 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe X Types -- Mapping the Semantics of the Twitter Sphere
Sep 22, 2024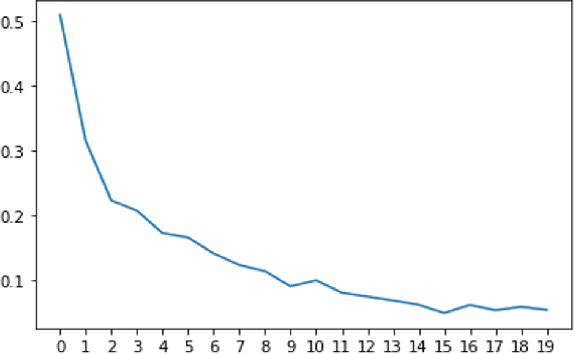
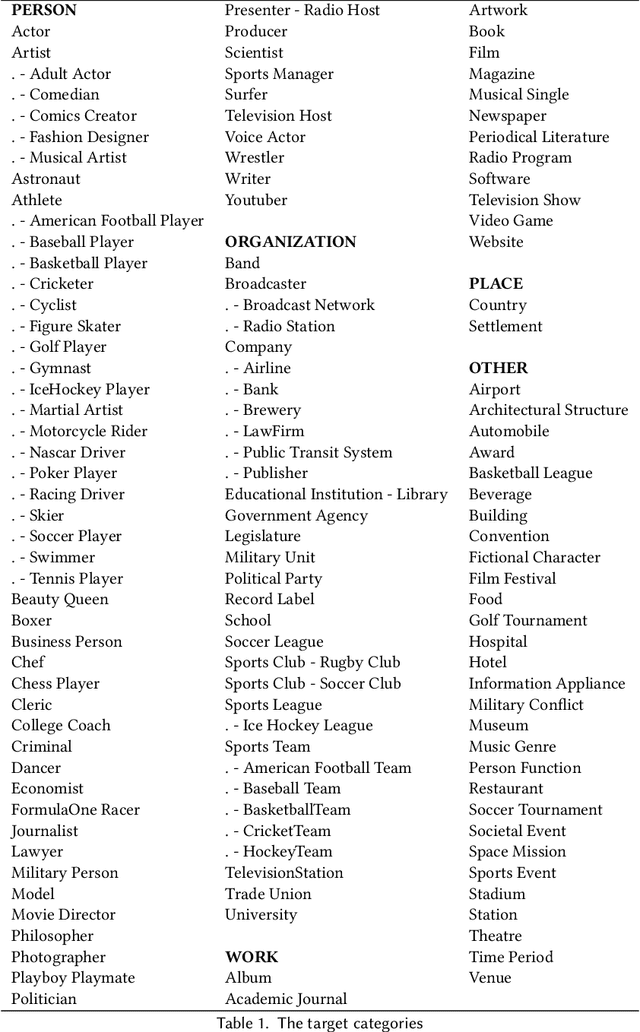
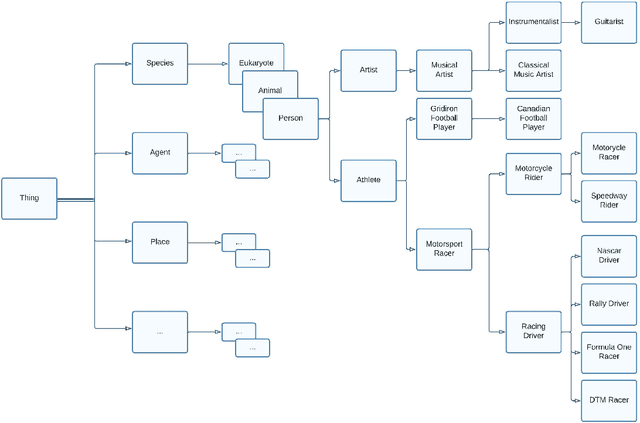

Social networks form a valuable source of world knowledge, where influential entities correspond to popular accounts. Unlike factual knowledge bases (KBs), which maintain a semantic ontology, structured semantic information is not available on social media. In this work, we consider a social KB of roughly 200K popular Twitter accounts, which denotes entities of interest. We elicit semantic information about those entities. In particular, we associate them with a fine-grained set of 136 semantic types, e.g., determine whether a given entity account belongs to a politician, or a musical artist. In the lack of explicit type information in Twitter, we obtain semantic labels for a subset of the accounts via alignment with the KBs of DBpedia and Wikidata. Given the labeled dataset, we finetune a transformer-based text encoder to generate semantic embeddings of the entities based on the contents of their accounts. We then exploit this evidence alongside network-based embeddings to predict the entities semantic types. In our experiments, we show high type prediction performance on the labeled dataset. Consequently, we apply our type classification model to all of the entity accounts in the social KB. Our analysis of the results offers insights about the global semantics of the Twitter sphere. We discuss downstream applications that should benefit from semantic type information and the semantic embeddings of social entities generated in this work. In particular, we demonstrate enhanced performance on the key task of entity similarity assessment using this information.