 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Hate Speech Detection at Large via Deep Generative Modeling
Paper and Code
May 13, 2020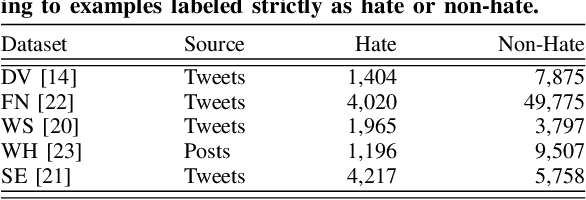



Hate speech detection is a critical problem in social media platforms, being often accused for enabling the spread of hatred and igniting physical violence. Hate speech detection requires overwhelming resources including high-performance computing for online posts and tweets monitoring as well as thousands of human experts for daily screening of suspected posts or tweets. Recently, Deep Learning (DL)-based solutions have been proposed for automatic detection of hate speech, using modest-sized training datasets of few thousands of hate speech sequences. While these methods perform well on the specific datasets, their ability to detect new hate speech sequences is limited and has not been investigated. Being a data-driven approach, it is well known that DL surpasses other methods whenever a scale-up in train dataset size and diversity is achieved. Therefore, we first present a dataset of 1 million realistic hate and non-hate sequences, produced by a deep generative language model. We further utilize the generated dataset to train a well-studied DL-based hate speech detector, and demonstrate consistent and significant performance improvements across five public hate speech datasets. Therefore, the proposed solution enables high sensitivity detection of a very large variety of hate speech sequences, paving the way to a fully automatic solution.