 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Quantization for Efficient Pre-Training of Transformer Language Models
Jul 16, 2024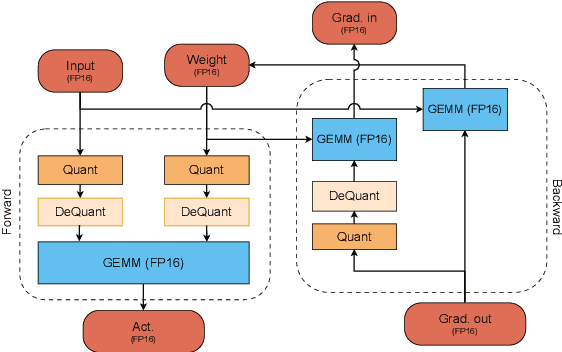


The increasing scale of Transformer models has led to an increase in their pre-training computational requirements. While quantization has proven to be effective after pre-training and during fine-tuning, applying quantization in Transformers during pre-training has remained largely unexplored at scale for language modeling. This study aims to explore the impact of quantization for efficient pre-training of Transformers, with a focus on linear layer components. By systematically applying straightforward linear quantization to weights, activations, gradients, and optimizer states, we assess its effects on model efficiency, stability, and performance during training. By offering a comprehensive recipe of effective quantization strategies to be applied during the pre-training of Transformers, we promote high training efficiency from scratch while retaining language modeling ability. Code is available at https://github.com/chandar-lab/EfficientLLMs.
Acceleration of Convolutional Neural Network Using FFT-Based Split Convolutions
Apr 03, 2020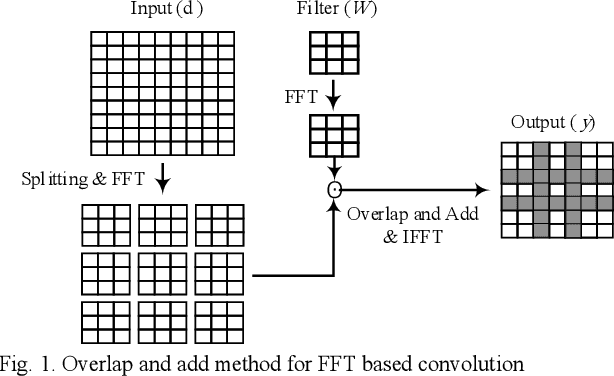
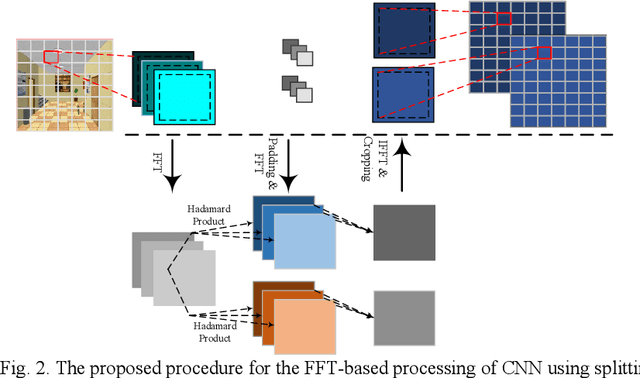
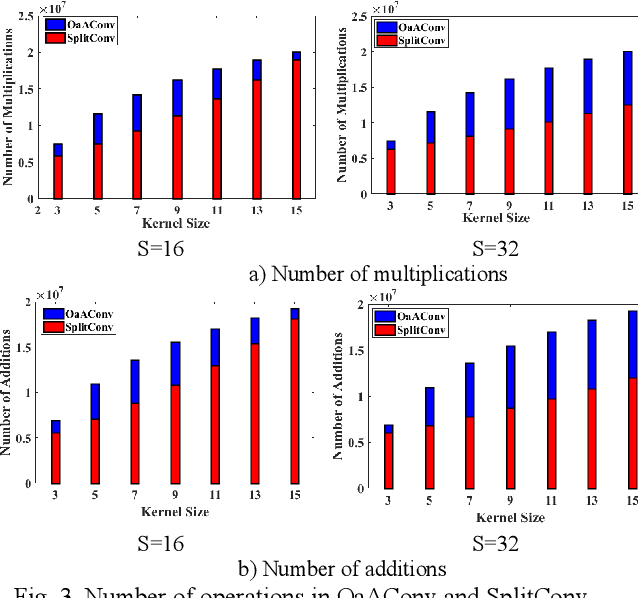
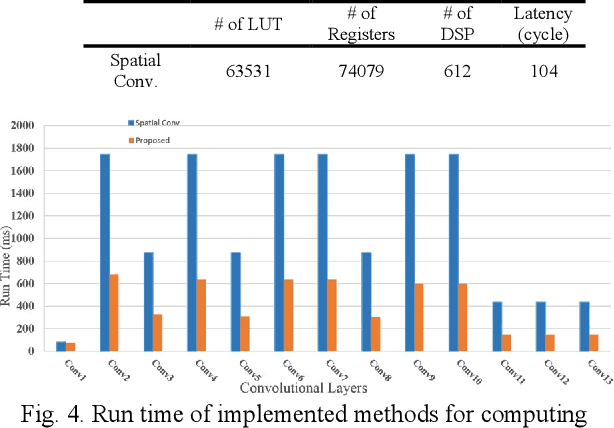
Convolutional neural networks (CNNs) have a large number of variables and hence suffer from a complexity problem for their implementation. Different methods and techniques have developed to alleviate the problem of CNN's complexity, such as quantization, pruning, etc. Among the different simplification methods, computation in the Fourier domain is regarded as a new paradigm for the acceleration of CNNs. Recent studies on Fast Fourier Transform (FFT) based CNN aiming at simplifying the computations required for FFT. However, there is a lot of space for working on the reduction of the computational complexity of FFT. In this paper, a new method for CNN processing in the FFT domain is proposed, which is based on input splitting. There are problems in the computation of FFT using small kernels in situations such as CNN. Splitting can be considered as an effective solution for such issues aroused by small kernels. Using splitting redundancy, such as overlap-and-add, is reduced and, efficiency is increased. Hardware implementation of the proposed FFT method, as well as different analyses of the complexity, are performed to demonstrate the proper performance of the proposed method.