 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrightVAE: Luminosity Enhancement in Underexposed Endoscopic Images
Nov 22, 2024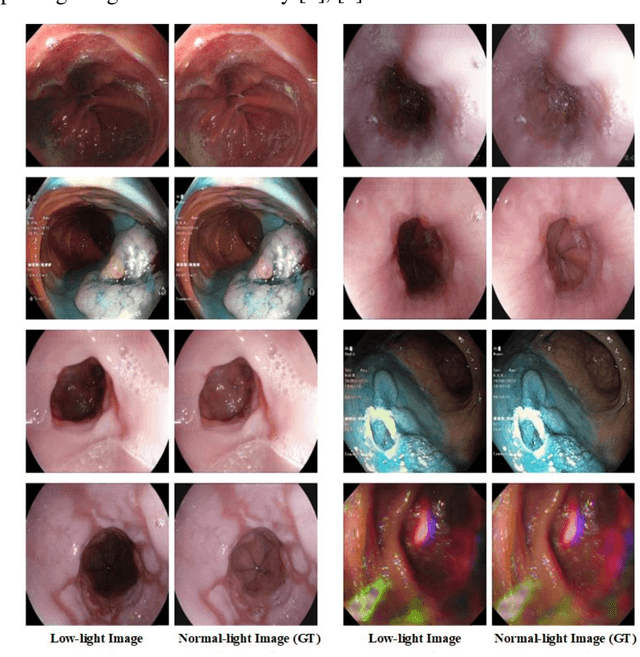
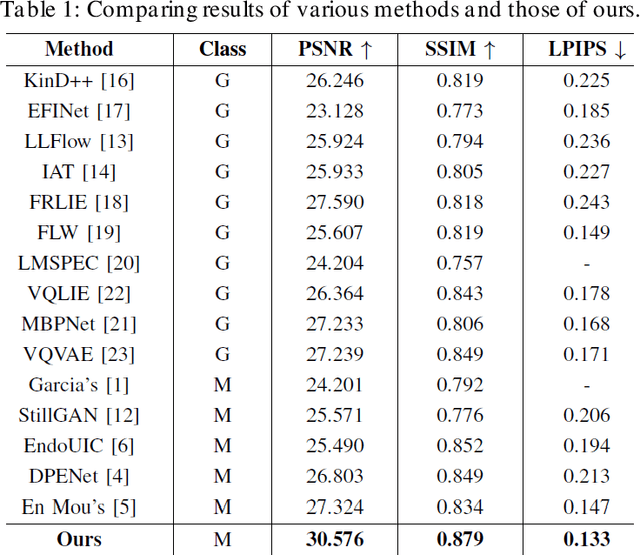
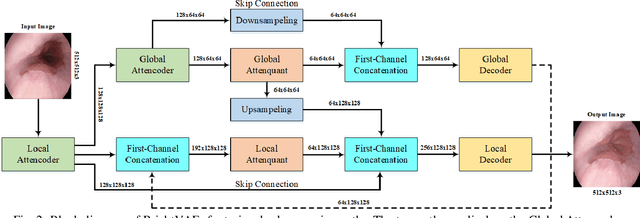

The enhancement of image luminosity is especially critical in endoscopic images. Underexposed endoscopic images often suffer from reduced contrast and uneven brightness, significantly impacting diagnostic accuracy and treatment planning. Internal body imaging is challenging due to uneven lighting and shadowy regions. Enhancing such images is essential since precise image interpretation is crucial for patient outcomes. In this paper, we introduce BrightVAE, an architecture based on the hierarchical Vector Quantized Variational Autoencoder (hierarchical VQ-VAE) tailored explicitly for enhancing luminosity in low-light endoscopic images. Our architecture is meticulously designed to tackle the unique challenges inherent in endoscopic imaging, such as significant variations in illumination and obscured details due to poor lighting conditions. The proposed model emphasizes advanced feature extraction from three distinct viewpoints-incorporating various receptive fields, skip connections, and feature attentions to robustly enhance image quality and support more accurate medical diagnoses. Through rigorous experimental analysis, we demonstrate the effectiveness of these techniques in enhancing low-light endoscopic images. To evaluate the performance of our architecture, we employ three widely recognized metrics-SSIM, PSNR, and LPIPS-specifically on Endo4IE dataset, which consists of endoscopic images. We evaluated our method using the Endo4IE dataset, which consists exclusively of endoscopic images, and showed significant advancements over the state-of-the-art methods for enhancing luminosity in endoscopic imaging.
A Parametric Rate-Distortion Model for Video Transcoding
Apr 13, 2024Over the past two decades, the surge in video streaming applications has been fueled by the increasing accessibility of the internet and the growing demand for network video. As users with varying internet speeds and devices seek high-quality video, transcoding becomes essential for service providers. In this paper, we introduce a parametric rate-distortion (R-D) transcoding model. Our model excels at predicting transcoding distortion at various rates without the need for encoding the video. This model serves as a versatile tool that can be used to achieve visual quality improvement (in terms of PSNR) via trans-sizing. Moreover, we use our model to identify visually lossless and near-zero-slope bitrate ranges for an ingest video. Having this information allows us to adjust the transcoding target bitrate while introducing visually negligible quality degradations. By utilizing our model in this manner, quality improvements up to 2 dB and bitrate savings of up to 46% of the original target bitrate are possible. Experimental results demonstrate the efficacy of our model in video transcoding rate distortion prediction.
A lightweight deep learning pipeline with DRDA-Net and MobileNet for breast cancer classification
Mar 17, 2024



