 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Overlooked Role of Graded Relevance Thresholds in Multilingual Dense Retrieval
Jan 07, 2026Dense retrieval models are typically fine-tuned with contrastive learning objectives that require binary relevance judgments, even though relevance is inherently graded. We analyze how graded relevance scores and the threshold used to convert them into binary labels affect multilingual dense retrieval. Using a multilingual dataset with LLM-annotated relevance scores, we examine monolingual, multilingual mixture, and cross-lingual retrieval scenarios. Our findings show that the optimal threshold varies systematically across languages and tasks, often reflecting differences in resource level. A well-chosen threshold can improve effectiveness, reduce the amount of fine-tuning data required, and mitigate annotation noise, whereas a poorly chosen one can degrade performance. We argue that graded relevance is a valuable but underutilized signal for dense retrieval, and that threshold calibration should be treated as a principled component of the fine-tuning pipeline.
Generative AI for Hate Speech Detection: Evaluation and Findings
Nov 16, 2023Automatic hate speech detection using deep neural models is hampered by the scarcity of labeled datasets, leading to poor generalization. To mitigate this problem, generative AI has been utilized to generate large amounts of synthetic hate speech sequences from available labeled examples, leveraging the generated data in finetuning large pre-trained language models (LLMs). In this chapter, we provide a review of relevant methods, experimental setups and evaluation of this approach. In addition to general LLMs, such as BERT, RoBERTa and ALBERT, we apply and evaluate the impact of train set augmentation with generated data using LLMs that have been already adapted for hate detection, including RoBERTa-Toxicity, HateBERT, HateXplain, ToxDect, and ToxiGen. An empirical study corroborates our previous findings, showing that this approach improves hate speech generalization, boosting recall performance across data distributions. In addition, we explore and compare the performance of the finetuned LLMs with zero-shot hate detection using a GPT-3.5 model. Our results demonstrate that while better generalization is achieved using the GPT-3.5 model, it achieves mediocre recall and low precision on most datasets. It is an open question whether the sensitivity of models such as GPT-3.5, and onward, can be improved using similar techniques of text generation.
Optimized Tokenization for Transcribed Error Correction
Oct 16, 2023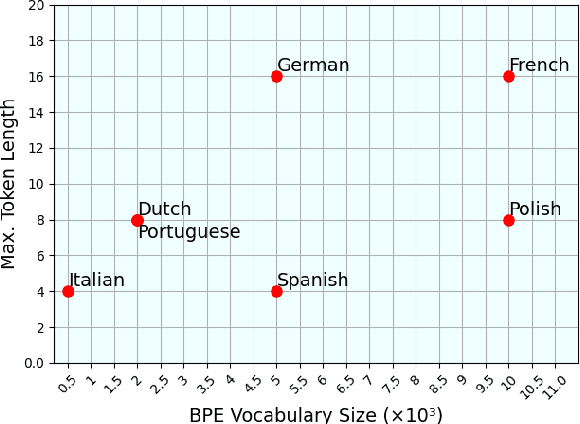
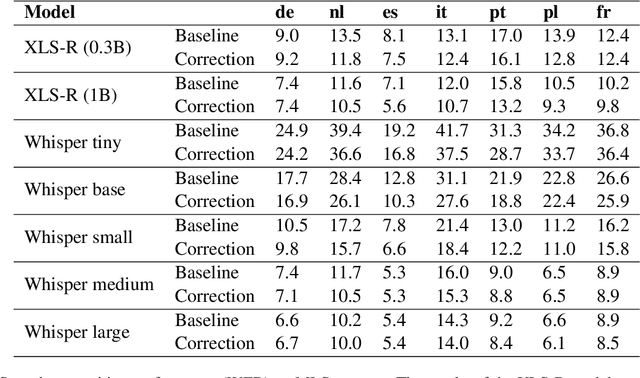
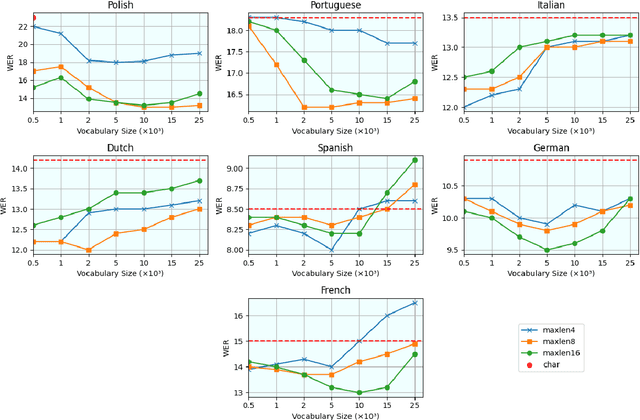
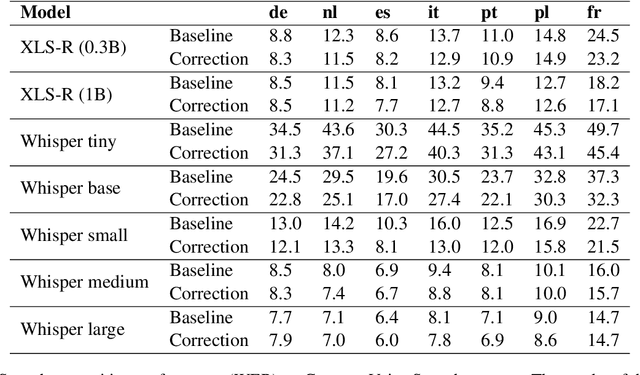
