 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSALADnet: Self-Attentive multisource Localization in the Ambisonics Domain
Jul 23, 2021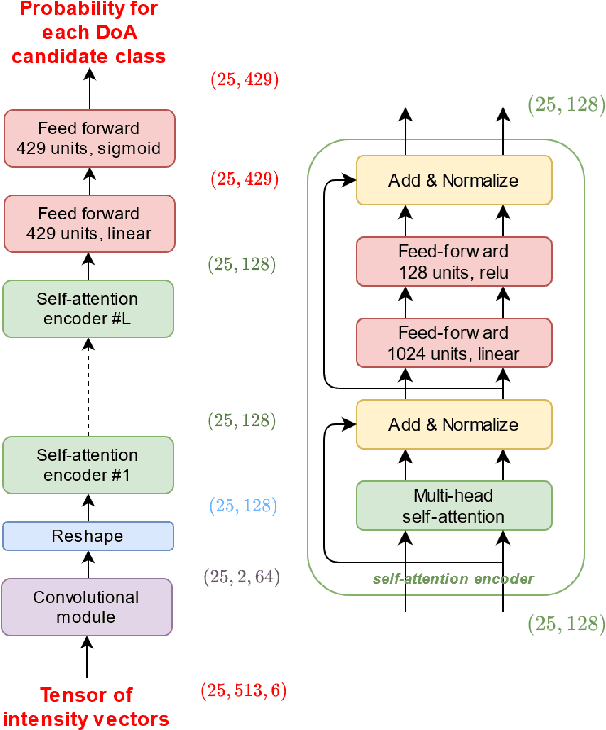
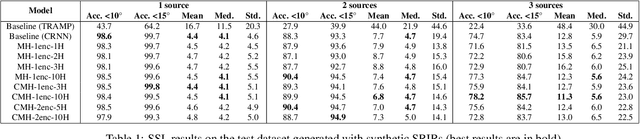
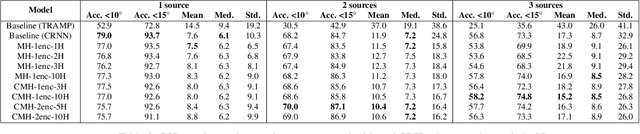
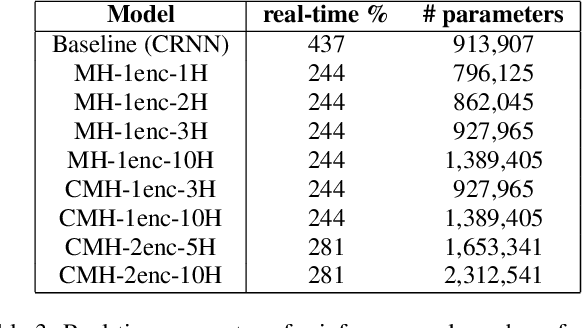
In this work, we propose a novel self-attention based neural network for robust multi-speaker localization from Ambisonics recordings. Starting from a state-of-the-art convolutional recurrent neural network, we investigate the benefit of replacing the recurrent layers by self-attention encoders, inherited from the Transformer architecture. We evaluate these models on synthetic and real-world data, with up to 3 simultaneous speakers. The obtained results indicate that the majority of the proposed architectures either perform on par, or outperform the CRNN baseline, especially in the multisource scenario. Moreover, by avoiding the recurrent layers, the proposed models lend themselves to parallel computing, which is shown to produce considerable savings in execution time.
Improved feature extraction for CRNN-based multiple sound source localization
May 05, 2021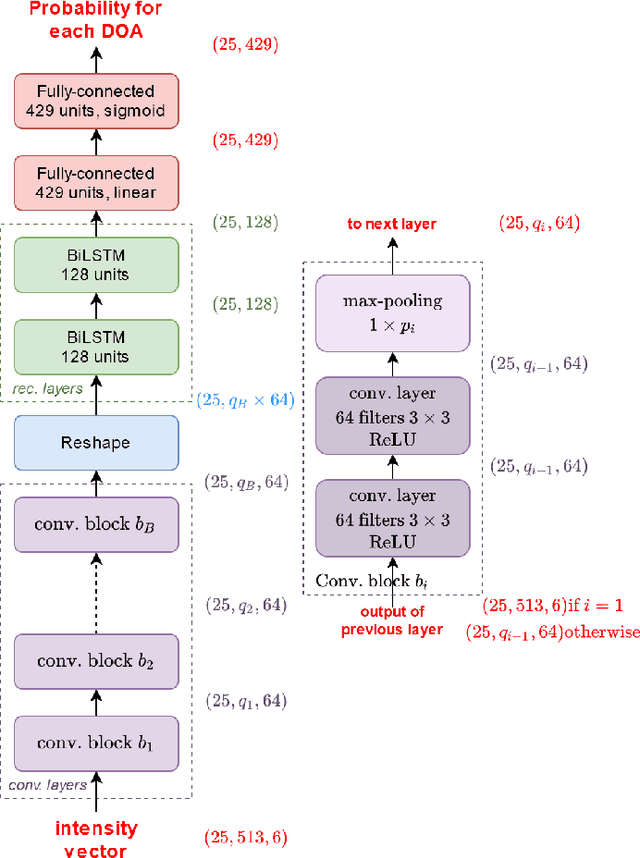
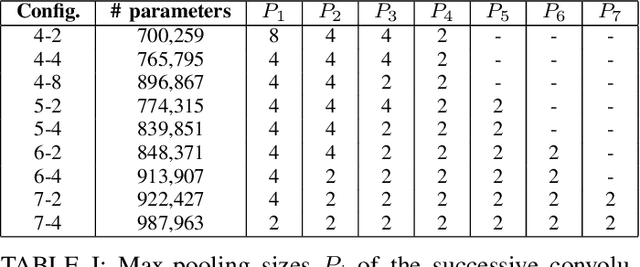


