 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWall Street Tree Search: Risk-Aware Planning for Offline Reinforcement Learning
Nov 06, 2022Offline reinforcement-learning (RL) algorithms learn to make decisions using a given, fixed training dataset without the possibility of additional online data collection. This problem setting is captivating because it holds the promise of utilizing previously collected datasets without any costly or risky interaction with the environment. However, this promise also bears the drawback of this setting. The restricted dataset induces subjective uncertainty because the agent can encounter unfamiliar sequences of states and actions that the training data did not cover. Moreover, inherent system stochasticity further increases uncertainty and aggravates the offline RL problem, preventing the agent from learning an optimal policy. To mitigate the destructive uncertainty effects, we need to balance the aspiration to take reward-maximizing actions with the incurred risk due to incorrect ones. In financial economics, modern portfolio theory (MPT) is a method that risk-averse investors can use to construct diversified portfolios that maximize their returns without unacceptable levels of risk. We integrate MPT into the agent's decision-making process to present a simple-yet-highly-effective risk-aware planning algorithm for offline RL. Our algorithm allows us to systematically account for the \emph{estimated quality} of specific actions and their \emph{estimated risk} due to the uncertainty. We show that our approach can be coupled with the Transformer architecture to yield a state-of-the-art planner for offline RL tasks, maximizing the return while significantly reducing the variance.
End to End Deep Neural Network Frequency Demodulation of Speech Signals
Oct 07, 2017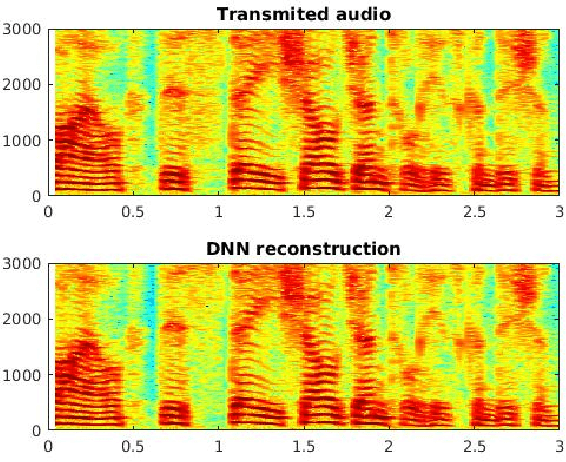
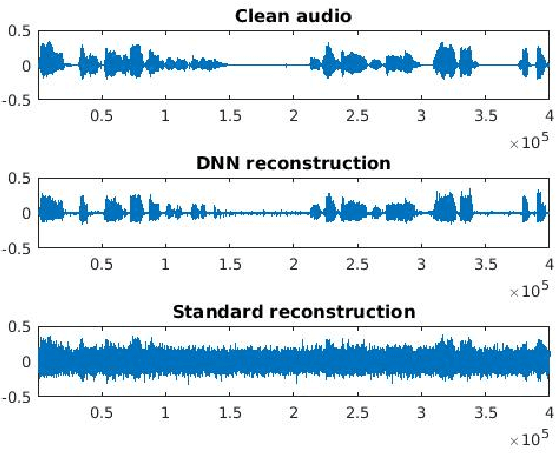
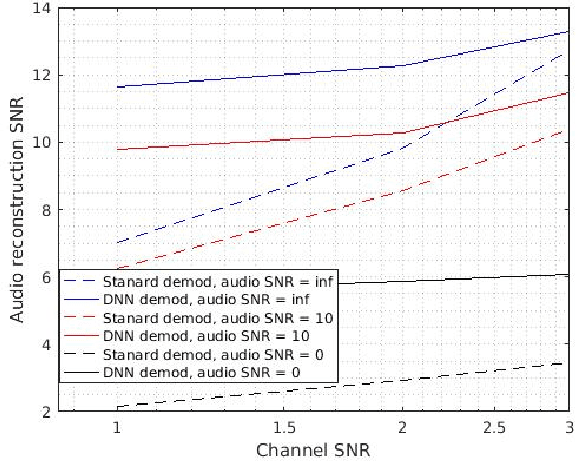
Frequency modulation (FM) is a form of radio broadcasting which is widely used nowadays and has been for almost a century. We suggest a software-defined-radio (SDR) receiver for FM demodulation that adopts an end-to-end learning based approach and utilizes the prior information of transmitted speech message in the demodulation process. The receiver detects and enhances speech from the in-phase and quadrature components of its base band version. The new system yields high performance detection for both acoustical disturbances, and communication channel noise and is foreseen to out-perform the established methods for low signal to noise ratio (SNR) conditions in both mean square error and in perceptual evaluation of speech quality score.
Perceptual audio loss function for deep learning
Aug 20, 2017PESQ and POLQA , are standards are standards for automated assessment of voice quality of speech as experienced by human beings. The predictions of those objective measures should come as close as possible to subjective quality scores as obtained in subjective listening tests. Wavenet is a deep neural network originally developed as a deep generative model of raw audio wave-forms. Wavenet architecture is based on dilated causal convolutions, which exhibit very large receptive fields. In this short paper we suggest using the Wavenet architecture, in particular its large receptive filed in order to learn PESQ algorithm. By doing so we can use it as a differentiable loss function for speech enhancement.