 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to train your sound source localizer
Nov 30, 2022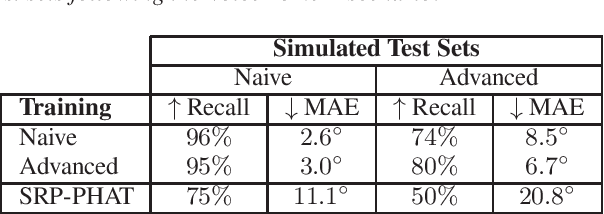

Learning-based methods have become ubiquitous in sound source localization (SSL). Existing systems rely on simulated training sets for the lack of sufficiently large, diverse and annotated real datasets. Most room acoustic simulators used for this purpose rely on the image source method (ISM) because of its computational efficiency. This paper argues that carefully extending the ISM to incorporate more realistic surface, source and microphone responses into training sets can significantly boost the real-world performance of SSL systems. It is shown that increasing the training-set realism of a state-of-the-art direction-of-arrival estimator yields consistent improvements across three different real test sets featuring human speakers in a variety of rooms and various microphone arrays. An ablation study further reveals that every added layer of realism contributes positively to these improvements.
Realistic sources, receivers and walls improve the generalisability of virtually-supervised blind acoustic parameter estimators
Jul 19, 2022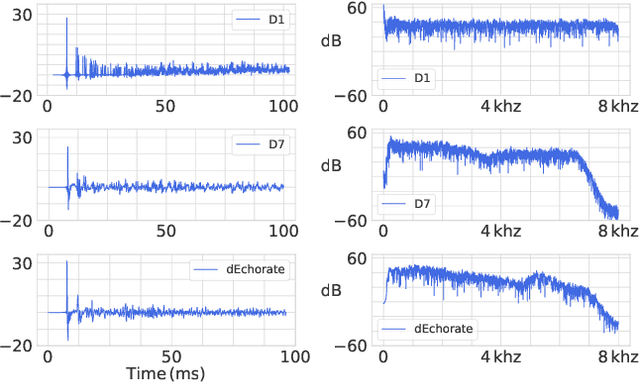

Blind acoustic parameter estimation consists in inferring the acoustic properties of an environment from recordings of unknown sound sources. Recent works in this area have utilized deep neural networks trained either partially or exclusively on simulated data, due to the limited availability of real annotated measurements. In this paper, we study whether a model purely trained using a fast image-source room impulse response simulator can generalize to real data. We present an ablation study on carefully crafted simulated training sets that account for different levels of realism in source, receiver and wall responses. The extent of realism is controlled by the sampling of wall absorption coefficients and by applying measured directivity patterns to microphones and sources. A state-of-the-art model trained on these datasets is evaluated on the task of jointly estimating the room's volume, total surface area, and octave-band reverberation times from multiple, multichannel speech recordings. Results reveal that every added layer of simulation realism at train time significantly improves the estimation of all quantities on real signals.
Blind Room Parameter Estimation Using Multiple-Multichannel Speech Recordings
Jul 29, 2021
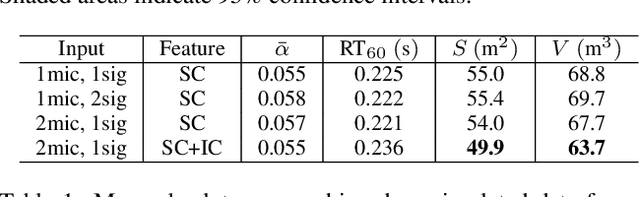

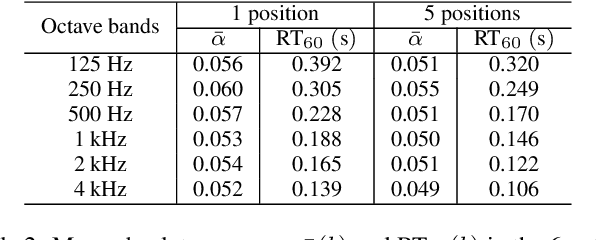
Knowing the geometrical and acoustical parameters of a room may benefit applications such as audio augmented reality, speech dereverberation or audio forensics. In this paper, we study the problem of jointly estimating the total surface area, the volume, as well as the frequency-dependent reverberation time and mean surface absorption of a room in a blind fashion, based on two-channel noisy speech recordings from multiple, unknown source-receiver positions. A novel convolutional neural network architecture leveraging both single- and inter-channel cues is proposed and trained on a large, realistic simulated dataset. Results on both simulated and real data show that using multiple observations in one room significantly reduces estimation errors and variances on all target quantities, and that using two channels helps the estimation of surface and volume. The proposed model outperforms a recently proposed blind volume estimation method on the considered datasets.
