Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFight Fire with Fire: Fine-tuning Hate Detectors using Large Samples of Generated Hate Speech
Paper and Code
Sep 01, 2021
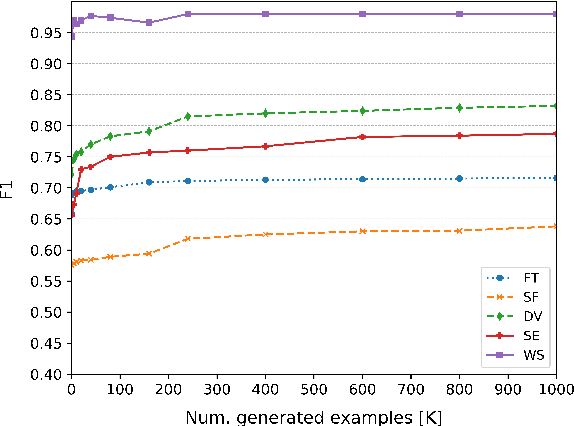
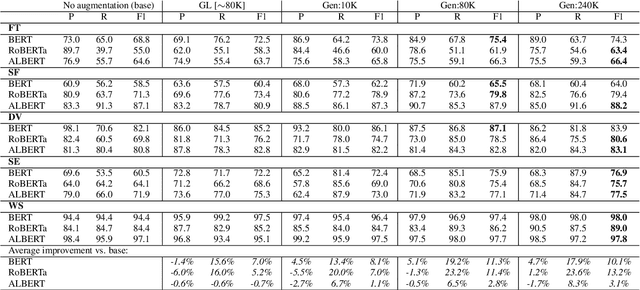
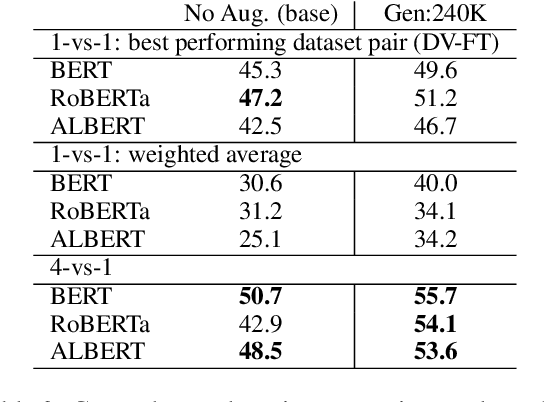
Automatic hate speech detection is hampered by the scarcity of labeled datasetd, leading to poor generalization. We employ pretrained language models (LMs) to alleviate this data bottleneck. We utilize the GPT LM for generating large amounts of synthetic hate speech sequences from available labeled examples, and leverage the generated data in fine-tuning large pretrained LMs on hate detection. An empirical study using the models of BERT, RoBERTa and ALBERT, shows that this approach improves generalization significantly and consistently within and across data distributions. In fact, we find that generating relevant labeled hate speech sequences is preferable to using out-of-domain, and sometimes also within-domain, human-labeled examples.
* Accepted to Findings of ACL: EMNLP 2021
View paper on