 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimbre-Trap: A Low-Resource Framework for Instrument-Agnostic Music Transcription
Paper and Code
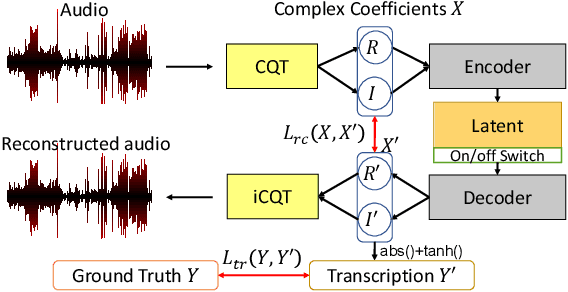
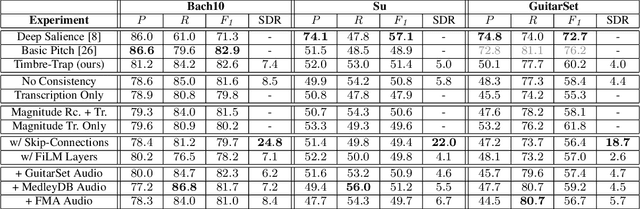
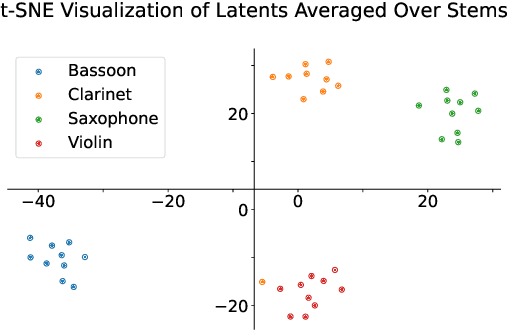
In recent years, research on music transcription has focused mainly on architecture design and instrument-specific data acquisition. With the lack of availability of diverse datasets, progress is often limited to solo-instrument tasks such as piano transcription. Several works have explored multi-instrument transcription as a means to bolster the performance of models on low-resource tasks, but these methods face the same data availability issues. We propose Timbre-Trap, a novel framework which unifies music transcription and audio reconstruction by exploiting the strong separability between pitch and timbre. We train a single U-Net to simultaneously estimate pitch salience and reconstruct complex spectral coefficients, selecting between either output during the decoding stage via a simple switch mechanism. In this way, the model learns to produce coefficients corresponding to timbre-less audio, which can be interpreted as pitch salience. We demonstrate that the framework leads to performance comparable to state-of-the-art instrument-agnostic transcription methods, while only requiring a small amount of annotated data.