 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient bandwidth extension of musical signals using a differentiable harmonic plus noise model
Nov 27, 2023The task of bandwidth extension addresses the generation of missing high frequencies of audio signals based on knowledge of the low-frequency part of the sound. This task applies to various problems, such as audio coding or audio restoration. In this article, we focus on efficient bandwidth extension of monophonic and polyphonic musical signals using a differentiable digital signal processing (DDSP) model. Such a model is composed of a neural network part with relatively few parameters trained to infer the parameters of a differentiable digital signal processing model, which efficiently generates the output full-band audio signal. We first address bandwidth extension of monophonic signals, and then propose two methods to explicitely handle polyphonic signals. The benefits of the proposed models are first demonstrated on monophonic and polyphonic synthetic data against a baseline and a deep-learning-based resnet model. The models are next evaluated on recorded monophonic and polyphonic data, for a wide variety of instruments and musical genres. We show that all proposed models surpass a higher complexity deep learning model for an objective metric computed in the frequency domain. A MUSHRA listening test confirms the superiority of the proposed approach in terms of perceptual quality.
A Survey of Sound Source Localization with Deep Learning Methods
Sep 16, 2021

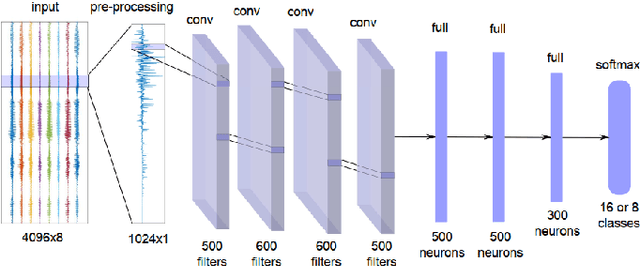
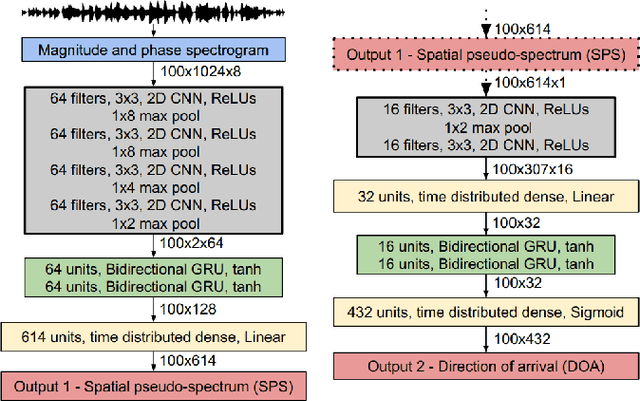
This article is a survey on deep learning methods for single and multiple sound source localization. We are particularly interested in sound source localization in indoor/domestic environment, where reverberation and diffuse noise are present. We provide an exhaustive topography of the neural-based localization literature in this context, organized according to several aspects: the neural network architecture, the type of input features, the output strategy (classification or regression), the types of data used for model training and evaluation, and the model training strategy. This way, an interested reader can easily comprehend the vast panorama of the deep learning-based sound source localization methods. Tables summarizing the literature survey are provided at the end of the paper for a quick search of methods with a given set of target characteristics.
