Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSound Event Detection Using Spatial Features and Convolutional Recurrent Neural Network
Paper and Code
Jun 07, 2017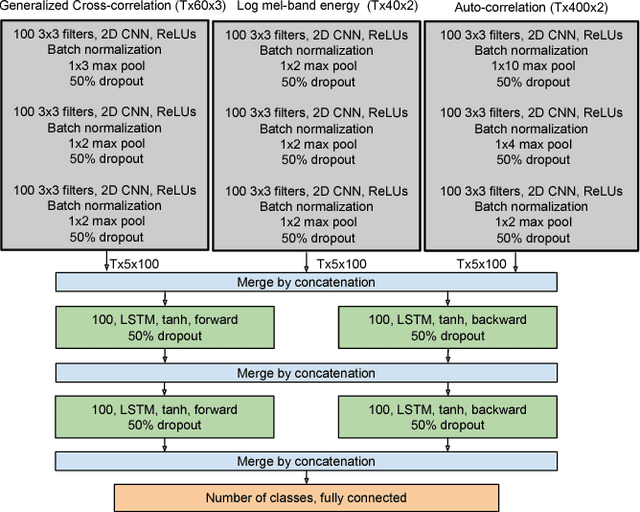
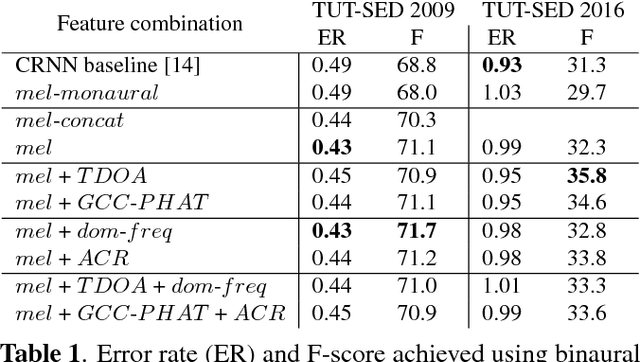
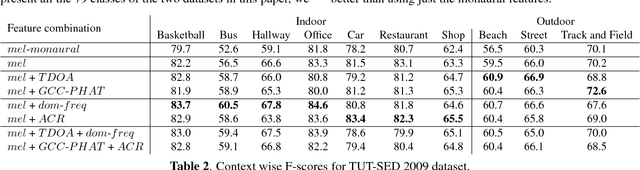
This paper proposes to use low-level spatial features extracted from multichannel audio for sound event detection. We extend the convolutional recurrent neural network to handle more than one type of these multichannel features by learning from each of them separately in the initial stages. We show that instead of concatenating the features of each channel into a single feature vector the network learns sound events in multichannel audio better when they are presented as separate layers of a volume. Using the proposed spatial features over monaural features on the same network gives an absolute F-score improvement of 6.1% on the publicly available TUT-SED 2016 dataset and 2.7% on the TUT-SED 2009 dataset that is fifteen times larger.
* Accepted for IEEE International Conference on Acoustics, Speech and
Signal Processing (ICASSP 2017)
View paper on