The challenges facing speech recognition systems, such as variations in pronunciations, adverse audio conditions, and the scarcity of labeled data, emphasize the necessity for a post-processing step that corrects recurring errors. Previous research has shown the advantages of employing dedicated error correction models, yet training such models requires large amounts of labeled data which is not easily obtained. To overcome this limitation, synthetic transcribed-like data is often utilized, however, bridging the distribution gap between transcribed errors and synthetic noise is not trivial. In this paper, we demonstrate that the performance of correction models can be significantly increased by training solely using synthetic data. Specifically, we empirically show that: (1) synthetic data generated using the error distribution derived from a set of transcribed data outperforms the common approach of applying random perturbations; (2) applying language-specific adjustments to the vocabulary of a BPE tokenizer strike a balance between adapting to unseen distributions and retaining knowledge of transcribed errors. We showcase the benefits of these key observations, and evaluate our approach using multiple languages, speech recognition systems and prominent speech recognition datasets.
Don't Be So Sure! Boosting ASR Decoding via Confidence Relaxation
Dec 27, 2022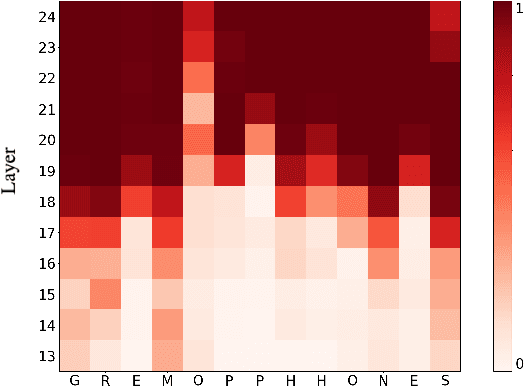

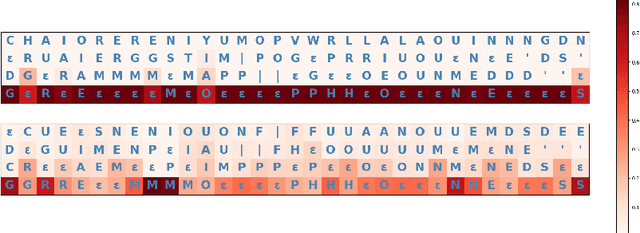
Automatic Speech Recognition (ASR) systems frequently use a search-based decoding strategy aiming to find the best attainable transcript by considering multiple candidates. One prominent speech recognition decoding heuristic is beam search, which seeks the transcript with the greatest likelihood computed using the predicted distribution. While showing substantial performance gains in various tasks, beam search loses some of its effectiveness when the predicted probabilities are highly confident, i.e., the predicted distribution is massed for a single or very few classes. We show that recently proposed Self-Supervised Learning (SSL)-based ASR models tend to yield exceptionally confident predictions that may hamper beam search from truly considering a diverse set of candidates. We perform a layer analysis to reveal and visualize how predictions evolve, and propose a decoding procedure that improves the performance of fine-tuned ASR models. Our proposed approach does not require further training beyond the original fine-tuning, nor additional model parameters. In fact, we find that our proposed method requires significantly less inference computation than current approaches. We propose aggregating the top M layers, potentially leveraging useful information encoded in intermediate layers, and relaxing model confidence. We demonstrate the effectiveness of our approach by conducting an empirical study on varying amounts of labeled resources and different model sizes, showing consistent improvements in particular when applied to low-resource scenarios.