SALADnet: Self-Attentive multisource Localization in the Ambisonics Domain
Jul 23, 2021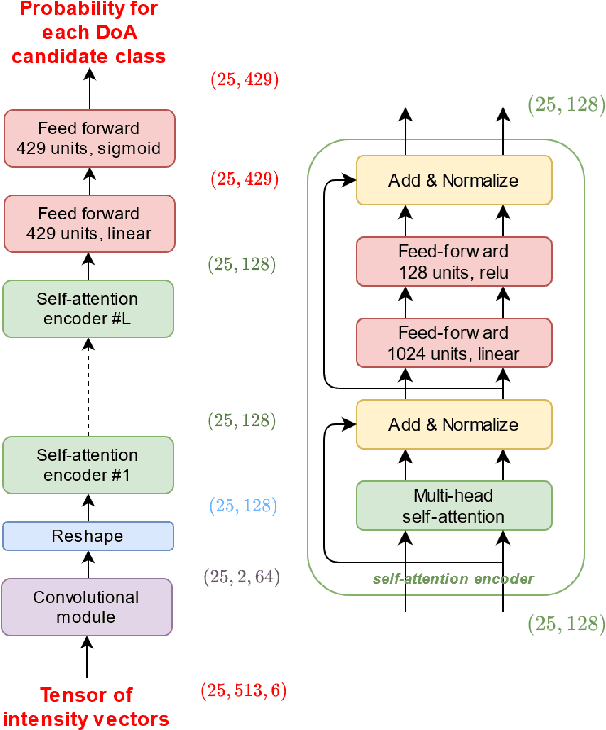
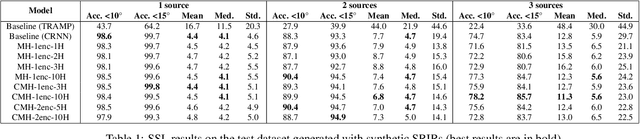
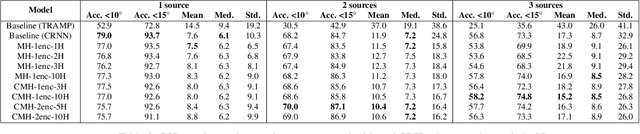
In this work, we propose a novel self-attention based neural network for robust multi-speaker localization from Ambisonics recordings. Starting from a state-of-the-art convolutional recurrent neural network, we investigate the benefit of replacing the recurrent layers by self-attention encoders, inherited from the Transformer architecture. We evaluate these models on synthetic and real-world data, with up to 3 simultaneous speakers. The obtained results indicate that the majority of the proposed architectures either perform on par, or outperform the CRNN baseline, especially in the multisource scenario. Moreover, by avoiding the recurrent layers, the proposed models lend themselves to parallel computing, which is shown to produce considerable savings in execution time.
Improved feature extraction for CRNN-based multiple sound source localization
May 05, 2021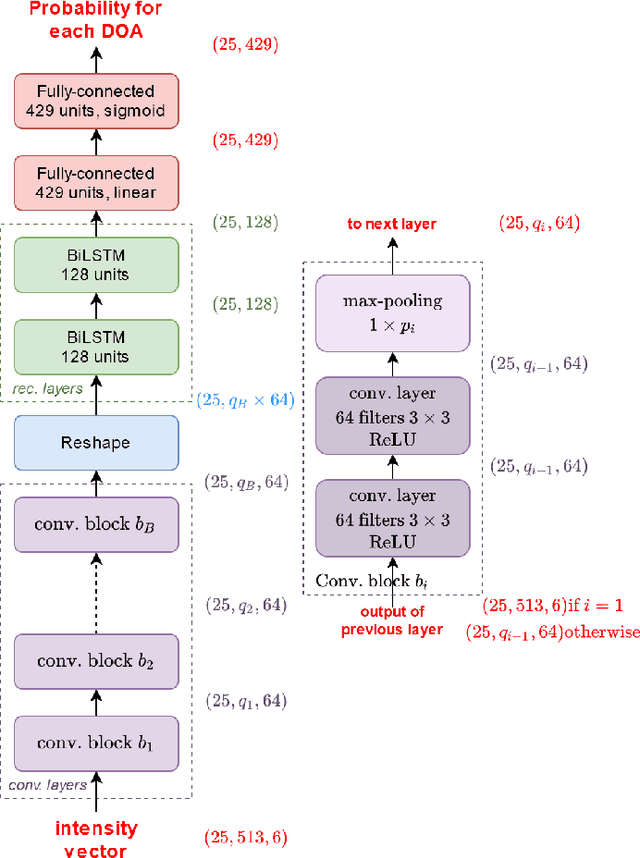
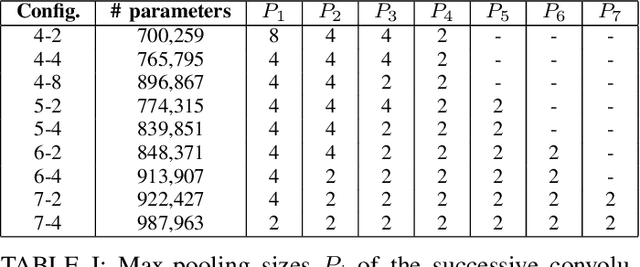


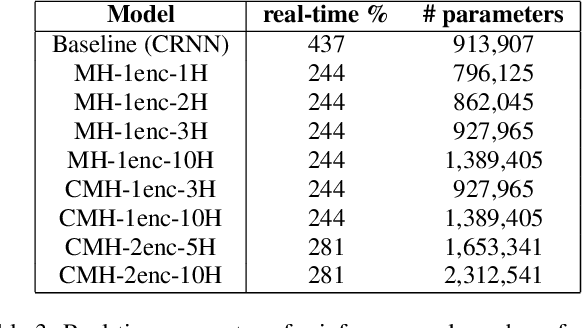
In this work, we propose to extend a state-of-the-art multi-source localization system based on a convolutional recurrent neural network and Ambisonics signals. We significantly improve the performance of the baseline network by changing the layout between convolutional and pooling layers. We propose several configurations with more convolutional layers and smaller pooling sizes in-between, so that less information is lost across the layers, leading to a better feature extraction. In parallel, we test the system's ability to localize up to 3 sources, in which case the improved feature extraction provides the most significant boost in accuracy. We evaluate and compare these improved configurations on synthetic and real-world data. The obtained results show a quite substantial improvement of the multiple sound source localization performance over the baseline network.
