 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrightVAE: Luminosity Enhancement in Underexposed Endoscopic Images
Nov 22, 2024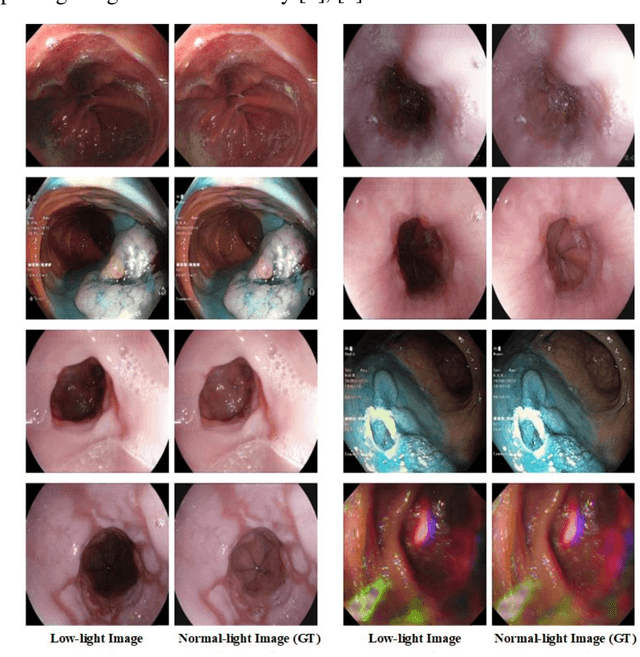
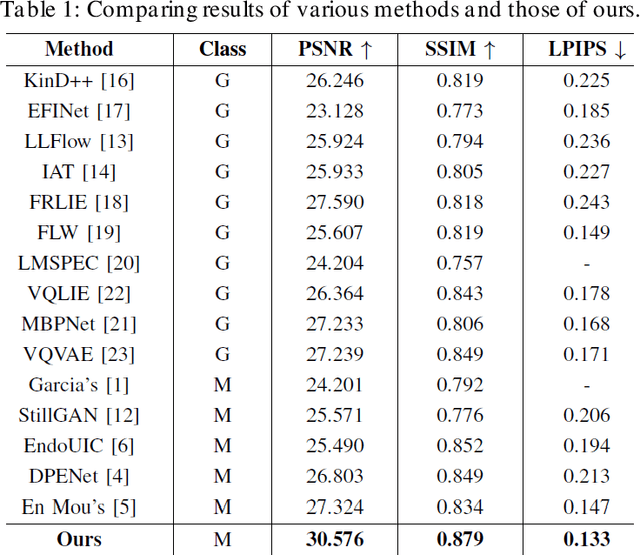
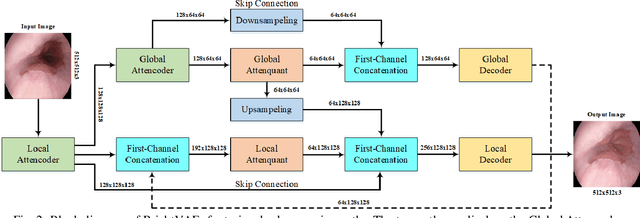

The enhancement of image luminosity is especially critical in endoscopic images. Underexposed endoscopic images often suffer from reduced contrast and uneven brightness, significantly impacting diagnostic accuracy and treatment planning. Internal body imaging is challenging due to uneven lighting and shadowy regions. Enhancing such images is essential since precise image interpretation is crucial for patient outcomes. In this paper, we introduce BrightVAE, an architecture based on the hierarchical Vector Quantized Variational Autoencoder (hierarchical VQ-VAE) tailored explicitly for enhancing luminosity in low-light endoscopic images. Our architecture is meticulously designed to tackle the unique challenges inherent in endoscopic imaging, such as significant variations in illumination and obscured details due to poor lighting conditions. The proposed model emphasizes advanced feature extraction from three distinct viewpoints-incorporating various receptive fields, skip connections, and feature attentions to robustly enhance image quality and support more accurate medical diagnoses. Through rigorous experimental analysis, we demonstrate the effectiveness of these techniques in enhancing low-light endoscopic images. To evaluate the performance of our architecture, we employ three widely recognized metrics-SSIM, PSNR, and LPIPS-specifically on Endo4IE dataset, which consists of endoscopic images. We evaluated our method using the Endo4IE dataset, which consists exclusively of endoscopic images, and showed significant advancements over the state-of-the-art methods for enhancing luminosity in endoscopic imaging.
DGAFF: Deep Genetic Algorithm Fitness Formation for EEG Bio-Signal Channel Selection
Feb 21, 2022



