 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile Microphone Array Speech Detection and Localization in Diverse Everyday Environments
Jun 28, 2021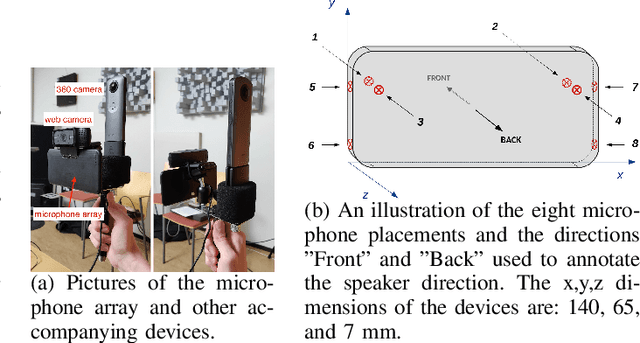
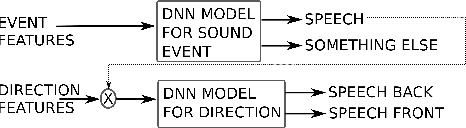
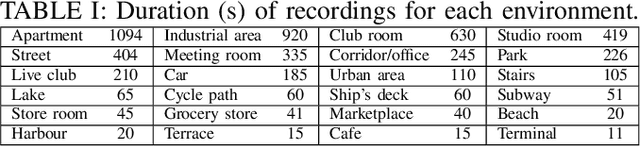
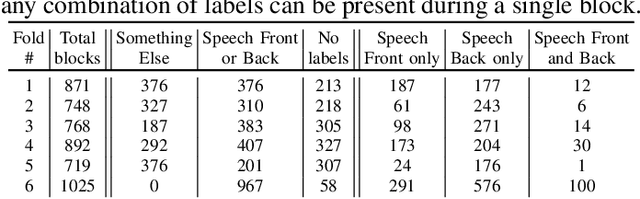
Joint sound event localization and detection (SELD) is an integral part of developing context awareness into communication interfaces of mobile robots, smartphones, and home assistants. For example, an automatic audio focus for video capture on a mobile phone requires robust detection of relevant acoustic events around the device and their direction. Existing SELD approaches have been evaluated using material produced in controlled indoor environments, or the audio is simulated by mixing isolated sounds to different spatial locations. This paper studies SELD of speech in diverse everyday environments, where the audio corresponds to typical usage scenarios of handheld mobile devices. In order to allow weighting the relative importance of localization vs. detection, we will propose a two-stage hierarchical system, where the first stage is to detect the target events, and the second stage is to localize them. The proposed method utilizes convolutional recurrent neural network (CRNN) and is evaluated on a database of manually annotated microphone array recordings from various acoustic conditions. The array is embedded in a contemporary mobile phone form factor. The obtained results show good speech detection and localization accuracy of the proposed method in contrast to a non-hierarchical flat classification model.
Sound Event Detection in Multichannel Audio Using Spatial and Harmonic Features
Jun 07, 2017



In this paper, we propose the use of spatial and harmonic features in combination with long short term memory (LSTM) recurrent neural network (RNN) for automatic sound event detection (SED) task. Real life sound recordings typically have many overlapping sound events, making it hard to recognize with just mono channel audio. Human listeners have been successfully recognizing the mixture of overlapping sound events using pitch cues and exploiting the stereo (multichannel) audio signal available at their ears to spatially localize these events. Traditionally SED systems have only been using mono channel audio, motivated by the human listener we propose to extend them to use multichannel audio. The proposed SED system is compared against the state of the art mono channel method on the development subset of TUT sound events detection 2016 database. The usage of spatial and harmonic features are shown to improve the performance of SED.
Sound Event Detection Using Spatial Features and Convolutional Recurrent Neural Network
Jun 07, 2017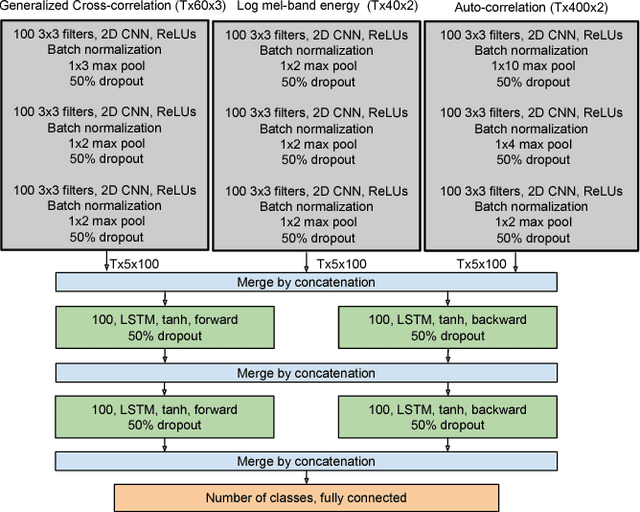
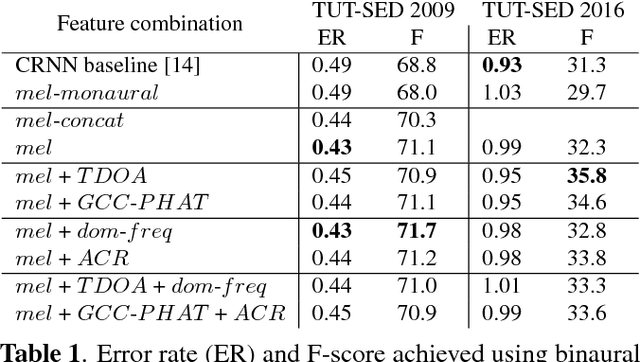
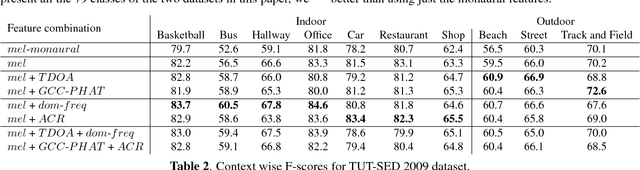
This paper proposes to use low-level spatial features extracted from multichannel audio for sound event detection. We extend the convolutional recurrent neural network to handle more than one type of these multichannel features by learning from each of them separately in the initial stages. We show that instead of concatenating the features of each channel into a single feature vector the network learns sound events in multichannel audio better when they are presented as separate layers of a volume. Using the proposed spatial features over monaural features on the same network gives an absolute F-score improvement of 6.1% on the publicly available TUT-SED 2016 dataset and 2.7% on the TUT-SED 2009 dataset that is fifteen times larger.