Enhancing Speech Recognition Decoding via Layer Aggregation
Apr 05, 2022
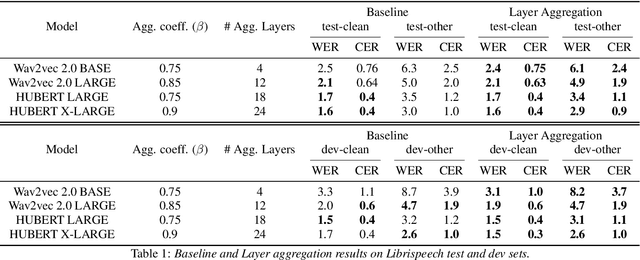
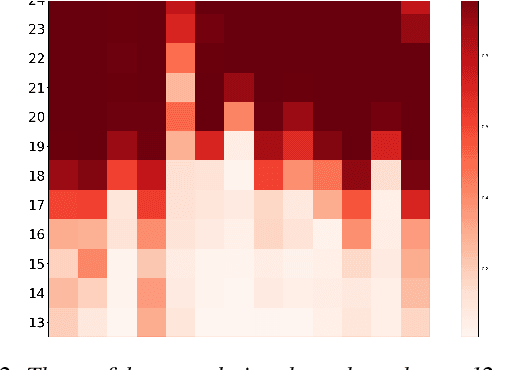
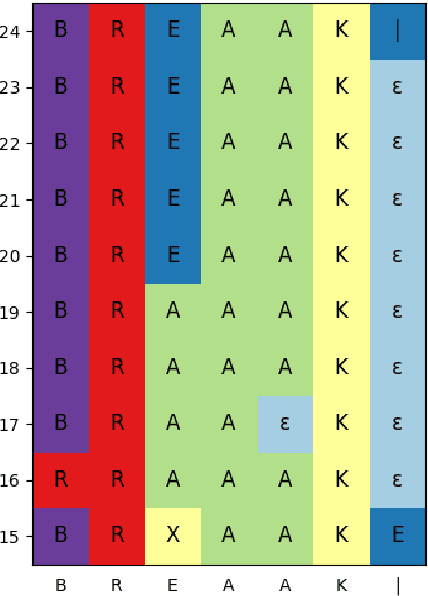
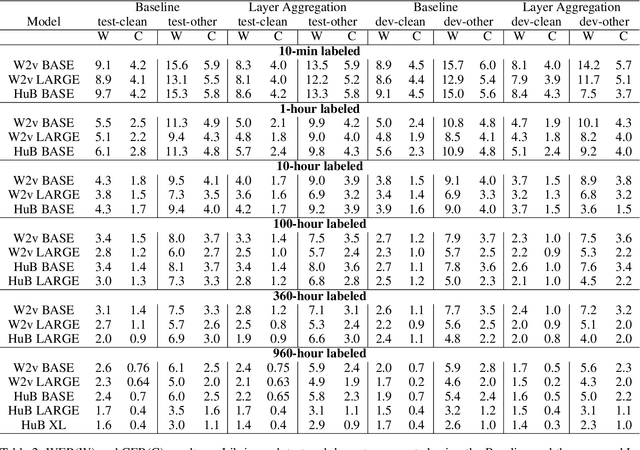
Recently proposed speech recognition systems are designed to predict using representations generated by their top layers, employing greedy decoding which isolates each timestep from the rest of the sequence. Aiming for improved performance, a beam search algorithm is frequently utilized and a language model is incorporated to assist with ranking the top candidates. In this work, we experiment with several speech recognition models and find that logits predicted using the top layers may hamper beam search from achieving optimal results. Specifically, we show that fined-tuned Wav2Vec 2.0 and HuBERT yield highly confident predictions, and hypothesize that the predictions are based on local information and may not take full advantage of the information encoded in intermediate layers. To this end, we perform a layer analysis to reveal and visualize how predictions evolve throughout the inference flow. We then propose a prediction method that aggregates the top M layers, potentially leveraging useful information encoded in intermediate layers and relaxing model confidence. We showcase the effectiveness of our approach via beam search decoding, conducting our experiments on Librispeech test and dev sets and achieving WER, and CER reduction of up to 10% and 22%, respectively.
