 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Extracting and Encoding Features from Object-Centric Event Data
Sep 02, 2022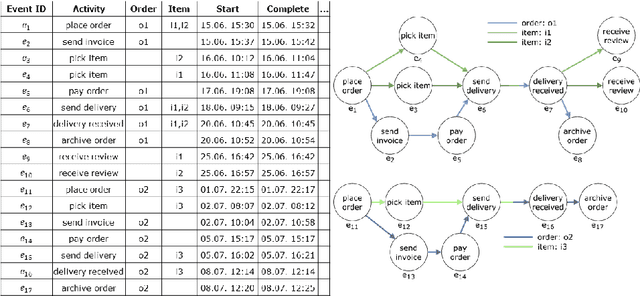
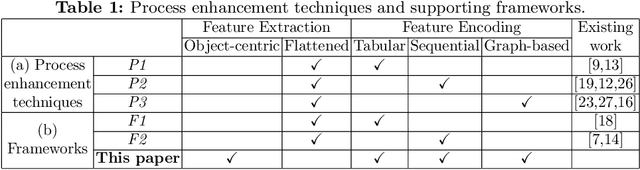
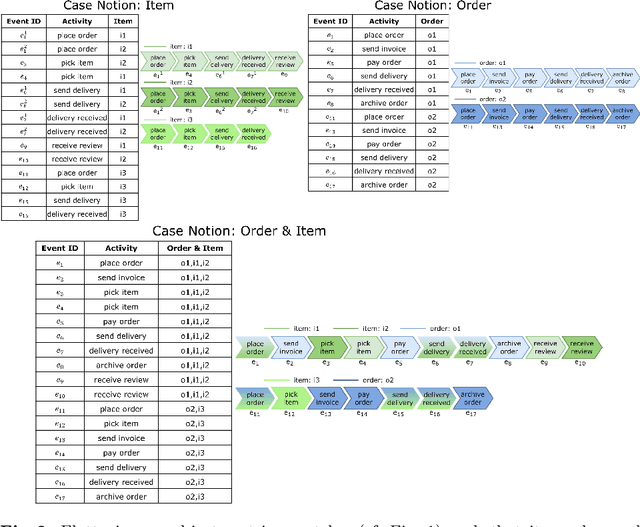
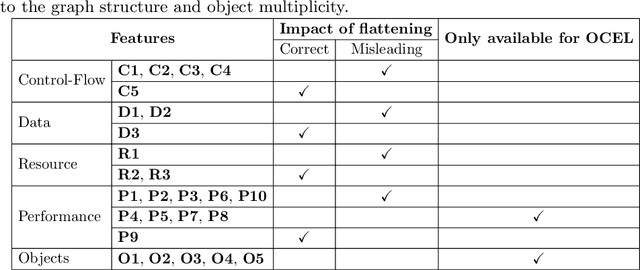
Traditional process mining techniques take event data as input where each event is associated with exactly one object. An object represents the instantiation of a process. Object-centric event data contain events associated with multiple objects expressing the interaction of multiple processes. As traditional process mining techniques assume events associated with exactly one object, these techniques cannot be applied to object-centric event data. To use traditional process mining techniques, the object-centric event data are flattened by removing all object references but one. The flattening process is lossy, leading to inaccurate features extracted from flattened data. Furthermore, the graph-like structure of object-centric event data is lost when flattening. In this paper, we introduce a general framework for extracting and encoding features from object-centric event data. We calculate features natively on the object-centric event data, leading to accurate measures. Furthermore, we provide three encodings for these features: tabular, sequential, and graph-based. While tabular and sequential encodings have been heavily used in process mining, the graph-based encoding is a new technique preserving the structure of the object-centric event data. We provide six use cases: a visualization and a prediction use case for each of the three encodings. We use explainable AI in the prediction use cases to show the utility of both the object-centric features and the structure of the sequential and graph-based encoding for a predictive model.
