 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Production-Scale OCR for India: Multilingual and Domain-Specific Systems
Feb 18, 2026Designing Optical Character Recognition (OCR) systems for India requires balancing linguistic diversity, document heterogeneity, and deployment constraints. In this paper, we study two training strategies for building multilingual OCR systems with Vision-Language Models through the Chitrapathak series. We first follow a popular multimodal approach, pairing a generic vision encoder with a strong multilingual language model and training the system end-to-end for OCR. Alternatively, we explore fine-tuning an existing OCR model, despite not being trained for the target languages. Through extensive evaluation on multilingual Indic OCR benchmarks and deployment-oriented metrics, we find that the second strategy consistently achieves better accuracy-latency trade-offs. Chitrapathak-2 achieves 3-6x speedup over its predecessor with being state-of-the-art (SOTA) in Telugu (6.69 char ANLS) and second best in the rest. In addition, we present Parichay, an independent OCR model series designed specifically for 9 Indian government documents to extract structured key fields, achieving 89.8% Exact Match score with a faster inference. Together, these systems achieve SOTA performance and provide practical guidance for building production-scale OCR pipelines in the Indian context.
BhashaKritika: Building Synthetic Pretraining Data at Scale for Indic Languages
Nov 16, 2025In the context of pretraining of Large Language Models (LLMs), synthetic data has emerged as an alternative for generating high-quality pretraining data at scale. This is particularly beneficial in low-resource language settings where the benefits of recent LLMs have been unevenly distributed across languages. In this work, we present a systematic study on the generation and evaluation of synthetic multilingual pretraining data for Indic languages, where we construct a large-scale synthetic dataset BhashaKritika, comprising 540B tokens using 5 different techniques for 10 languages. We explore the impact of grounding generation in documents, personas, and topics. We analyze how language choice, both in the prompt instructions and document grounding, affects data quality, and we compare translations of English content with native generation in Indic languages. To support scalable and language-sensitive evaluation, we introduce a modular quality evaluation pipeline that integrates script and language detection, metadata consistency checks, n-gram repetition analysis, and perplexity-based filtering using KenLM models. Our framework enables robust quality control across diverse scripts and linguistic contexts. Empirical results through model runs reveal key trade-offs in generation strategies and highlight best practices for constructing effective multilingual corpora.
VoiceAgentBench: Are Voice Assistants ready for agentic tasks?
Oct 09, 2025
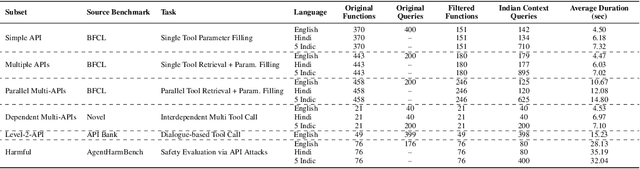
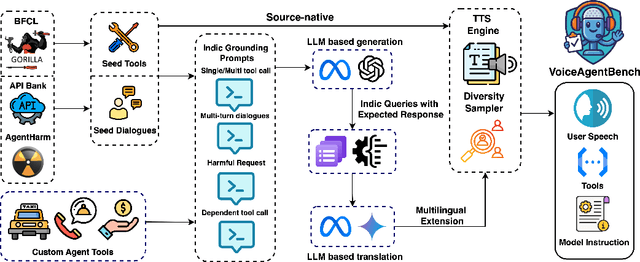
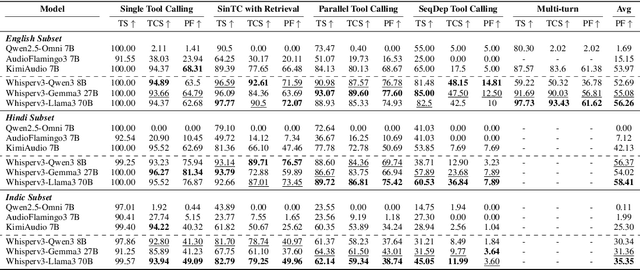
Large-scale Speech Language Models (SpeechLMs) have enabled voice assistants capable of understanding natural spoken queries and performing complex tasks. However, existing speech benchmarks primarily focus on isolated capabilities such as transcription, or question-answering, and do not systematically evaluate agentic scenarios encompassing multilingual and cultural understanding, as well as adversarial robustness. To address this, we introduce VoiceAgentBench, a comprehensive benchmark designed to evaluate SpeechLMs in realistic spoken agentic settings. It comprises over 5,500 synthetic spoken queries, including dialogues grounded in Indian context, covering single-tool invocations, multi-tool workflows, multi-turn interactions, and safety evaluations. The benchmark supports English, Hindi, and 5 other Indian languages, reflecting real-world linguistic and cultural diversity. We simulate speaker variability using a novel sampling algorithm that selects audios for TTS voice conversion based on its speaker embeddings, maximizing acoustic and speaker diversity. Our evaluation measures tool selection accuracy, structural consistency, and the correctness of tool invocations, including adversarial robustness. Our experiments reveal significant gaps in contextual tool orchestration tasks, Indic generalization, and adversarial robustness, exposing critical limitations of current SpeechLMs.
