 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning beamforming in ultrasound imaging
Dec 19, 2018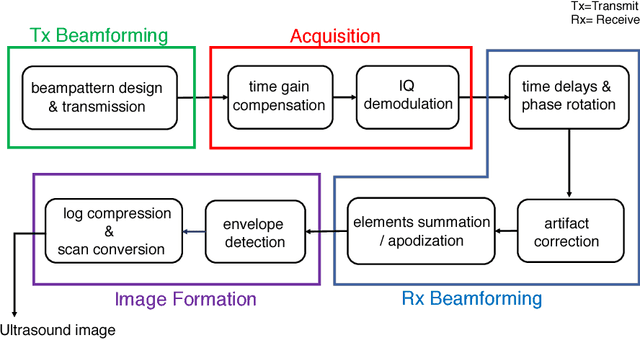



Medical ultrasound (US) is a widespread imaging modality owing its popularity to cost efficiency, portability, speed, and lack of harmful ionizing radiation. In this paper, we demonstrate that replacing the traditional ultrasound processing pipeline with a data-driven, learnable counterpart leads to significant improvement in image quality. Moreover, we demonstrate that greater improvement can be achieved through a learning-based design of the transmitted beam patterns simultaneously with learning an image reconstruction pipeline. We evaluate our method on an in-vivo first-harmonic cardiac ultrasound dataset acquired from volunteers and demonstrate the significance of the learned pipeline and transmit beam patterns on the image quality when compared to standard transmit and receive beamformers used in high frame-rate US imaging. We believe that the presented methodology provides a fundamentally different perspective on the classical problem of ultrasound beam pattern design.
High frame-rate cardiac ultrasound imaging with deep learning
Aug 23, 2018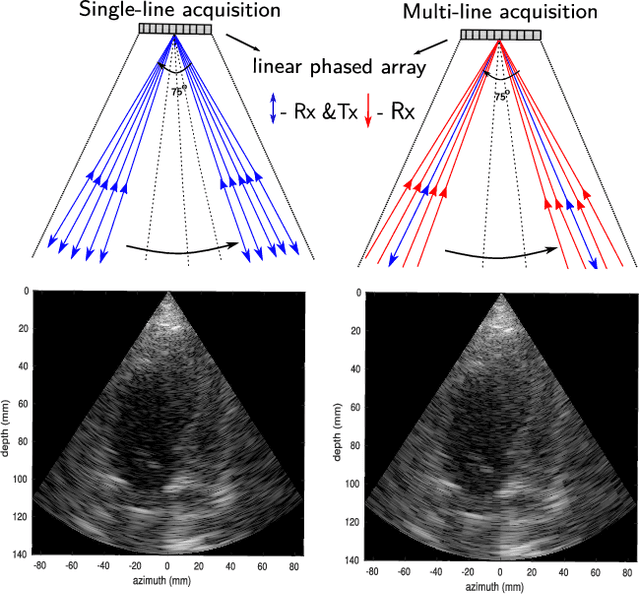

