 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's the best place for an AI conference, Vancouver or ______: Why completing comparative questions is difficult
Paper and Code

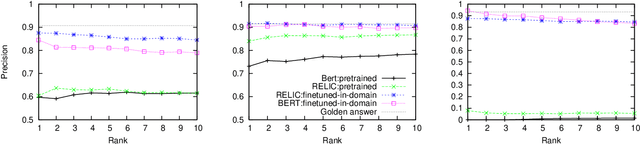

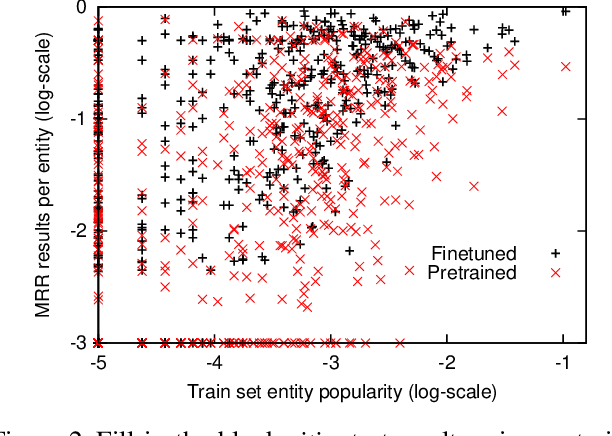
Although large neural language models (LMs) like BERT can be finetuned to yield state-of-the-art results on many NLP tasks, it is often unclear what these models actually learn. Here we study using such LMs to fill in entities in human-authored comparative questions, like ``Which country is older, India or ______?'' -- i.e., we study the ability of neural LMs to ask (not answer) reasonable questions. We show that accuracy in this fill-in-the-blank task is well-correlated with human judgements of whether a question is reasonable, and that these models can be trained to achieve nearly human-level performance in completing comparative questions in three different subdomains. However, analysis shows that what they learn fails to model any sort of broad notion of which entities are semantically comparable or similar -- instead the trained models are very domain-specific, and performance is highly correlated with co-occurrences between specific entities observed in the training set. This is true both for models that are pretrained on general text corpora, as well as models trained on a large corpus of comparison questions. Our study thus reinforces recent results on the difficulty of making claims about a deep model's world knowledge or linguistic competence based on performance on specific benchmark problems. We make our evaluation datasets publicly available to foster future research on complex understanding and reasoning in such models at standards of human interaction.