Pragyaan: Designing and Curating High-Quality Cultural Post-Training Datasets for Indian Languages
Oct 08, 2025The effectiveness of Large Language Models (LLMs) depends heavily on the availability of high-quality post-training data, particularly instruction-tuning and preference-based examples. Existing open-source datasets, however, often lack multilingual coverage, cultural grounding, and suffer from task diversity gaps that are especially pronounced for Indian languages. We introduce a human-in-the-loop pipeline that combines translations with synthetic expansion to produce reliable and diverse Indic post-training data. Using this pipeline, we curate two datasets: Pragyaan-IT (22.5K) and Pragyaan-Align (100K) across 10 Indian languages covering 13 broad and 56 sub-categories, leveraging 57 diverse datasets. Our dataset protocol incorporates several often-overlooked dimensions and emphasize task diversity, multi-turn dialogue, instruction fidelity, safety alignment, and preservation of cultural nuance, providing a foundation for more inclusive and effective multilingual LLMs.
Chitranuvad: Adapting Multi-Lingual LLMs for Multimodal Translation
Feb 27, 2025In this work, we provide the system description of our submission as part of the English to Lowres Multimodal Translation Task at the Workshop on Asian Translation (WAT2024). We introduce Chitranuvad, a multimodal model that effectively integrates Multilingual LLM and a vision module for Multimodal Translation. Our method uses a ViT image encoder to extract visual representations as visual token embeddings which are projected to the LLM space by an adapter layer and generates translation in an autoregressive fashion. We participated in all the three tracks (Image Captioning, Text only and Multimodal translation tasks) for Indic languages (ie. English translation to Hindi, Bengali and Malyalam) and achieved SOTA results for Hindi in all of them on the Challenge set while remaining competitive for the other languages in the shared task.
MATHSENSEI: A Tool-Augmented Large Language Model for Mathematical Reasoning
Feb 27, 2024



Tool-augmented Large Language Models (TALM) are known to enhance the skillset of large language models (LLM), thereby, leading to their improved reasoning abilities across many tasks. While, TALMs have been successfully employed in different question-answering benchmarks, their efficacy on complex mathematical reasoning benchmarks, and the potential complimentary benefits offered by tools for knowledge retrieval and mathematical equation solving, are open research questions. In this work, we present MATHSENSEI, a tool-augmented large language model for mathematical reasoning. Augmented with tools for knowledge retrieval (Bing Web Search), program execution (Python), and symbolic equation solving (Wolfram-Alpha), we study the complimentary benefits of these tools through evaluations on mathematical reasoning datasets. We perform exhaustive ablations on MATH,a popular dataset for evaluating mathematical reasoning on diverse mathematical disciplines. We also conduct experiments involving well-known tool planners to study the impact of tool sequencing on the model performance. MATHSENSEI achieves 13.5% better accuracy over gpt-3.5-turbo with chain-of-thought on the MATH dataset. We further observe that TALMs are not as effective for simpler math word problems (in GSM-8k), and the benefit increases as the complexity and required knowledge increases (progressively over AQuA, MMLU-Math, and higher level complex questions in MATH). The code and data are available at https://github.com/Debrup-61/MathSensei.
MFBE: Leveraging Multi-Field Information of FAQs for Efficient Dense Retrieval
Feb 23, 2023In the domain of question-answering in NLP, the retrieval of Frequently Asked Questions (FAQ) is an important sub-area which is well researched and has been worked upon for many languages. Here, in response to a user query, a retrieval system typically returns the relevant FAQs from a knowledge-base. The efficacy of such a system depends on its ability to establish semantic match between the query and the FAQs in real-time. The task becomes challenging due to the inherent lexical gap between queries and FAQs, lack of sufficient context in FAQ titles, scarcity of labeled data and high retrieval latency. In this work, we propose a bi-encoder-based query-FAQ matching model that leverages multiple combinations of FAQ fields (like, question, answer, and category) both during model training and inference. Our proposed Multi-Field Bi-Encoder (MFBE) model benefits from the additional context resulting from multiple FAQ fields and performs well even with minimal labeled data. We empirically support this claim through experiments on proprietary as well as open-source public datasets in both unsupervised and supervised settings. Our model achieves around 27% and 20% better top-1 accuracy for the FAQ retrieval task on internal and open datasets, respectively over the best performing baseline.