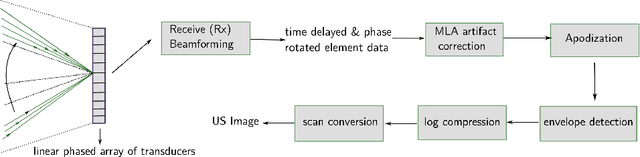

Cardiac ultrasound imaging requires a high frame rate in order to capture rapid motion. This can be achieved by multi-line acquisition (MLA), where several narrow-focused received lines are obtained from each wide-focused transmitted line. This shortens the acquisition time at the expense of introducing block artifacts. In this paper, we propose a data-driven learning-based approach to improve the MLA image quality. We train an end-to-end convolutional neural network on pairs of real ultrasound cardiac data, acquired through MLA and the corresponding single-line acquisition (SLA). The network achieves a significant improvement in image quality for both $5-$ and $7-$line MLA resulting in a decorrelation measure similar to that of SLA while having the frame rate of MLA.
High quality ultrasonic multi-line transmission through deep learning
Aug 23, 2018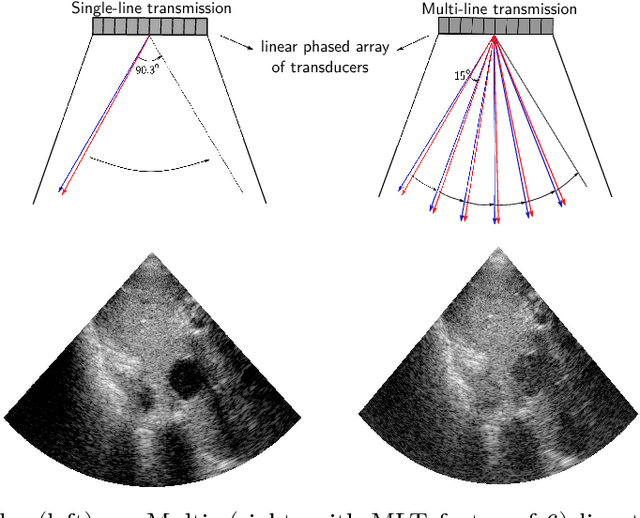
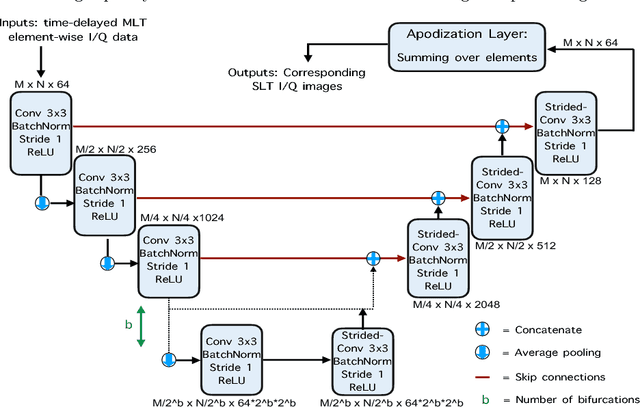
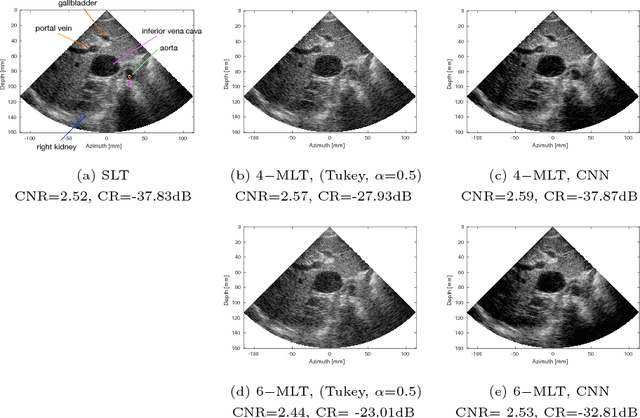
Frame rate is a crucial consideration in cardiac ultrasound imaging and 3D sonography. Several methods have been proposed in the medical ultrasound literature aiming at accelerating the image acquisition. In this paper, we consider one such method called \textit{multi-line transmission} (MLT), in which several evenly separated focused beams are transmitted simultaneously. While MLT reduces the acquisition time, it comes at the expense of a heavy loss of contrast due to the interactions between the beams (cross-talk artifact). In this paper, we introduce a data-driven method to reduce the artifacts arising in MLT. To this end, we propose to train an end-to-end convolutional neural network consisting of correction layers followed by a constant apodization layer. The network is trained on pairs of raw data obtained through MLT and the corresponding \textit{single-line transmission} (SLT) data. Experimental evaluation demonstrates significant improvement both in the visual image quality and in objective measures such as contrast ratio and contrast-to-noise ratio, while preserving resolution unlike traditional apodization-based methods. We show that the proposed method is able to generalize well across different patients and anatomies on real and phantom data.