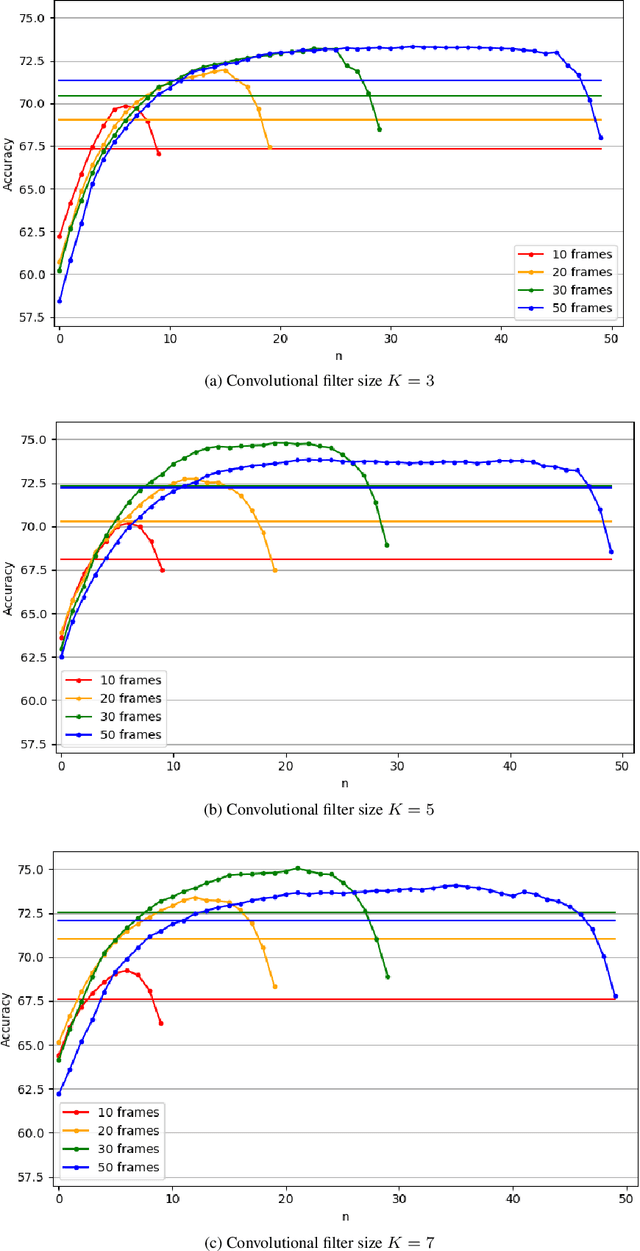
In this work, we propose to extend a state-of-the-art multi-source localization system based on a convolutional recurrent neural network and Ambisonics signals. We significantly improve the performance of the baseline network by changing the layout between convolutional and pooling layers. We propose several configurations with more convolutional layers and smaller pooling sizes in-between, so that less information is lost across the layers, leading to a better feature extraction. In parallel, we test the system's ability to localize up to 3 sources, in which case the improved feature extraction provides the most significant boost in accuracy. We evaluate and compare these improved configurations on synthetic and real-world data. The obtained results show a quite substantial improvement of the multiple sound source localization performance over the baseline network.
Multichannel CRNN for Speaker Counting: an Analysis of Performance
Jan 06, 2021
Speaker counting is the task of estimating the number of people that are simultaneously speaking in an audio recording. For several audio processing tasks such as speaker diarization, separation, localization and tracking, knowing the number of speakers at each timestep is a prerequisite, or at least it can be a strong advantage, in addition to enabling a low latency processing. In a previous work, we addressed the speaker counting problem with a multichannel convolutional recurrent neural network which produces an estimation at a short-term frame resolution. In this work, we show that, for a given frame, there is an optimal position in the input sequence for best prediction accuracy. We empirically demonstrate the link between that optimal position, the length of the input sequence and the size of the convolutional filters.
Unifying local and non-local signal processing with graph CNNs
Jul 07, 2017

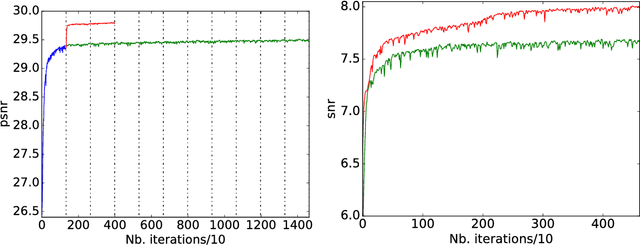

This paper deals with the unification of local and non-local signal processing on graphs within a single convolutional neural network (CNN) framework. Building upon recent works on graph CNNs, we propose to use convolutional layers that take as inputs two variables, a signal and a graph, allowing the network to adapt to changes in the graph structure. In this article, we explain how this framework allows us to design a novel method to perform style transfer.