 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Straight: Document Orientation Detection for Efficient OCR
Nov 06, 2025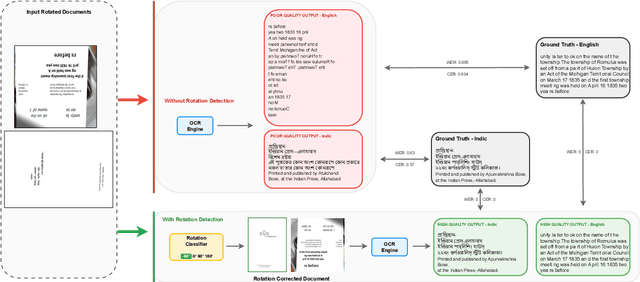



Despite significant advances in document understanding, determining the correct orientation of scanned or photographed documents remains a critical pre-processing step in the real world settings. Accurate rotation correction is essential for enhancing the performance of downstream tasks such as Optical Character Recognition (OCR) where misalignment commonly arises due to user errors, particularly incorrect base orientations of the camera during capture. In this study, we first introduce OCR-Rotation-Bench (ORB), a new benchmark for evaluating OCR robustness to image rotations, comprising (i) ORB-En, built from rotation-transformed structured and free-form English OCR datasets, and (ii) ORB-Indic, a novel multilingual set spanning 11 Indic mid to low-resource languages. We also present a fast, robust and lightweight rotation classification pipeline built on the vision encoder of Phi-3.5-Vision model with dynamic image cropping, fine-tuned specifically for 4-class rotation task in a standalone fashion. Our method achieves near-perfect 96% and 92% accuracy on identifying the rotations respectively on both the datasets. Beyond classification, we demonstrate the critical role of our module in boosting OCR performance: closed-source (up to 14%) and open-weights models (up to 4x) in the simulated real-world setting.
IndicVisionBench: Benchmarking Cultural and Multilingual Understanding in VLMs
Nov 06, 2025



Vision-language models (VLMs) have demonstrated impressive generalization across multimodal tasks, yet most evaluation benchmarks remain Western-centric, leaving open questions about their performance in culturally diverse and multilingual settings. To address this gap, we introduce IndicVisionBench, the first large-scale benchmark centered on the Indian subcontinent. Covering English and 10 Indian languages, our benchmark spans 3 multimodal tasks, including Optical Character Recognition (OCR), Multimodal Machine Translation (MMT), and Visual Question Answering (VQA), covering 6 kinds of question types. Our final benchmark consists of a total of ~5K images and 37K+ QA pairs across 13 culturally grounded topics. In addition, we release a paired parallel corpus of annotations across 10 Indic languages, creating a unique resource for analyzing cultural and linguistic biases in VLMs. We evaluate a broad spectrum of 8 models, from proprietary closed-source systems to open-weights medium and large-scale models. Our experiments reveal substantial performance gaps, underscoring the limitations of current VLMs in culturally diverse contexts. By centering cultural diversity and multilinguality, IndicVisionBench establishes a reproducible evaluation framework that paves the way for more inclusive multimodal research.
Chitranuvad: Adapting Multi-Lingual LLMs for Multimodal Translation
Feb 27, 2025In this work, we provide the system description of our submission as part of the English to Lowres Multimodal Translation Task at the Workshop on Asian Translation (WAT2024). We introduce Chitranuvad, a multimodal model that effectively integrates Multilingual LLM and a vision module for Multimodal Translation. Our method uses a ViT image encoder to extract visual representations as visual token embeddings which are projected to the LLM space by an adapter layer and generates translation in an autoregressive fashion. We participated in all the three tracks (Image Captioning, Text only and Multimodal translation tasks) for Indic languages (ie. English translation to Hindi, Bengali and Malyalam) and achieved SOTA results for Hindi in all of them on the Challenge set while remaining competitive for the other languages in the shared task.
Chitrarth: Bridging Vision and Language for a Billion People
Feb 21, 2025Recent multimodal foundation models are primarily trained on English or high resource European language data, which hinders their applicability to other medium and low-resource languages. To address this limitation, we introduce Chitrarth (Chitra: Image; Artha: Meaning), an inclusive Vision-Language Model (VLM), specifically targeting the rich linguistic diversity and visual reasoning across 10 prominent Indian languages. Our model effectively integrates a state-of-the-art (SOTA) multilingual Large Language Model (LLM) with a vision module, primarily trained on multilingual image-text data. Furthermore, we also introduce BharatBench, a comprehensive framework for evaluating VLMs across various Indian languages, ultimately contributing to more diverse and effective AI systems. Our model achieves SOTA results for benchmarks across low resource languages while retaining its efficiency in English. Through our research, we aim to set new benchmarks in multilingual-multimodal capabilities, offering substantial improvements over existing models and establishing a foundation to facilitate future advancements in this arena.