 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Invertible State Space for Process Trees
Jul 31, 2024



Process models are, like event data, first-class citizens in most process mining approaches. Several process modeling formalisms have been proposed and used, e.g., Petri nets, BPMN, and process trees. Despite their frequent use, little research addresses the formal properties of process trees and the corresponding potential to improve the efficiency of solving common computational problems. Therefore, in this paper, we propose an invertible state space definition for process trees and demonstrate that the corresponding state space graph is isomorphic to the state space graph of the tree's inverse. Our result supports the development of novel, time-efficient, decomposition strategies for applications of process trees. Our experiments confirm that our state space definition allows for the adoption of bidirectional state space search, which significantly improves the overall performance of state space searches.
Performance-Preserving Event Log Sampling for Predictive Monitoring
Jan 18, 2023Predictive process monitoring is a subfield of process mining that aims to estimate case or event features for running process instances. Such predictions are of significant interest to the process stakeholders. However, most of the state-of-the-art methods for predictive monitoring require the training of complex machine learning models, which is often inefficient. Moreover, most of these methods require a hyper-parameter optimization that requires several repetitions of the training process which is not feasible in many real-life applications. In this paper, we propose an instance selection procedure that allows sampling training process instances for prediction models. We show that our instance selection procedure allows for a significant increase of training speed for next activity and remaining time prediction methods while maintaining reliable levels of prediction accuracy.
Event Log Sampling for Predictive Monitoring
Apr 04, 2022

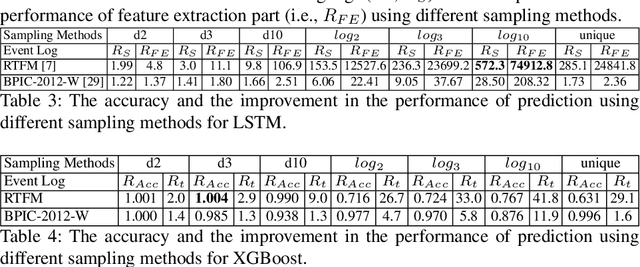
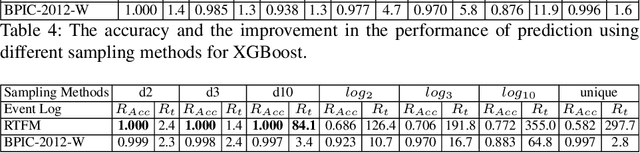
Predictive process monitoring is a subfield of process mining that aims to estimate case or event features for running process instances. Such predictions are of significant interest to the process stakeholders. However, state-of-the-art methods for predictive monitoring require the training of complex machine learning models, which is often inefficient. This paper proposes an instance selection procedure that allows sampling training process instances for prediction models. We show that our sampling method allows for a significant increase of training speed for next activity prediction methods while maintaining reliable levels of prediction accuracy.
* 7 pages, 1 figure, 4 tables, 34 references
Freezing Sub-Models During Incremental Process Discovery: Extended Version
Jul 31, 2021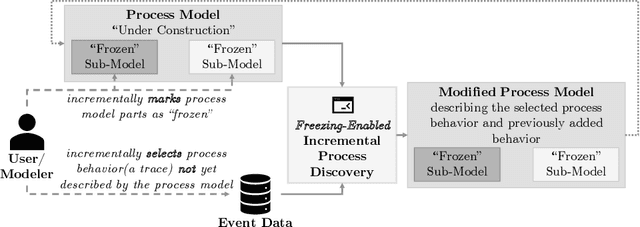

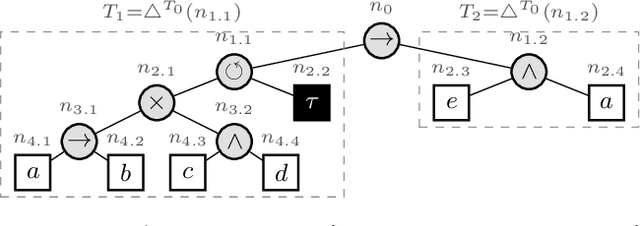

Process discovery aims to learn a process model from observed process behavior. From a user's perspective, most discovery algorithms work like a black box. Besides parameter tuning, there is no interaction between the user and the algorithm. Interactive process discovery allows the user to exploit domain knowledge and to guide the discovery process. Previously, an incremental discovery approach has been introduced where a model, considered to be under construction, gets incrementally extended by user-selected process behavior. This paper introduces a novel approach that additionally allows the user to freeze model parts within the model under construction. Frozen sub-models are not altered by the incremental approach when new behavior is added to the model. The user can thus steer the discovery algorithm. Our experiments show that freezing sub-models can lead to higher quality models.
A Framework for Explainable Concept Drift Detection in Process Mining
May 27, 2021