Accurate and early detection of breast cancer is essential for successful treatment. This paper introduces a novel deep-learning approach for improved breast cancer classification in histopathological images, a crucial step in diagnosis. Our method hinges on the Dense Residual Dual-Shuffle Attention Network (DRDA-Net), inspired by ShuffleNet's efficient architecture. DRDA-Net achieves exceptional accuracy across various magnification levels on the BreaKHis dataset, a breast cancer histopathology analysis benchmark. However, for real-world deployment, computational efficiency is paramount. We integrate a pre-trained MobileNet model renowned for its lightweight design to address computational. MobileNet ensures fast execution even on devices with limited resources without sacrificing performance. This combined approach offers a promising solution for accurate breast cancer diagnosis, paving the way for faster and more accessible screening procedures.
Revealing Shadows: Low-Light Image Enhancement Using Self-Calibrated Illumination
Dec 23, 2023



In digital imaging, enhancing visual content in poorly lit environments is a significant challenge, as images often suffer from inadequate brightness, hidden details, and an overall reduction in quality. This issue is especially critical in applications like nighttime surveillance, astrophotography, and low-light videography, where clear and detailed visual information is crucial. Our research addresses this problem by enhancing the illumination aspect of dark images. We have advanced past techniques by using varied color spaces to extract the illumination component, enhance it, and then recombine it with the other components of the image. By employing the Self-Calibrated Illumination (SCI) method, a strategy initially developed for RGB images, we effectively intensify and clarify details that are typically lost in low-light conditions. This method of selective illumination enhancement leaves the color information intact, thus preserving the color integrity of the image. Crucially, our method eliminates the need for paired images, making it suitable for situations where they are unavailable. Implementing the modified SCI technique represents a substantial shift from traditional methods, providing a refined and potent solution for low-light image enhancement. Our approach sets the stage for more complex image processing techniques and extends the range of possible real-world applications where accurate color representation and improved visibility are essential.
High-Quality Live Video Streaming via Transcoding Time Prediction and Preset Selection
Dec 08, 2023



Video streaming often requires transcoding content into different resolutions and bitrates to match the recipient's internet speed and screen capabilities. Video encoders like x264 offer various presets, each with different tradeoffs between transcoding time and rate-distortion performance. Choosing the best preset for video transcoding is difficult, especially for live streaming, as trying all the presets and choosing the best one is not feasible. One solution is to predict each preset's transcoding time and select the preset that ensures the highest quality while adhering to live streaming time constraints. Prediction of video transcoding time is also critical in minimizing streaming delays, deploying resource management algorithms, and load balancing. We propose a learning-based framework for predicting the transcoding time of videos across various presets. Our predictor's features for video transcoding time prediction are derived directly from the ingested stream, primarily from the header or metadata. As a result, only minimal additional delay is incurred for feature extraction, rendering our approach ideal for live-streaming applications. We evaluated our learning-based transcoding time prediction using a dataset of videos. The results demonstrate that our framework can accurately predict the transcoding time for different presets, with a mean absolute percentage error (MAPE) of nearly 5.0%. Leveraging these predictions, we then select the most suitable transcoding preset for live video streaming. Utilizing our transcoding time prediction-based preset selection improved Peak Signal-to-Noise Ratio (PSNR) of up to 5 dB.
Supervised Deep Learning for Content-Aware Image Retargeting with Fourier Convolutions
Jun 12, 2023