Brain-computer interface systems aim to facilitate human-computer interactions in a great deal by direct translation of brain signals for computers. Recently, using many electrodes has caused better performance in these systems. However, increasing the number of recorded electrodes leads to additional time, hardware, and computational costs besides undesired complications of the recording process. Channel selection has been utilized to decrease data dimension and eliminate irrelevant channels while reducing the noise effects. Furthermore, the technique lowers the time and computational costs in real-time applications. We present a channel selection method, which combines a sequential search method with a genetic algorithm called Deep GA Fitness Formation (DGAFF). The proposed method accelerates the convergence of the genetic algorithm and increases the system's performance. The system evaluation is based on a lightweight deep neural network that automates the whole model training process. The proposed method outperforms other channel selection methods in classifying motor imagery on the utilized dataset.
Image Inpainting Using AutoEncoder and Guided Selection of Predicted Pixels
Dec 17, 2021



Image inpainting is an effective method to enhance distorted digital images. Different inpainting methods use the information of neighboring pixels to predict the value of missing pixels. Recently deep neural networks have been used to learn structural and semantic details of images for inpainting purposes. In this paper, we propose a network for image inpainting. This network, similar to U-Net, extracts various features from images, leading to better results. We improved the final results by replacing the damaged pixels with the recovered pixels of the output images. Our experimental results show that this method produces high-quality results compare to the traditional methods.
MSGDD-cGAN: Multi-Scale Gradients Dual Discriminator Conditional Generative Adversarial Network
Sep 12, 2021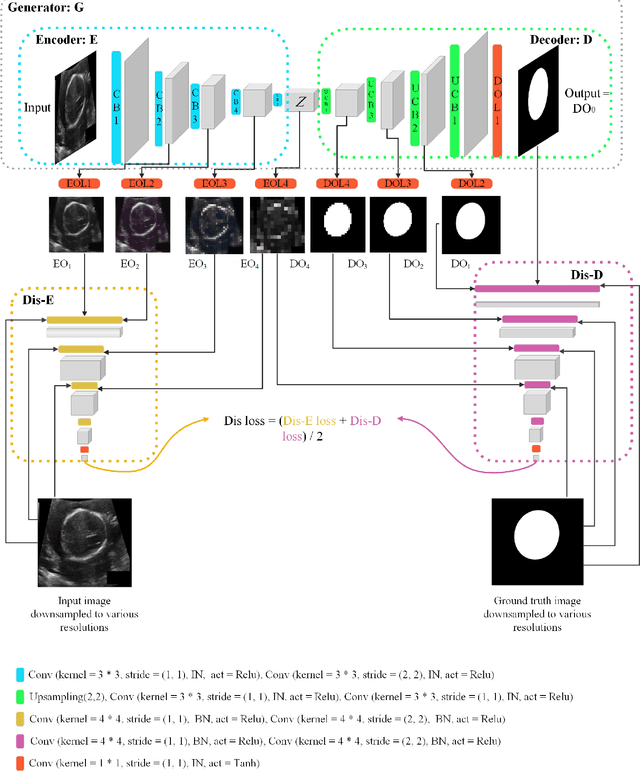