Defining Cases and Variants for Object-Centric Event Data
Aug 05, 2022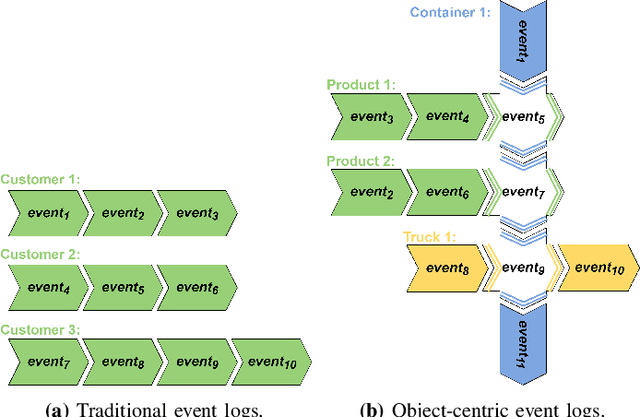
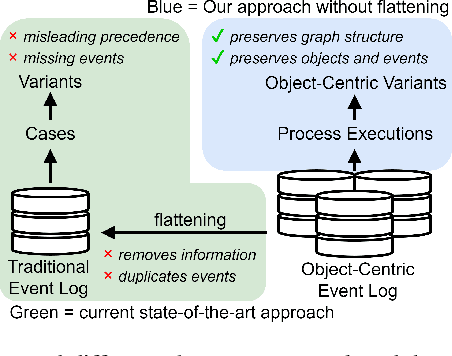
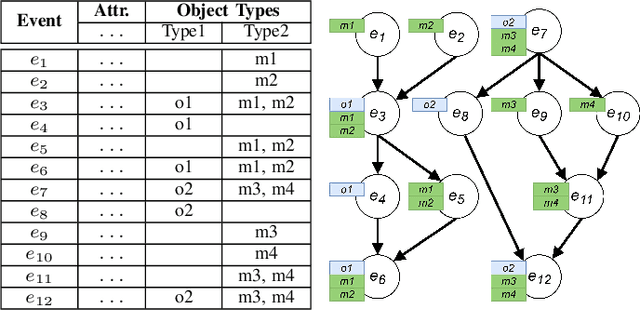
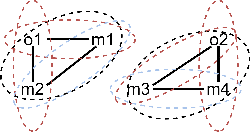
The execution of processes leaves traces of event data in information systems. These event data can be analyzed through process mining techniques. For traditional process mining techniques, one has to associate each event with exactly one object, e.g., the company's customer. Events related to one object form an event sequence called a case. A case describes an end-to-end run through a process. The cases contained in event data can be used to discover a process model, detect frequent bottlenecks, or learn predictive models. However, events encountered in real-life information systems, e.g., ERP systems, can often be associated with multiple objects. The traditional sequential case concept falls short of these object-centric event data as these data exhibit a graph structure. One might force object-centric event data into the traditional case concept by flattening it. However, flattening manipulates the data and removes information. Therefore, a concept analogous to the case concept of traditional event logs is necessary to enable the application of different process mining tasks on object-centric event data. In this paper, we introduce the case concept for object-centric process mining: process executions. These are graph-based generalizations of cases as considered in traditional process mining. Furthermore, we provide techniques to extract process executions. Based on these executions, we determine equivalent process behavior with respect to an attribute using graph isomorphism. Equivalent process executions with respect to the event's activity are object-centric variants, i.e., a generalization of variants in traditional process mining. We provide a visualization technique for object-centric variants. The contribution's scalability and efficiency are extensively evaluated. Furthermore, we provide a case study showing the most frequent object-centric variants of a real-life event log.