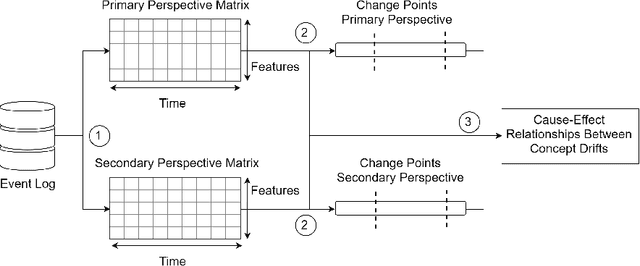
Rapidly changing business environments expose companies to high levels of uncertainty. This uncertainty manifests itself in significant changes that tend to occur over the lifetime of a process and possibly affect its performance. It is important to understand the root causes of such changes since this allows us to react to change or anticipate future changes. Research in process mining has so far only focused on detecting, locating and characterizing significant changes in a process and not on finding root causes of such changes. In this paper, we aim to close this gap. We propose a framework that adds an explainability level onto concept drift detection in process mining and provides insights into the cause-effect relationships behind significant changes. We define different perspectives of a process, detect concept drifts in these perspectives and plug the perspectives into a causality check that determines whether these concept drifts can be causal to each other. We showcase the effectiveness of our framework by evaluating it on both synthetic and real event data. Our experiments show that our approach unravels cause-effect relationships and provides novel insights into executed processes.
Conformance Checking Approximation using Subset Selection and Edit Distance
Dec 02, 2019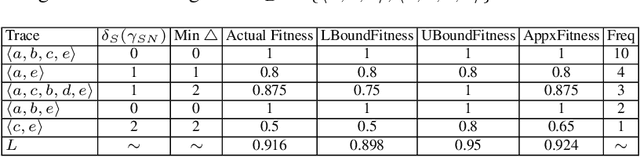
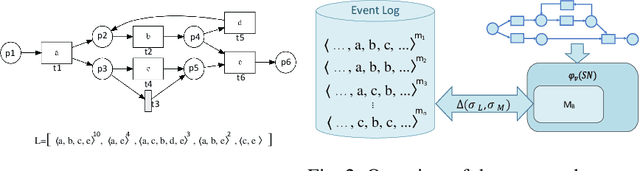
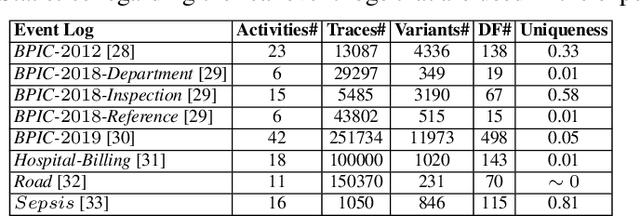
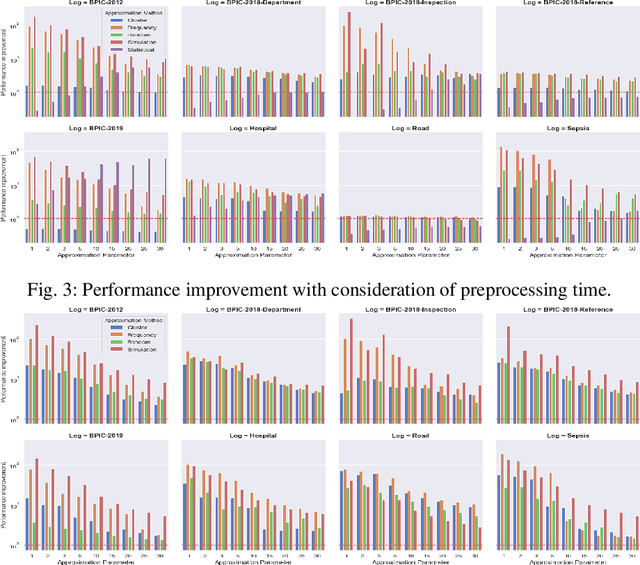