Multichannel CRNN for Speaker Counting: an Analysis of Performance
Jan 06, 2021
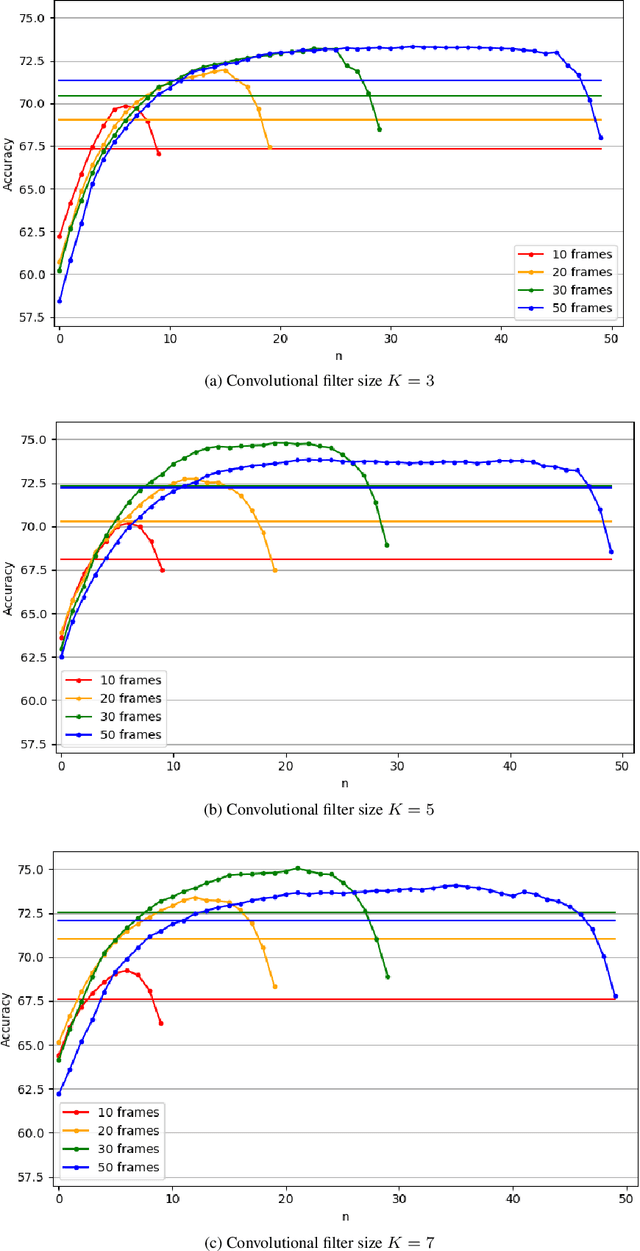
Speaker counting is the task of estimating the number of people that are simultaneously speaking in an audio recording. For several audio processing tasks such as speaker diarization, separation, localization and tracking, knowing the number of speakers at each timestep is a prerequisite, or at least it can be a strong advantage, in addition to enabling a low latency processing. In a previous work, we addressed the speaker counting problem with a multichannel convolutional recurrent neural network which produces an estimation at a short-term frame resolution. In this work, we show that, for a given frame, there is an optimal position in the input sequence for best prediction accuracy. We empirically demonstrate the link between that optimal position, the length of the input sequence and the size of the convolutional filters.