Character-level HyperNetworks for Hate Speech Detection
Nov 11, 2021
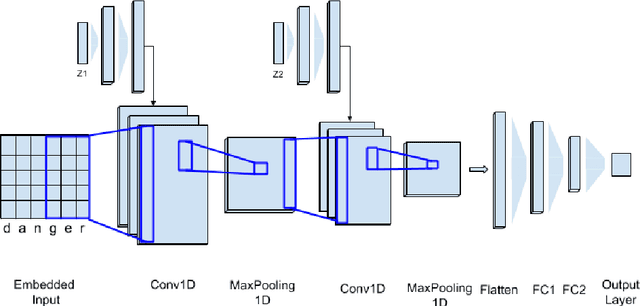

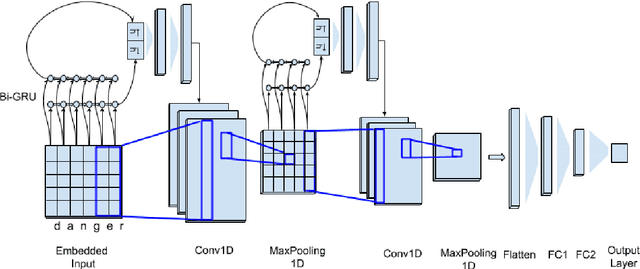
The massive spread of hate speech, hateful content targeted at specific subpopulations, is a problem of critical social importance. Automated methods for hate speech detection typically employ state-of-the-art deep learning (DL)-based text classifiers-very large pre-trained neural language models of over 100 million parameters, adapting these models to the task of hate speech detection using relevant labeled datasets. Unfortunately, there are only numerous labeled datasets of limited size that are available for this purpose. We make several contributions with high potential for advancing this state of affairs. We present HyperNetworks for hate speech detection, a special class of DL networks whose weights are regulated by a small-scale auxiliary network. These architectures operate at character-level, as opposed to word-level, and are several magnitudes of order smaller compared to the popular DL classifiers. We further show that training hate detection classifiers using large amounts of automatically generated examples in a procedure named as it data augmentation is beneficial in general, yet this practice especially boosts the performance of the proposed HyperNetworks. In fact, we achieve performance that is comparable or better than state-of-the-art language models, which are pre-trained and orders of magnitude larger, using this approach, as evaluated using five public hate speech datasets.