Conformance checking techniques let us find out to what degree a process model and real execution data correspond to each other. In recent years, alignments have proven extremely useful in calculating conformance statistics. Most techniques to compute alignments provide an exact solution. However, in many applications, it is enough to have an approximation of the conformance value. Specifically, for large event data, the computing time for alignments is considerably long using current techniques which makes them inapplicable in reality. Also, it is no longer feasible to use standard hardware for complex processes. Hence, we need techniques that enable us to obtain fast, and at the same time, accurate approximation of the conformance values. This paper proposes new approximation techniques to compute approximated conformance checking values close to exact solution values in a faster time. Those methods also provide upper and lower bounds for the approximated alignment value. Our experiments on real event data show that it is possible to improve the performance of conformance checking by using the proposed methods compared to using the state-of-the-art alignment approximation technique. Results show that in most of the cases, we provide tight bounds, accurate approximated alignment values, and similar deviation statistics.
An Interdisciplinary Comparison of Sequence Modeling Methods for Next-Element Prediction
Oct 31, 2018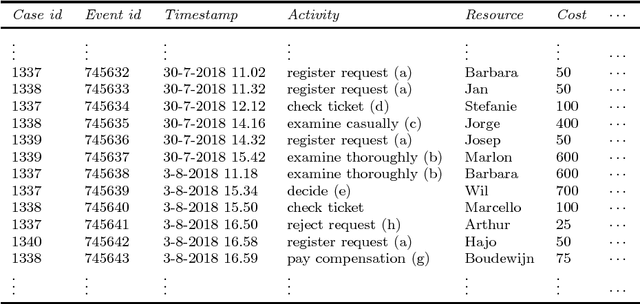
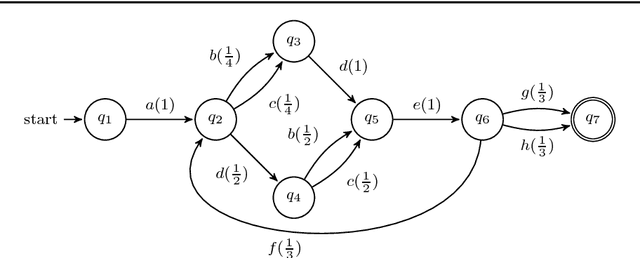
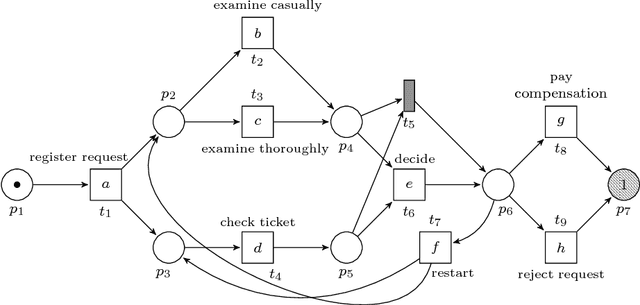

