 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultichannel CRNN for Speaker Counting: an Analysis of Performance
Paper and Code
Jan 06, 2021
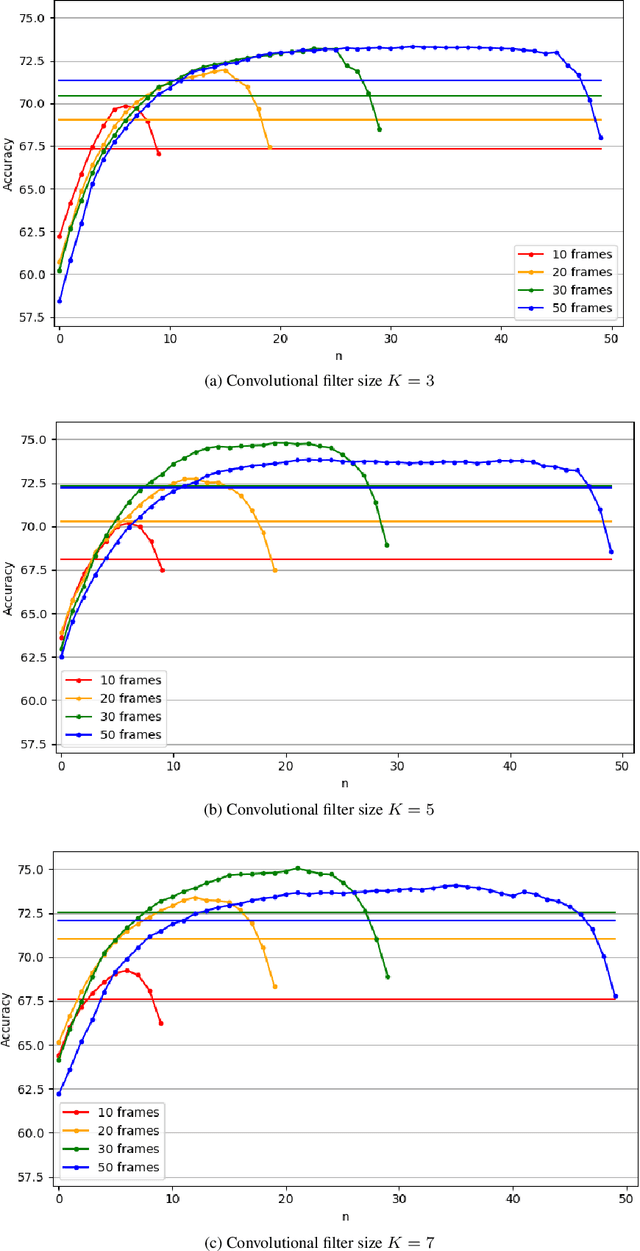
Speaker counting is the task of estimating the number of people that are simultaneously speaking in an audio recording. For several audio processing tasks such as speaker diarization, separation, localization and tracking, knowing the number of speakers at each timestep is a prerequisite, or at least it can be a strong advantage, in addition to enabling a low latency processing. In a previous work, we addressed the speaker counting problem with a multichannel convolutional recurrent neural network which produces an estimation at a short-term frame resolution. In this work, we show that, for a given frame, there is an optimal position in the input sequence for best prediction accuracy. We empirically demonstrate the link between that optimal position, the length of the input sequence and the size of the convolutional filters.