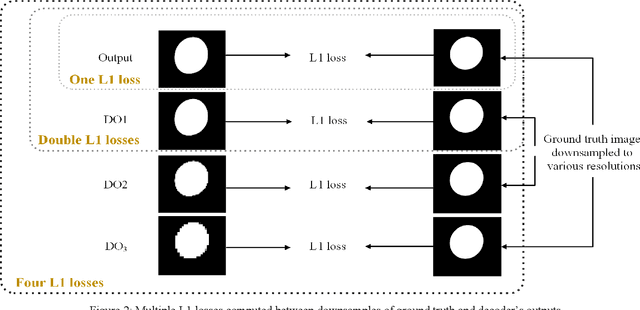

Conditional Generative Adversarial Networks (cGANs) have been used in many image processing tasks. However, they still have serious problems maintaining the balance between conditioning the output on the input and creating the output with the desired distribution based on the corresponding ground truth. The traditional cGANs, similar to most conventional GANs, suffer from vanishing gradients, which backpropagate from the discriminator to the generator. Moreover, the traditional cGANs are sensitive to architectural changes due to previously mentioned gradient problems. Therefore, balancing the architecture of the cGANs is almost impossible. Recently MSG-GAN has been proposed to stabilize the performance of the GANs by applying multiple connections between the generator and discriminator. In this work, we propose a method called MSGDD-cGAN, which first stabilizes the performance of the cGANs using multi-connections gradients flow. Secondly, the proposed network architecture balances the correlation of the output to input and the fitness of the output on the target distribution. This balance is generated by using the proposed dual discrimination procedure. We tested our model by segmentation of fetal ultrasound images. Our model shows a 3.18% increase in the F1 score comparing to the pix2pix version of cGANs.
Region of Interest Identification for Brain Tumors in Magnetic Resonance Images
Feb 26, 2020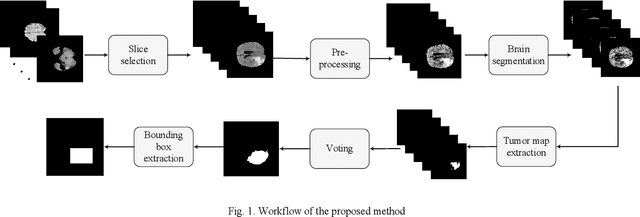

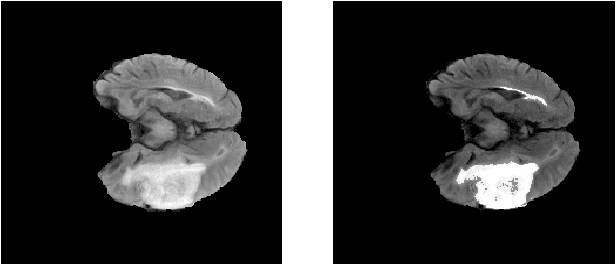

Glioma is a common type of brain tumor, and accurate detection of it plays a vital role in the diagnosis and treatment process. Despite advances in medical image analyzing, accurate tumor segmentation in brain magnetic resonance (MR) images remains a challenge due to variations in tumor texture, position, and shape. In this paper, we propose a fast, automated method, with light computational complexity, to find the smallest bounding box around the tumor region. This region-of-interest can be used as a preprocessing step in training networks for subregion tumor segmentation. By adopting the outputs of this algorithm, redundant information is removed; hence the network can focus on learning notable features related to subregions' classes. The proposed method has six main stages, in which the brain segmentation is the most vital step. Expectation-maximization (EM) and K-means algorithms are used for brain segmentation. The proposed method is evaluated on the BraTS 2015 dataset, and the average gained DICE score is 0.73, which is an acceptable result for this application.
Image Inpainting by Multiscale Spline Interpolation
Jan 10, 2020
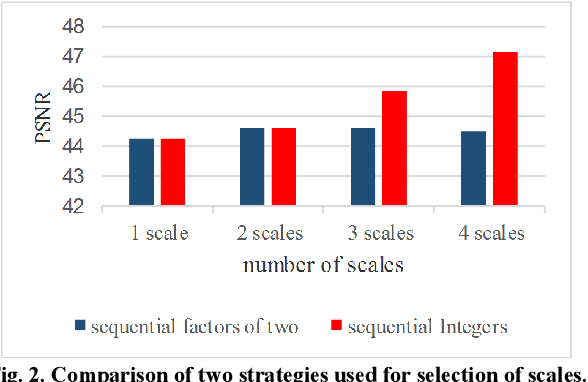


