than that of a PC based one. The power consumption is less than 5 Watt at the full speed operation resulting in much higher efficiency compared to GPU based systems.