 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistoFusionNet: Histogram-Guided Fusion and Frequency-Adaptive Refinement for Nighttime Image Dehazing
Apr 04, 2026Nighttime image dehazing remains a challenging low-level vision problem due to the joint presence of haze, glow, non-uniform illumination, color distortion, and sensor noise, which often invalidate assumptions commonly used in daytime dehazing. To address these challenges, we propose HistoFusionNet, a transformer-enhanced architecture tailored for nighttime image dehazing by combining histogram-guided representation learning with frequency-adaptive feature refinement. Built upon a multi-scale encoder-decoder backbone, our method introduces histogram transformer blocks that model long-range dependencies by grouping features according to their dynamic-range characteristics, enabling more effective aggregation of similarly degraded regions under complex nighttime lighting. To further improve restoration fidelity, we incorporate a frequency-aware refinement branch that adaptively exploits complementary low- and high-frequency cues, helping recover scene structures, suppress artifacts, and enhance local details. This design yields a unified framework that is particularly well suited to the heterogeneous degradations encountered in real nighttime hazy scenes. Extensive experiments and highly competitive performance of our method on the NTIRE 2026 Nighttime Image Dehazing Challenge benchmark demonstrate the effectiveness of the proposed method. Our team ranked 1st among 22 participating teams, highlighting the robustness and competitive performance of HistoFusionNet. The code is available at: https://github.com/heydarimo/Night-Time-Dehazing
Large Language Model-based Nonnegative Matrix Factorization For Cardiorespiratory Sound Separation
Feb 09, 2025This study represents the first integration of large language models (LLMs) with non-negative matrix factorization (NMF), marking a novel advancement in the source separation field. The LLM is employed in two unique ways: enhancing the separation results by providing detailed insights for disease prediction and operating in a feedback loop to optimize a fundamental frequency penalty added to the NMF cost function. We tested the algorithm on two datasets: 100 synthesized mixtures of real measurements, and 210 recordings of heart and lung sounds from a clinical manikin including both individual and mixed sounds, captured using a digital stethoscope. The approach consistently outperformed existing methods, demonstrating its potential to significantly enhance medical sound analysis for disease diagnostics.
BrightVAE: Luminosity Enhancement in Underexposed Endoscopic Images
Nov 22, 2024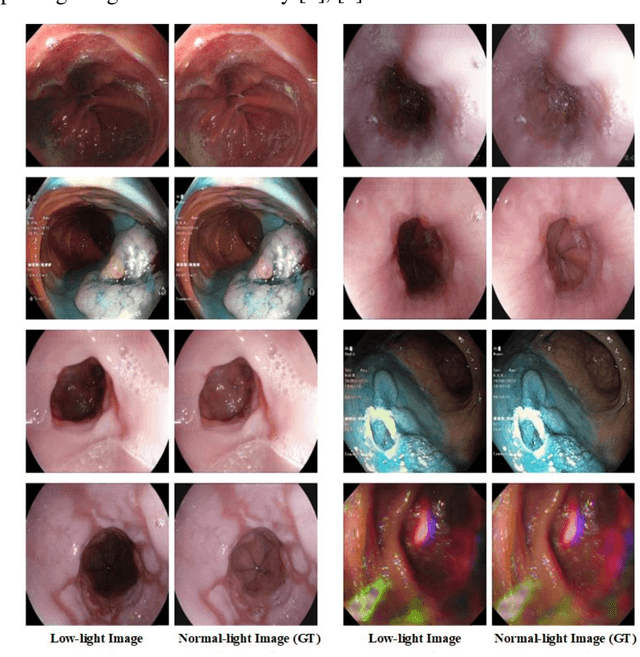
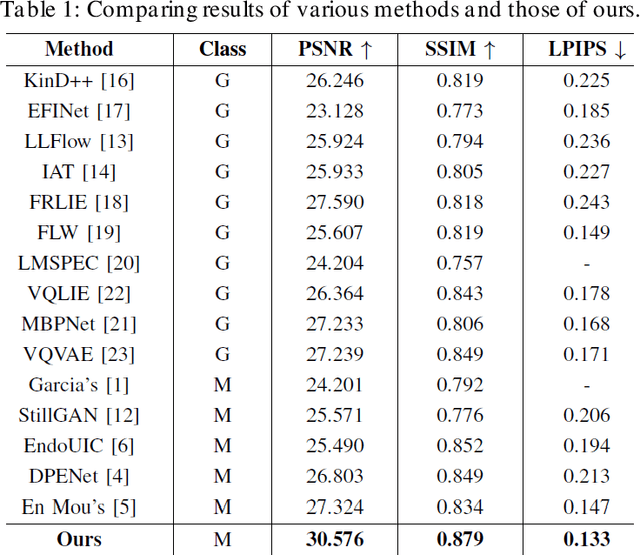
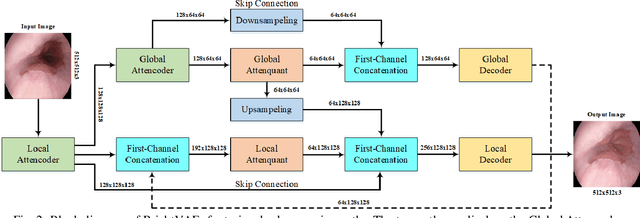

