 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind identification of Ambisonic reduced room impulse response
May 05, 2023



Recently proposed Generalized Time-domain Velocity Vector (GTVV) is a generalization of relative room impulse response in spherical harmonic (aka Ambisonic) domain that allows for blind estimation of early-echo parameters: the directions and relative delays of individual reflections. However, the derived closed-form expression of GTVV mandates few assumptions to hold, most important being that the impulse response of the reference signal needs to be a minimum-phase filter. In practice, the reference is obtained by spatial filtering towards the Direction-of-Arrival of the source, and the aforementioned condition is bounded by the performance of the applied beamformer (and thus, by the Ambisonic array order). In the present work, we suggest to circumvent this problem by properly modelling the GTVV time series, which permits not only to relax the initial assumptions, but also to extract the information therein is a more consistent and efficient manner, entering the realm of blind system identification. Experiments using measured room impulse responses confirm the effectiveness of the proposed approach.
Echo-enabled Direction-of-Arrival and range estimation of a mobile source in Ambisonic domain
Mar 10, 2022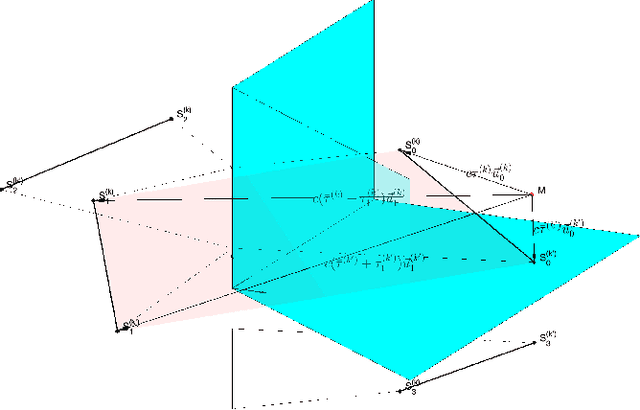
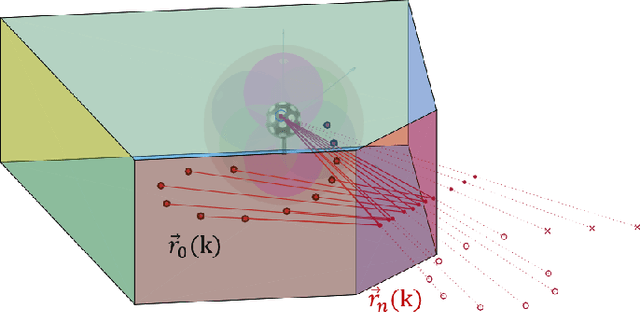
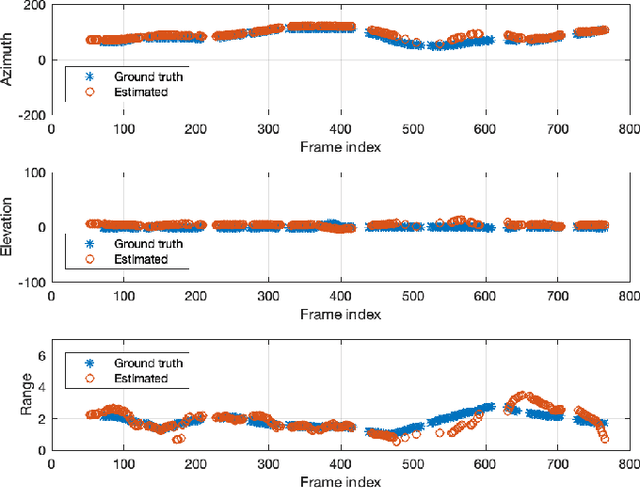
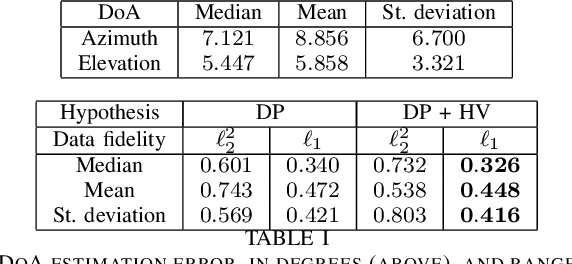
Range estimation of a far field sound source in a reverberant environment is known to be a notoriously difficult problem, hence most localization methods are only capable of estimating the source's Direction-of-Arrival (DoA). In an earlier work, we have demonstrated that, under certain restrictive acoustic conditions and given the orientation of a reflecting surface, one can exploit the dominant acoustic reflection to evaluate the DoA \emph{and} the distance to a static sound source in Ambisonic domain. In this article, we leverage the recently presented Generalized Time-domain Velocity Vector (GTVV) representation to estimate these quantities for a moving sound source without an a priori knowledge of reflectors' orientations. We show that the trajectories of a moving source and the corresponding reflections are spatially and temporally related, which can be used to infer the absolute delay of the propagating source signal and, therefore, approximate the microphone-to-source distance. Experiments on real sound data confirm the validity of the proposed approach.
Generalized Time Domain Velocity Vector
Oct 17, 2021

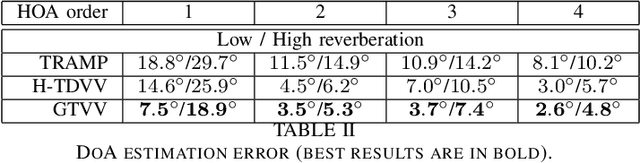
We introduce and analyze Generalized Time Domain Velocity Vector (GTVV), an extension of the previously presented acoustic multipath footprint extracted from the Ambisonic recordings. GTVV is better adapted to adverse acoustic conditions, and enables efficient parameter estimation of multiple plane wave components in the recorded multichannel mixture. Experiments on simulated data confirm the predicted theoretical advantages of these new spatio-temporal features.
A Survey of Sound Source Localization with Deep Learning Methods
Sep 16, 2021