Fight Fire with Fire: Fine-tuning Hate Detectors using Large Samples of Generated Hate Speech
Sep 01, 2021
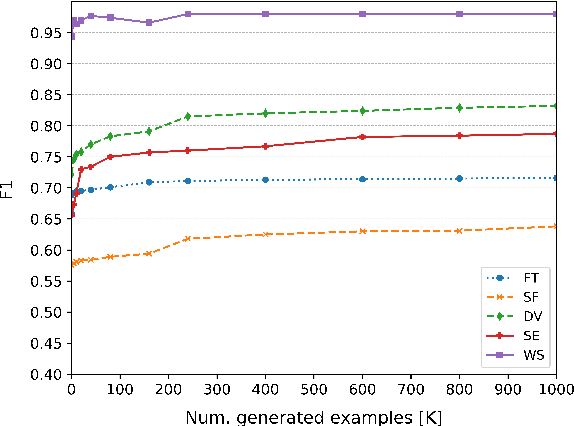
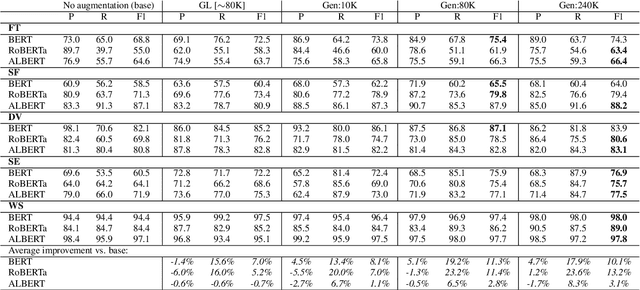
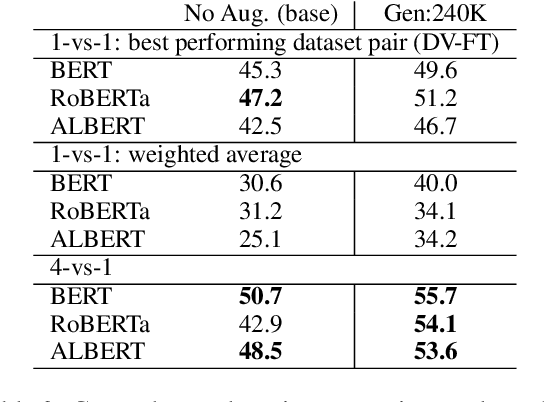
Automatic hate speech detection is hampered by the scarcity of labeled datasetd, leading to poor generalization. We employ pretrained language models (LMs) to alleviate this data bottleneck. We utilize the GPT LM for generating large amounts of synthetic hate speech sequences from available labeled examples, and leverage the generated data in fine-tuning large pretrained LMs on hate detection. An empirical study using the models of BERT, RoBERTa and ALBERT, shows that this approach improves generalization significantly and consistently within and across data distributions. In fact, we find that generating relevant labeled hate speech sequences is preferable to using out-of-domain, and sometimes also within-domain, human-labeled examples.
Towards Hate Speech Detection at Large via Deep Generative Modeling
May 13, 2020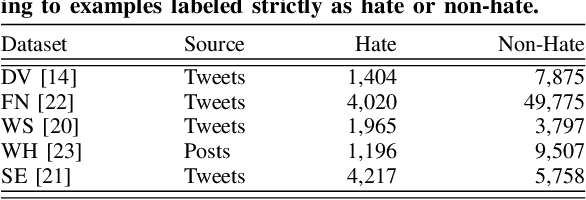



Hate speech detection is a critical problem in social media platforms, being often accused for enabling the spread of hatred and igniting physical violence. Hate speech detection requires overwhelming resources including high-performance computing for online posts and tweets monitoring as well as thousands of human experts for daily screening of suspected posts or tweets. Recently, Deep Learning (DL)-based solutions have been proposed for automatic detection of hate speech, using modest-sized training datasets of few thousands of hate speech sequences. While these methods perform well on the specific datasets, their ability to detect new hate speech sequences is limited and has not been investigated. Being a data-driven approach, it is well known that DL surpasses other methods whenever a scale-up in train dataset size and diversity is achieved. Therefore, we first present a dataset of 1 million realistic hate and non-hate sequences, produced by a deep generative language model. We further utilize the generated dataset to train a well-studied DL-based hate speech detector, and demonstrate consistent and significant performance improvements across five public hate speech datasets. Therefore, the proposed solution enables high sensitivity detection of a very large variety of hate speech sequences, paving the way to a fully automatic solution.