 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-based out-of-vocabulary word recovery for ASR systems in Indian languages
Jun 09, 2022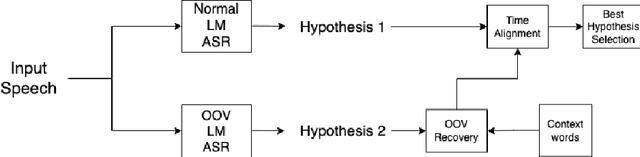
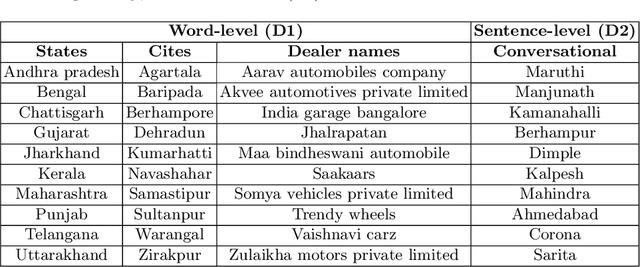
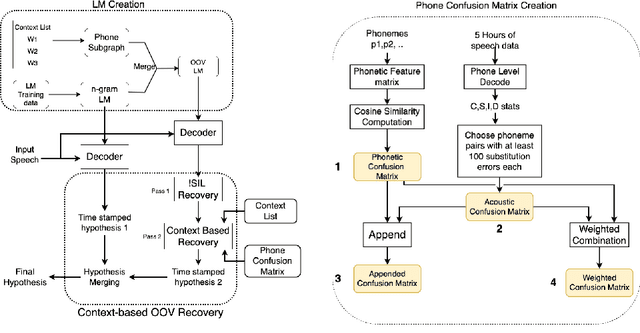
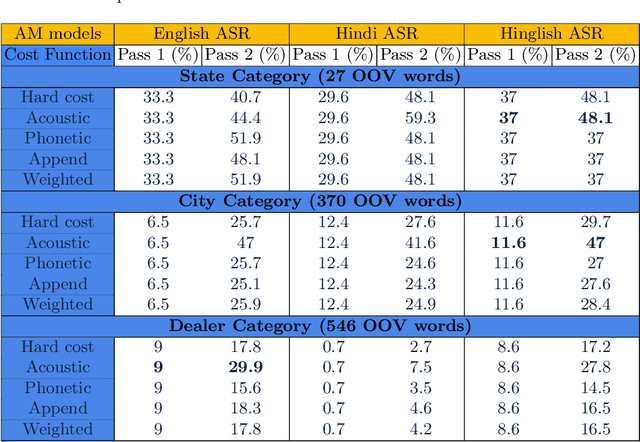
Detecting and recovering out-of-vocabulary (OOV) words is always challenging for Automatic Speech Recognition (ASR) systems. Many existing methods focus on modeling OOV words by modifying acoustic and language models and integrating context words cleverly into models. To train such complex models, we need a large amount of data with context words, additional training time, and increased model size. However, after getting the ASR transcription to recover context-based OOV words, the post-processing method has not been explored much. In this work, we propose a post-processing technique to improve the performance of context-based OOV recovery. We created an acoustically boosted language model with a sub-graph made at phone level with an OOV words list. We proposed two methods to determine a suitable cost function to retrieve the OOV words based on the context. The cost function is defined based on phonetic and acoustic knowledge for matching and recovering the correct context words in the decode. The effectiveness of the proposed cost function is evaluated at both word-level and sentence-level. The evaluation results show that this approach can recover an average of 50% context-based OOV words across multiple categories.