Image retargeting aims to alter the size of the image with attention to the contents. One of the main obstacles to training deep learning models for image retargeting is the need for a vast labeled dataset. Labeled datasets are unavailable for training deep learning models in the image retargeting tasks. As a result, we present a new supervised approach for training deep learning models. We use the original images as ground truth and create inputs for the model by resizing and cropping the original images. A second challenge is generating different image sizes in inference time. However, regular convolutional neural networks cannot generate images of different sizes than the input image. To address this issue, we introduced a new method for supervised learning. In our approach, a mask is generated to show the desired size and location of the object. Then the mask and the input image are fed to the network. Comparing image retargeting methods and our proposed method demonstrates the model's ability to produce high-quality retargeted images. Afterward, we compute the image quality assessment score for each output image based on different techniques and illustrate the effectiveness of our approach.
Endoscopy Classification Model Using Swin Transformer and Saliency Map
Mar 12, 2023


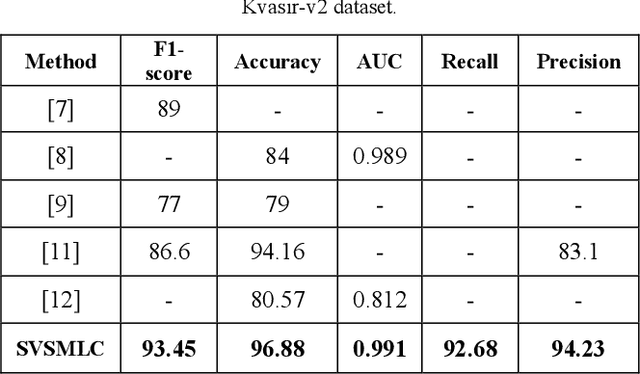
Endoscopy is a valuable tool for the early diagnosis of colon cancer. However, it requires the expertise of endoscopists and is a time-consuming process. In this work, we propose a new multi-label classification method, which considers two aspects of learning approaches (local and global views) for endoscopic image classification. The model consists of a Swin transformer branch and a modified VGG16 model as a CNN branch. To help the learning process of the CNN branch, the model employs saliency maps and endoscopy images and concatenates them. The results demonstrate that this method performed well for endoscopic medical images by utilizing local and global features of the images. Furthermore, quantitative evaluations prove the proposed method's superiority over state-of-the-art works.
SFI-Swin: Symmetric Face Inpainting with Swin Transformer by Distinctly Learning Face Components Distributions
Jan 09, 2023



Image inpainting consists of filling holes or missing parts of an image. Inpainting face images with symmetric characteristics is more challenging than inpainting a natural scene. None of the powerful existing models can fill out the missing parts of an image while considering the symmetry and homogeneity of the picture. Moreover, the metrics that assess a repaired face image quality cannot measure the preservation of symmetry between the rebuilt and existing parts of a face. In this paper, we intend to solve the symmetry problem in the face inpainting task by using multiple discriminators that check each face organ's reality separately and a transformer-based network. We also propose "symmetry concentration score" as a new metric for measuring the symmetry of a repaired face image. The quantitative and qualitative results show the superiority of our proposed method compared to some of the recently proposed algorithms in terms of the reality, symmetry, and homogeneity of the inpainted parts.
Adaptive Blind Watermarking Using Psychovisual Image Features
Dec 25, 2022With the growth of editing and sharing images through the internet, the importance of protecting the images' authorship has increased. Robust watermarking is a known approach to maintaining copyright protection. Robustness and imperceptibility are two factors that are tried to be maximized through watermarking. Usually, there is a trade-off between these two parameters. Increasing the robustness would lessen the imperceptibility of the watermarking. This paper proposes an adaptive method that determines the strength of the watermark embedding in different parts of the cover image regarding its texture and brightness. Adaptive embedding increases the robustness while preserving the quality of the watermarked image. Experimental results also show that the proposed method can effectively reconstruct the embedded payload in different kinds of common watermarking attacks. Our proposed method has shown good performance compared to a recent technique.
Focal-UNet: UNet-like Focal Modulation for Medical Image Segmentation
Dec 19, 2022



Recently, many attempts have been made to construct a transformer base U-shaped architecture, and new methods have been proposed that outperformed CNN-based rivals. However, serious problems such as blockiness and cropped edges in predicted masks remain because of transformers' patch partitioning operations. In this work, we propose a new U-shaped architecture for medical image segmentation with the help of the newly introduced focal modulation mechanism. The proposed architecture has asymmetric depths for the encoder and decoder. Due to the ability of the focal module to aggregate local and global features, our model could simultaneously benefit the wide receptive field of transformers and local viewing of CNNs. This helps the proposed method balance the local and global feature usage to outperform one of the most powerful transformer-based U-shaped models called Swin-UNet. We achieved a 1.68% higher DICE score and a 0.89 better HD metric on the Synapse dataset. Also, with extremely limited data, we had a 4.25% higher DICE score on the NeoPolyp dataset. Our implementations are available at: https://github.com/givkashi/Focal-UNet