The enhancement of image luminosity is especially critical in endoscopic images. Underexposed endoscopic images often suffer from reduced contrast and uneven brightness, significantly impacting diagnostic accuracy and treatment planning. Internal body imaging is challenging due to uneven lighting and shadowy regions. Enhancing such images is essential since precise image interpretation is crucial for patient outcomes. In this paper, we introduce BrightVAE, an architecture based on the hierarchical Vector Quantized Variational Autoencoder (hierarchical VQ-VAE) tailored explicitly for enhancing luminosity in low-light endoscopic images. Our architecture is meticulously designed to tackle the unique challenges inherent in endoscopic imaging, such as significant variations in illumination and obscured details due to poor lighting conditions. The proposed model emphasizes advanced feature extraction from three distinct viewpoints-incorporating various receptive fields, skip connections, and feature attentions to robustly enhance image quality and support more accurate medical diagnoses. Through rigorous experimental analysis, we demonstrate the effectiveness of these techniques in enhancing low-light endoscopic images. To evaluate the performance of our architecture, we employ three widely recognized metrics-SSIM, PSNR, and LPIPS-specifically on Endo4IE dataset, which consists of endoscopic images. We evaluated our method using the Endo4IE dataset, which consists exclusively of endoscopic images, and showed significant advancements over the state-of-the-art methods for enhancing luminosity in endoscopic imaging.
Manikin-Recorded Cardiopulmonary Sounds Dataset Using Digital Stethoscope
Oct 04, 2024Heart and lung sounds are crucial for healthcare monitoring. Recent improvements in stethoscope technology have made it possible to capture patient sounds with enhanced precision. In this dataset, we used a digital stethoscope to capture both heart and lung sounds, including individual and mixed recordings. To our knowledge, this is the first dataset to offer both separate and mixed cardiorespiratory sounds. The recordings were collected from a clinical manikin, a patient simulator designed to replicate human physiological conditions, generating clean heart and lung sounds at different body locations. This dataset includes both normal sounds and various abnormalities (i.e., murmur, atrial fibrillation, tachycardia, atrioventricular block, third and fourth heart sound, wheezing, crackles, rhonchi, pleural rub, and gurgling sounds). The dataset includes audio recordings of chest examinations performed at different anatomical locations, as determined by specialist nurses. Each recording has been enhanced using frequency filters to highlight specific sound types. This dataset is useful for applications in artificial intelligence, such as automated cardiopulmonary disease detection, sound classification, unsupervised separation techniques, and deep learning algorithms related to audio signal processing.
Exploring Sensing Devices for Heart and Lung Sound Monitoring
Jun 18, 2024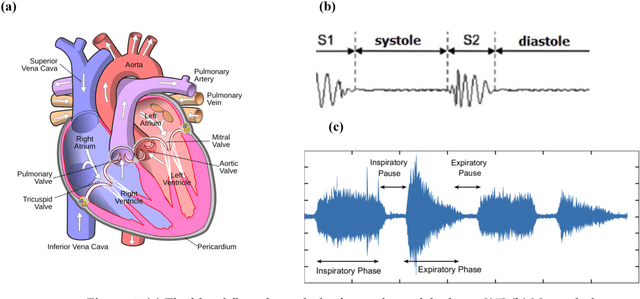


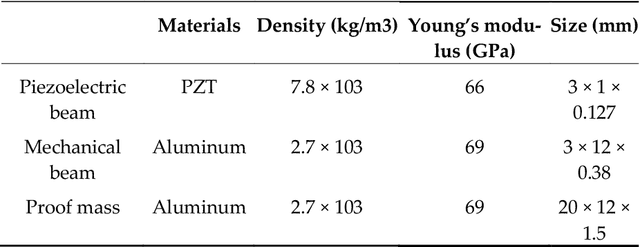
This paper presents a comprehensive review of cardiorespiratory auscultation sensing devices which is useful for understanding the theoretical aspects of sensing devices, as well as practical notes to design novel sensing devices. One of the methods to design a stethoscope is using electret condenser microphones (ECM). In this paper, we first introduce the acoustic properties of the heart and lungs, as well as a brief history of stethoscope evolution. Then, we discuss the basic concept of ECM sensors and a recent stethoscope based on this technology. In response to the limitations of ECM-based systems, we explore the potential of microelectromechanical systems (MEMS), particularly focusing on piezoelectric transducer (PZT) sensors. This paper comprehensively reviews sensing technologies, emphasizing innovative MEMS-based designs for wearable cardiopulmonary auscultation in the past decade. To our knowledge, this is the first paper to summarize ECM and MEMS applications for heart and lung sound analysis. Keywords: Micro-electro-mechanical Systems (MEMS); Electret Condenser Microphone (ECM); Wearable Sensing Devices; Cardiorespiratory Auscultation; Phonocardiography (PCG); Heart Sound; Lung Sound
Sequence-to-Sequence Multi-Modal Speech In-Painting
Jun 03, 2024