SALADnet: Self-Attentive multisource Localization in the Ambisonics Domain
Jul 23, 2021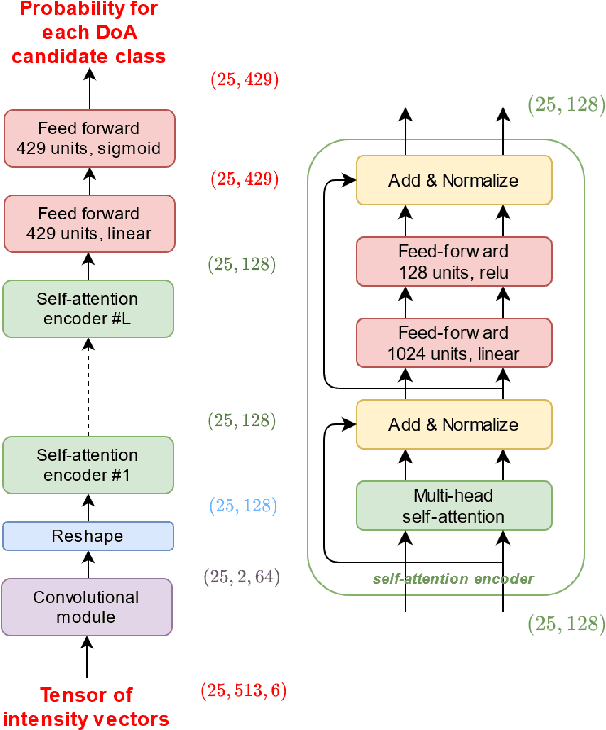
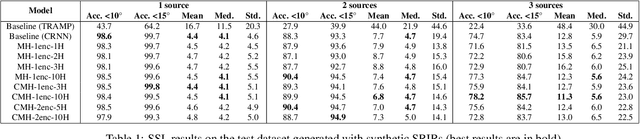
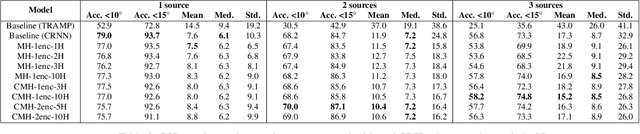
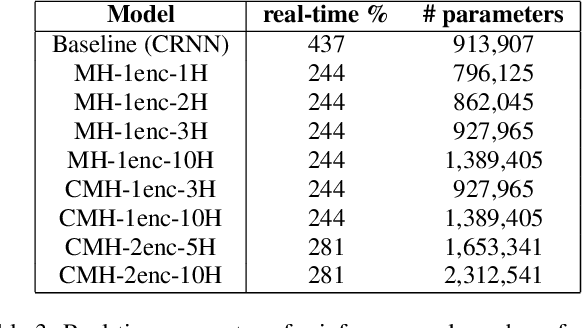
In this work, we propose a novel self-attention based neural network for robust multi-speaker localization from Ambisonics recordings. Starting from a state-of-the-art convolutional recurrent neural network, we investigate the benefit of replacing the recurrent layers by self-attention encoders, inherited from the Transformer architecture. We evaluate these models on synthetic and real-world data, with up to 3 simultaneous speakers. The obtained results indicate that the majority of the proposed architectures either perform on par, or outperform the CRNN baseline, especially in the multisource scenario. Moreover, by avoiding the recurrent layers, the proposed models lend themselves to parallel computing, which is shown to produce considerable savings in execution time.