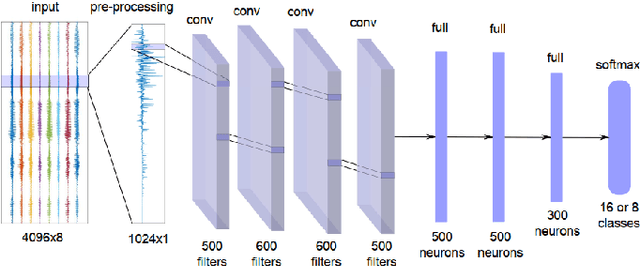
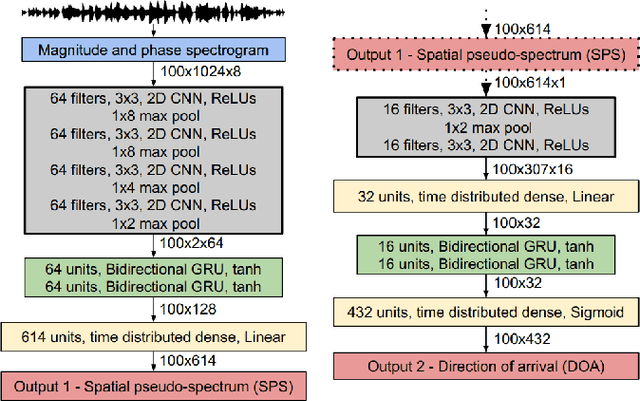
This article is a survey on deep learning methods for single and multiple sound source localization. We are particularly interested in sound source localization in indoor/domestic environment, where reverberation and diffuse noise are present. We provide an exhaustive topography of the neural-based localization literature in this context, organized according to several aspects: the neural network architecture, the type of input features, the output strategy (classification or regression), the types of data used for model training and evaluation, and the model training strategy. This way, an interested reader can easily comprehend the vast panorama of the deep learning-based sound source localization methods. Tables summarizing the literature survey are provided at the end of the paper for a quick search of methods with a given set of target characteristics.
Scattering Features for Multimodal Gait Recognition
Jan 23, 2020
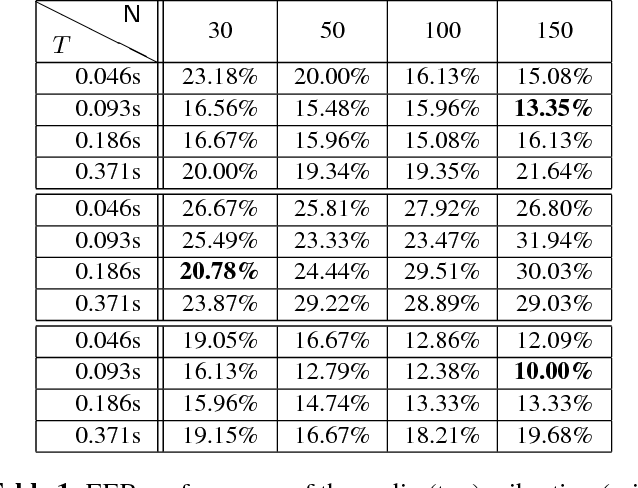
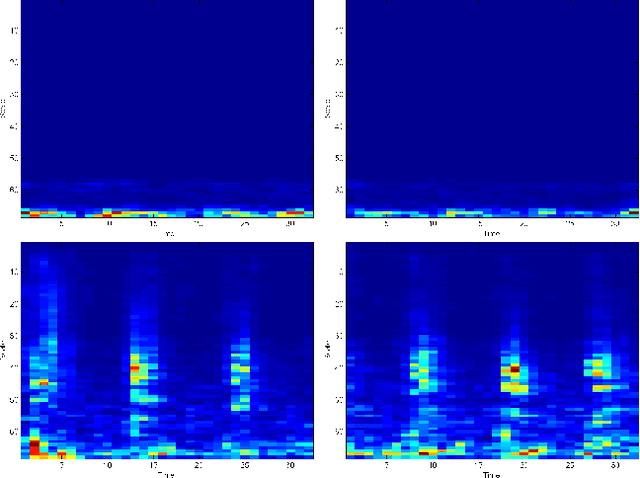
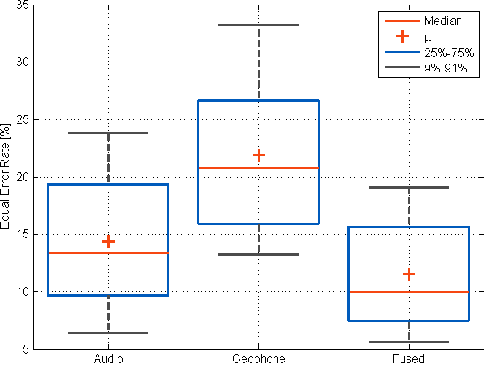
We consider the problem of identifying people on the basis of their walk (gait) pattern. Classical approaches to tackle this problem are based on, e.g., video recordings or piezoelectric sensors embedded in the floor. In this work, we rely on acoustic and vibration measurements, obtained from a microphone and a geophone sensor, respectively. The contribution of this work is twofold. First, we propose a feature extraction method based on an (untrained) shallow scattering network, specially tailored for the gait signals. Second, we demonstrate that fusing the two modalities improves identification in the practically relevant open set scenario.