Recovering the missing regions of an image is a task that is called image inpainting. Depending on the shape of missing areas, different methods are presented in the literature. One of the challenges of this problem is extracting features that lead to better results. Experimental results show that both global and local features are useful for this purpose. In this paper, we propose a multi-scale image inpainting method that utilizes both local and global features. The first step of this method is to determine how many scales we need to use, which depends on the width of the lines in the map of the missing region. Then we apply adaptive image inpainting to the damaged areas of the image, and the lost pixels are predicted. Each scale is inpainted and the result is resized to the original size. Then a voting process produces the final result. The proposed method is tested on damaged images with scratches and creases. The metric that we use to evaluate our approach is PSNR. On average, we achieved 1.2 dB improvement over some existing inpainting approaches.
A General Framework for Saliency Detection Methods
Dec 27, 2019
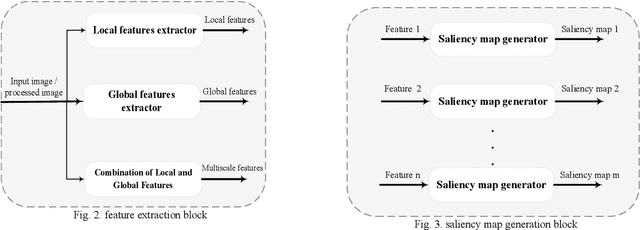
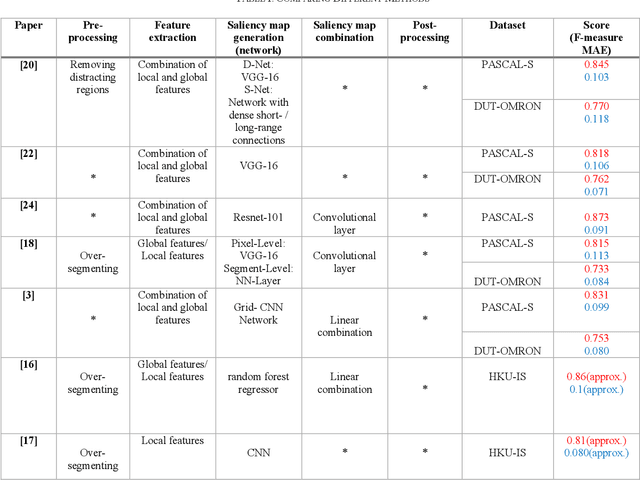
Saliency detection is one of the most challenging problems in the fields of image analysis and computer vision. Many approaches propose different architectures based on the psychological and biological properties of the human visual attention system. However, there is not still an abstract framework, which summarized the existed methods. In this paper, we offered a general framework for saliency models, which consists of five main steps: pre-processing, feature extraction, saliency map generation, saliency map combination, and post-processing. Also, we study different saliency models containing each level and compare their performance together. This framework helps researchers to have a comprehensive view of studying new methods.
An Abstraction Model for Semantic Segmentation Algorithms
Dec 27, 2019


Semantic segmentation is a process of classifying each pixel in the image. Due to its advantages, sematic segmentation is used in many tasks such as cancer detection, robot-assisted surgery, satellite image analysis, self-driving car control, etc. In this process, accuracy and efficiency are the two crucial goals for this purpose, and there are several state of the art neural networks. In each method, by employing different techniques, new solutions have been presented for increasing efficiency, accuracy, and reducing the costs. The diversity of the implemented approaches for semantic segmentation makes it difficult for researches to achieve a comprehensive view of the field. To offer a comprehensive view, in this paper, an abstraction model for the task of semantic segmentation is offered. The proposed framework consists of four general blocks that cover the majority of majority of methods that have been proposed for semantic segmentation. We also compare different approaches and consider the importance of each part in the overall performance of a method.
Image Inpainting by Adaptive Fusion of Variable Spline Interpolations
Nov 03, 2019


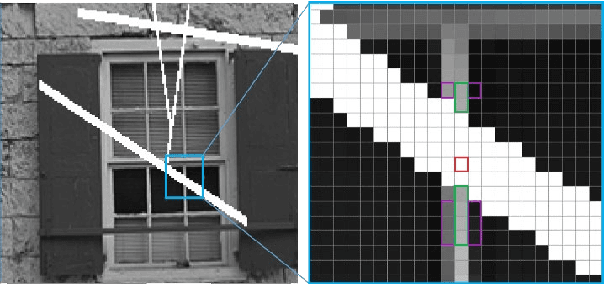
There are many methods for image enhancement. Image inpainting is one of them which could be used in reconstruction and restoration of scratch images or editing images by adding or removing objects. According to its application, different algorithmic and learning methods are proposed. In this paper, the focus is on applications, which enhance the old and historical scratched images. For this purpose, we proposed an adaptive spline interpolation. In this method, a different number of neighbors in four directions are considered for each pixel in the lost block. In the previous methods, predicting the lost pixels that are on edges is the problem. To address this problem, we consider horizontal and vertical edge information. If the pixel is located on an edge, then we use the predicted value in that direction. In other situations, irrelevant predicted values are omitted, and the average of rest values is used as the value of the missing pixel. The method evaluates by PSNR and SSIM metrics on the Kodak dataset. The results show improvement in PSNR and SSIM compared to similar procedures. Also, the run time of the proposed method outperforms others.