OPerA: Object-Centric Performance Analysis
Apr 22, 2022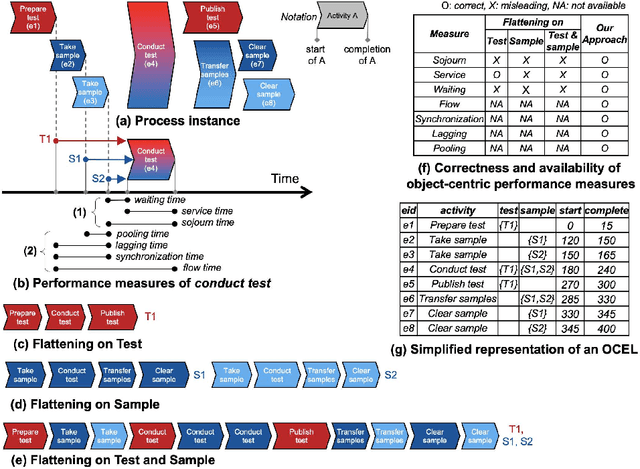
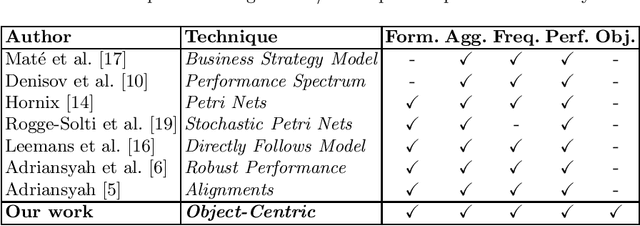
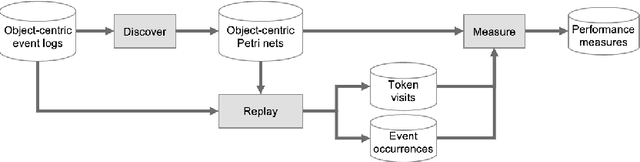
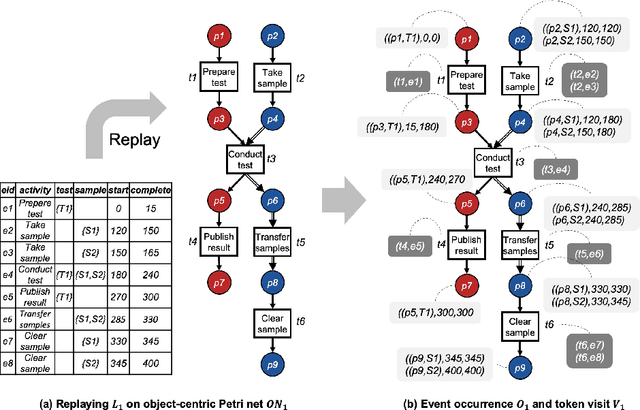
Performance analysis in process mining aims to provide insights on the performance of a business process by using a process model as a formal representation of the process. Such insights are reliably interpreted by process analysts in the context of a model with formal semantics. Existing techniques for performance analysis assume that a single case notion exists in a business process (e.g., a patient in healthcare process). However, in reality, different objects might interact (e.g., order, item, delivery, and invoice in an O2C process). In such a setting, traditional techniques may yield misleading or even incorrect insights on performance metrics such as waiting time. More importantly, by considering the interaction between objects, we can define object-centric performance metrics such as synchronization time, pooling time, and lagging time. In this work, we propose a novel approach to performance analysis considering multiple case notions by using object-centric Petri nets as formal representations of business processes. The proposed approach correctly computes existing performance metrics, while supporting the derivation of newly-introduced object-centric performance metrics. We have implemented the approach as a web application and conducted a case study based on a real-life loan application process.
