 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacter-level HyperNetworks for Hate Speech Detection
Paper and Code

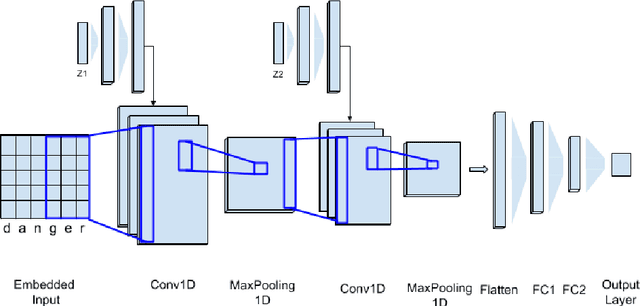

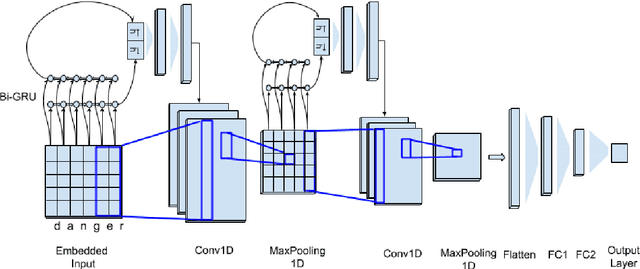
The massive spread of hate speech, hateful content targeted at specific subpopulations, is a problem of critical social importance. Automated methods for hate speech detection typically employ state-of-the-art deep learning (DL)-based text classifiers-very large pre-trained neural language models of over 100 million parameters, adapting these models to the task of hate speech detection using relevant labeled datasets. Unfortunately, there are only numerous labeled datasets of limited size that are available for this purpose. We make several contributions with high potential for advancing this state of affairs. We present HyperNetworks for hate speech detection, a special class of DL networks whose weights are regulated by a small-scale auxiliary network. These architectures operate at character-level, as opposed to word-level, and are several magnitudes of order smaller compared to the popular DL classifiers. We further show that training hate detection classifiers using large amounts of automatically generated examples in a procedure named as it data augmentation is beneficial in general, yet this practice especially boosts the performance of the proposed HyperNetworks. In fact, we achieve performance that is comparable or better than state-of-the-art language models, which are pre-trained and orders of magnitude larger, using this approach, as evaluated using five public hate speech datasets.