A Dataset of Dynamic Reverberant Sound Scenes with Directional Interferers for Sound Event Localization and Detection
Jul 04, 2021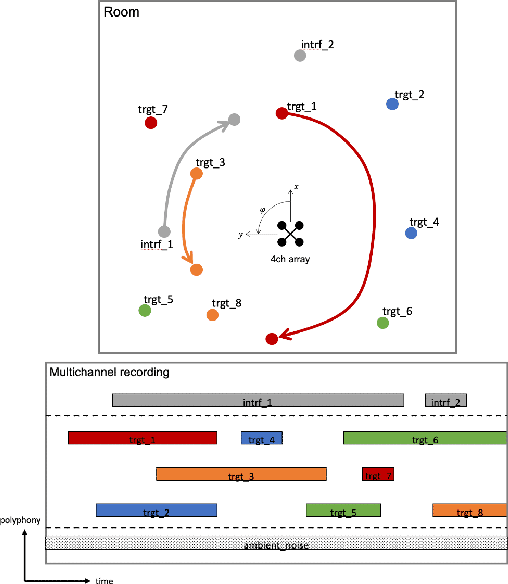

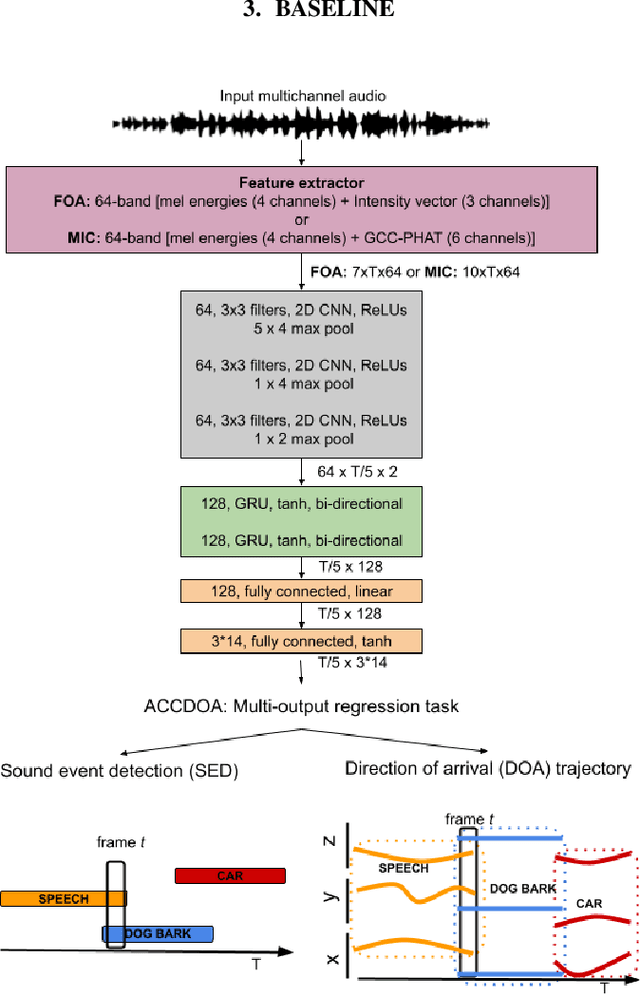
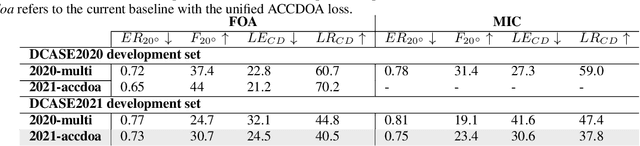
This report presents the dataset and baseline of Task 3 of the DCASE2021 Challenge on Sound Event Localization and Detection (SELD). The dataset is based on emulation of real recordings of static or moving sound events under real conditions of reverberation and ambient noise, using spatial room impulse responses captured in a variety of rooms and delivered in two spatial formats. The acoustical synthesis remains the same as in the previous iteration of the challenge, however the new dataset brings more challenging conditions of polyphony and overlapping instances of the same class. The most important difference of the new dataset is the introduction of directional interferers, meaning sound events that are localized in space but do not belong to the target classes to be detected and are not annotated. Since such interfering events are expected in every real-world scenario of SELD, the new dataset aims to promote systems that deal with this condition effectively. A modified SELDnet baseline employing the recent ACCDOA representation of SELD problems accompanies the dataset and it is shown to outperform the previous one. The new dataset is shown to be significantly more challenging for both baselines according to all considered metrics. To investigate the individual and combined effects of ambient noise, interferers, and reverberation, we study the performance of the baseline on different versions of the dataset excluding or including combinations of these factors. The results indicate that by far the most detrimental effects are caused by directional interferers.