Speech in-painting is the task of regenerating missing audio contents using reliable context information. Despite various recent studies in multi-modal perception of audio in-painting, there is still a need for an effective infusion of visual and auditory information in speech in-painting. In this paper, we introduce a novel sequence-to-sequence model that leverages the visual information to in-paint audio signals via an encoder-decoder architecture. The encoder plays the role of a lip-reader for facial recordings and the decoder takes both encoder outputs as well as the distorted audio spectrograms to restore the original speech. Our model outperforms an audio-only speech in-painting model and has comparable results with a recent multi-modal speech in-painter in terms of speech quality and intelligibility metrics for distortions of 300 ms to 1500 ms duration, which proves the effectiveness of the introduced multi-modality in speech in-painting.
Robust Multi-Modal Speech In-Painting: A Sequence-to-Sequence Approach
Jun 02, 2024



The process of reconstructing missing parts of speech audio from context is called speech in-painting. Human perception of speech is inherently multi-modal, involving both audio and visual (AV) cues. In this paper, we introduce and study a sequence-to-sequence (seq2seq) speech in-painting model that incorporates AV features. Our approach extends AV speech in-painting techniques to scenarios where both audio and visual data may be jointly corrupted. To achieve this, we employ a multi-modal training paradigm that boosts the robustness of our model across various conditions involving acoustic and visual distortions. This makes our distortion-aware model a plausible solution for real-world challenging environments. We compare our method with existing transformer-based and recurrent neural network-based models, which attempt to reconstruct missing speech gaps ranging from a few milliseconds to over a second. Our experimental results demonstrate that our novel seq2seq architecture outperforms the state-of-the-art transformer solution by 38.8% in terms of enhancing speech quality and 7.14% in terms of improving speech intelligibility. We exploit a multi-task learning framework that simultaneously performs lip-reading (transcribing video components to text) while reconstructing missing parts of the associated speech.
A Parametric Rate-Distortion Model for Video Transcoding
Apr 13, 2024Over the past two decades, the surge in video streaming applications has been fueled by the increasing accessibility of the internet and the growing demand for network video. As users with varying internet speeds and devices seek high-quality video, transcoding becomes essential for service providers. In this paper, we introduce a parametric rate-distortion (R-D) transcoding model. Our model excels at predicting transcoding distortion at various rates without the need for encoding the video. This model serves as a versatile tool that can be used to achieve visual quality improvement (in terms of PSNR) via trans-sizing. Moreover, we use our model to identify visually lossless and near-zero-slope bitrate ranges for an ingest video. Having this information allows us to adjust the transcoding target bitrate while introducing visually negligible quality degradations. By utilizing our model in this manner, quality improvements up to 2 dB and bitrate savings of up to 46% of the original target bitrate are possible. Experimental results demonstrate the efficacy of our model in video transcoding rate distortion prediction.
High-Quality Live Video Streaming via Transcoding Time Prediction and Preset Selection
Dec 08, 2023



Video streaming often requires transcoding content into different resolutions and bitrates to match the recipient's internet speed and screen capabilities. Video encoders like x264 offer various presets, each with different tradeoffs between transcoding time and rate-distortion performance. Choosing the best preset for video transcoding is difficult, especially for live streaming, as trying all the presets and choosing the best one is not feasible. One solution is to predict each preset's transcoding time and select the preset that ensures the highest quality while adhering to live streaming time constraints. Prediction of video transcoding time is also critical in minimizing streaming delays, deploying resource management algorithms, and load balancing. We propose a learning-based framework for predicting the transcoding time of videos across various presets. Our predictor's features for video transcoding time prediction are derived directly from the ingested stream, primarily from the header or metadata. As a result, only minimal additional delay is incurred for feature extraction, rendering our approach ideal for live-streaming applications. We evaluated our learning-based transcoding time prediction using a dataset of videos. The results demonstrate that our framework can accurately predict the transcoding time for different presets, with a mean absolute percentage error (MAPE) of nearly 5.0%. Leveraging these predictions, we then select the most suitable transcoding preset for live video streaming. Utilizing our transcoding time prediction-based preset selection improved Peak Signal-to-Noise Ratio (PSNR) of up to 5 dB.
Supervised Deep Learning for Content-Aware Image Retargeting with Fourier Convolutions
Jun 12, 2023


Image retargeting aims to alter the size of the image with attention to the contents. One of the main obstacles to training deep learning models for image retargeting is the need for a vast labeled dataset. Labeled datasets are unavailable for training deep learning models in the image retargeting tasks. As a result, we present a new supervised approach for training deep learning models. We use the original images as ground truth and create inputs for the model by resizing and cropping the original images. A second challenge is generating different image sizes in inference time. However, regular convolutional neural networks cannot generate images of different sizes than the input image. To address this issue, we introduced a new method for supervised learning. In our approach, a mask is generated to show the desired size and location of the object. Then the mask and the input image are fed to the network. Comparing image retargeting methods and our proposed method demonstrates the model's ability to produce high-quality retargeted images. Afterward, we compute the image quality assessment score for each output image based on different techniques and illustrate the effectiveness of our approach.