Improving Speech Prosody of Audiobook Text-to-Speech Synthesis with Acoustic and Textual Contexts
Nov 04, 2022



We present a multi-speaker Japanese audiobook text-to-speech (TTS) system that leverages multimodal context information of preceding acoustic context and bilateral textual context to improve the prosody of synthetic speech. Previous work either uses unilateral or single-modality context, which does not fully represent the context information. The proposed method uses an acoustic context encoder and a textual context encoder to aggregate context information and feeds it to the TTS model, which enables the model to predict context-dependent prosody. We conducted comprehensive objective and subjective evaluations on a multi-speaker Japanese audiobook dataset. Experimental results demonstrate that the proposed method significantly outperforms two previous works. Additionally, we present insights about the different choices of context - modalities, lateral information and length - for audiobook TTS that have never been discussed in the literature before.
Extraction of Product Specifications from the Web -- Going Beyond Tables and Lists
Jan 08, 2022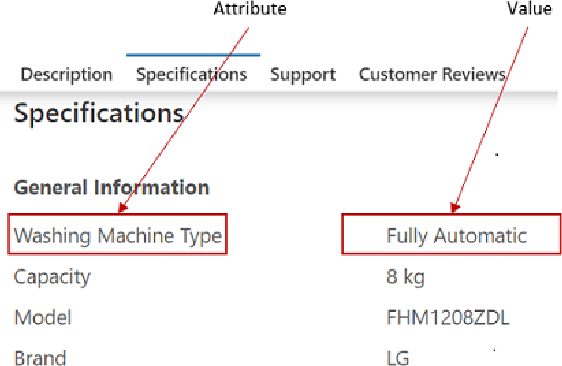
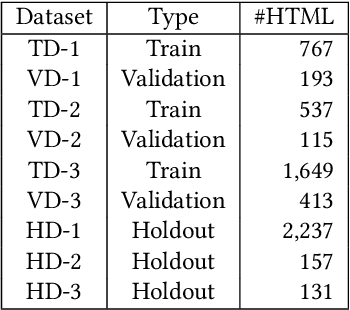

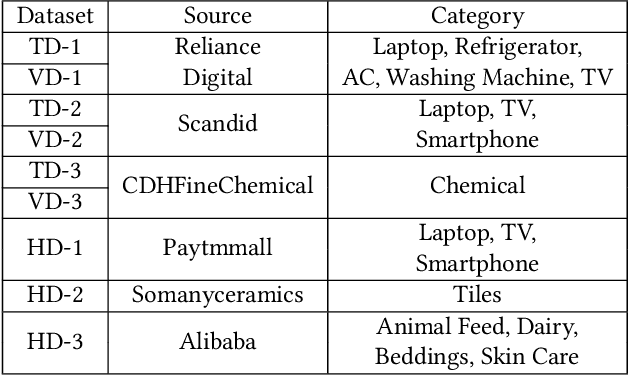
E-commerce product pages on the web often present product specification data in structured tabular blocks. Extraction of these product attribute-value specifications has benefited applications like product catalogue curation, search, question answering, and others. However, across different Websites, there is a wide variety of HTML elements (like <table>, <ul>, <div>, <span>, <dl> etc.) typically used to render these blocks that makes their automatic extraction a challenge. Most of the current research has focused on extracting product specifications from tables and lists and, therefore, suffers from recall when applied to a large-scale extraction setting. In this paper, we present a product specification extraction approach that goes beyond tables or lists and generalizes across the diverse HTML elements used for rendering specification blocks. Using a combination of hand-coded features and deep learned spatial and token features, we first identify the specification blocks on a product page. We then extract the product attribute-value pairs from these blocks following an approach inspired by wrapper induction. We created a labeled dataset of product specifications extracted from 14,111 diverse specification blocks taken from a range of different product websites. Our experiments show the efficacy of our approach compared to the current specification extraction models and support our claim about its application to large-scale product specification extraction.