Data of sequential nature arise in many application domains in forms of, e.g. textual data, DNA sequences, and software execution traces. Different research disciplines have developed methods to learn sequence models from such datasets: (i) in the machine learning field methods such as (hidden) Markov models and recurrent neural networks have been developed and successfully applied to a wide-range of tasks, (ii) in process mining process discovery techniques aim to generate human-interpretable descriptive models, and (iii) in the grammar inference field the focus is on finding descriptive models in the form of formal grammars. Despite their different focuses, these fields share a common goal - learning a model that accurately describes the behavior in the underlying data. Those sequence models are generative, i.e, they can predict what elements are likely to occur after a given unfinished sequence. So far, these fields have developed mainly in isolation from each other and no comparison exists. This paper presents an interdisciplinary experimental evaluation that compares sequence modeling techniques on the task of next-element prediction on four real-life sequence datasets. The results indicate that machine learning techniques that generally have no aim at interpretability in terms of accuracy outperform techniques from the process mining and grammar inference fields that aim to yield interpretable models.
Event Stream-Based Process Discovery using Abstract Representations
Apr 25, 2017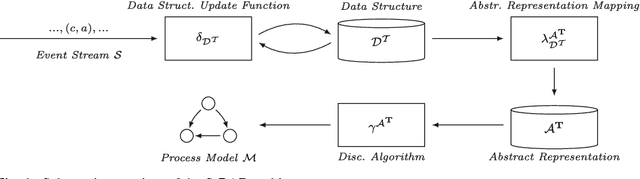
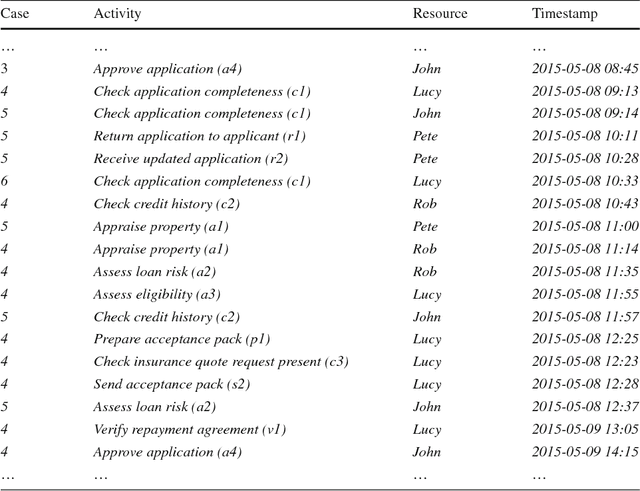
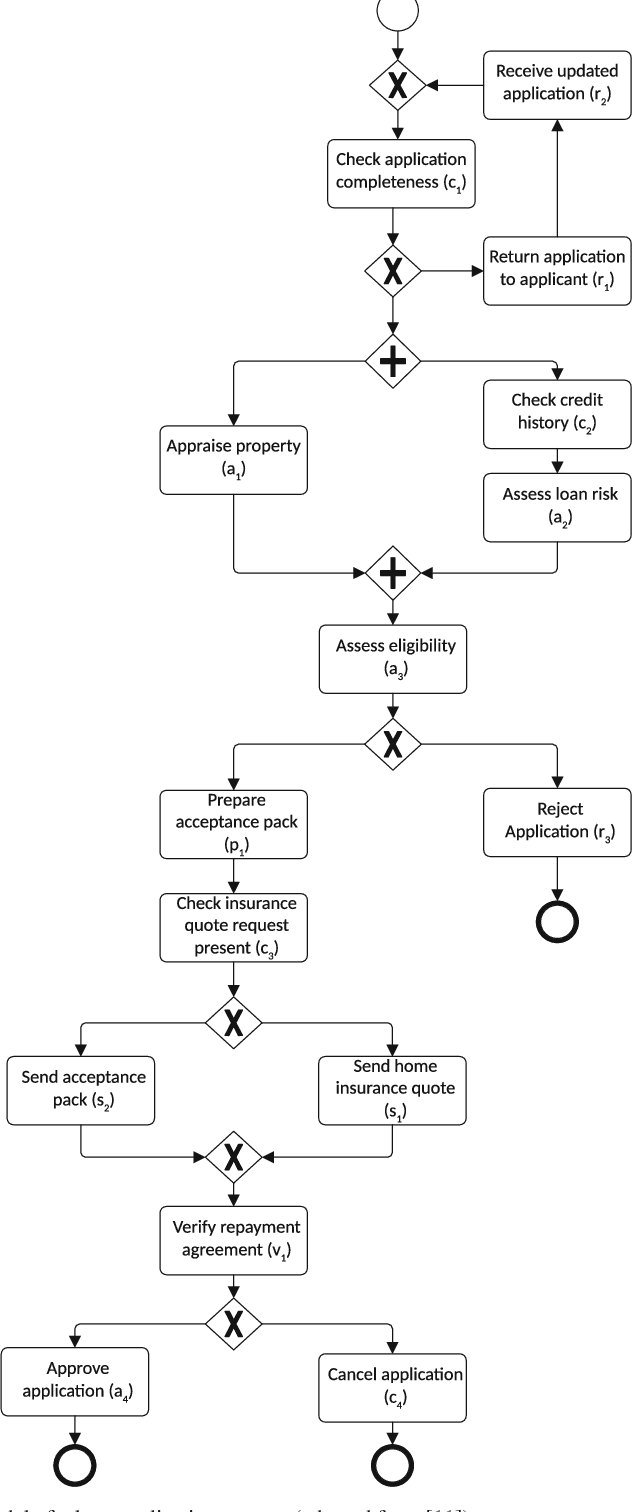

The aim of process discovery, originating from the area of process mining, is to discover a process model based on business process execution data. A majority of process discovery techniques relies on an event log as an input. An event log is a static source of historical data capturing the execution of a business process. In this paper we focus on process discovery relying on online streams of business process execution events. Learning process models from event streams poses both challenges and opportunities, i.e. we need to handle unlimited amounts of data using finite memory and, preferably, constant time. We propose a generic architecture that allows for adopting several classes of existing process discovery techniques in context of event streams. Moreover, we provide several instantiations of the architecture, accompanied by implementations in the process mining tool-kit ProM (http://promtools.org). Using these instantiations, we evaluate several dimensions of stream-based process discovery. The evaluation shows that the proposed architecture allows us to lift process discovery to the streaming domain.