Precision and Fitness in Object-Centric Process Mining
Oct 06, 2021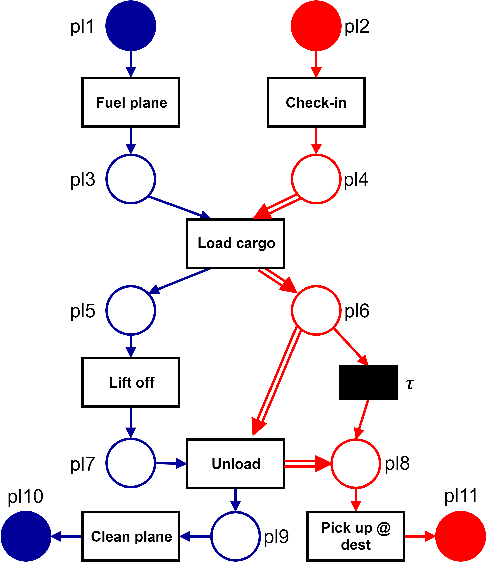
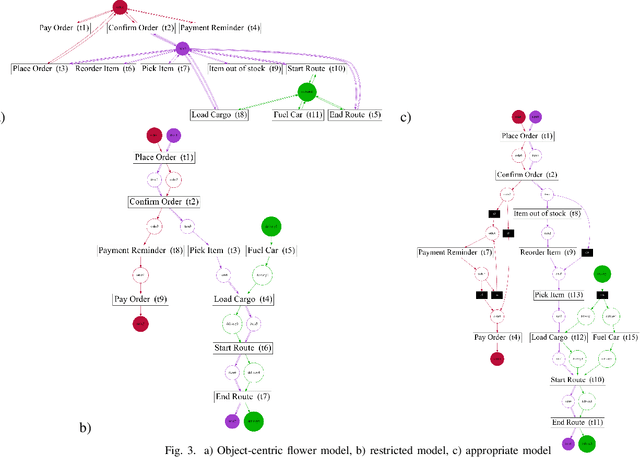
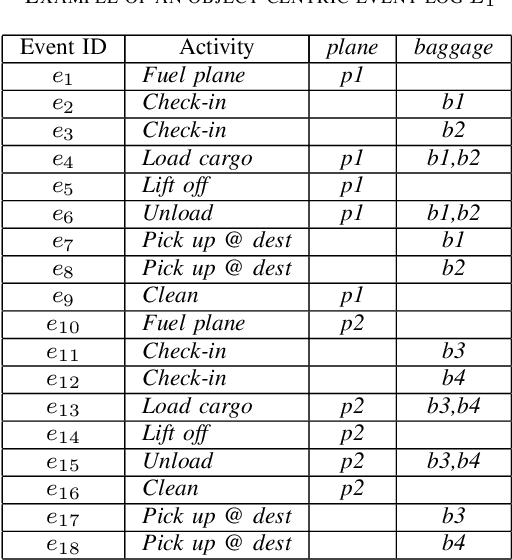
Traditional process mining considers only one single case notion and discovers and analyzes models based on this. However, a single case notion is often not a realistic assumption in practice. Multiple case notions might interact and influence each other in a process. Object-centric process mining introduces the techniques and concepts to handle multiple case notions. So far, such event logs have been standardized and novel process model discovery techniques were proposed. However, notions for evaluating the quality of a model are missing. These are necessary to enable future research on improving object-centric discovery and providing an objective evaluation of model quality. In this paper, we introduce a notion for the precision and fitness of an object-centric Petri net with respect to an object-centric event log. We give a formal definition and accompany this with an example. Furthermore, we provide an algorithm to calculate these quality measures. We discuss our precision and fitness notion based on an event log with different models. Our precision and fitness notions are an appropriate way to generalize quality measures to the object-centric setting since we are able to consider multiple case notions, their dependencies and their interactions.
A Framework for Explainable Concept Drift Detection in Process Mining
May 27, 2021

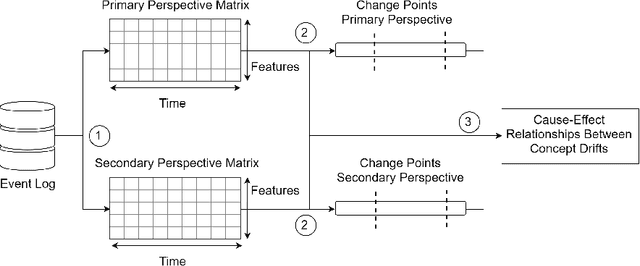
Rapidly changing business environments expose companies to high levels of uncertainty. This uncertainty manifests itself in significant changes that tend to occur over the lifetime of a process and possibly affect its performance. It is important to understand the root causes of such changes since this allows us to react to change or anticipate future changes. Research in process mining has so far only focused on detecting, locating and characterizing significant changes in a process and not on finding root causes of such changes. In this paper, we aim to close this gap. We propose a framework that adds an explainability level onto concept drift detection in process mining and provides insights into the cause-effect relationships behind significant changes. We define different perspectives of a process, detect concept drifts in these perspectives and plug the perspectives into a causality check that determines whether these concept drifts can be causal to each other. We showcase the effectiveness of our framework by evaluating it on both synthetic and real event data. Our experiments show that our approach unravels cause-effect relationships and provides novel insights into executed processes.