 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic-Pix2Pix: Noise Injected cGAN for Modeling Input and Target Domain Joint Distributions with Limited Training Data
Nov 15, 2022Learning to translate images from a source to a target domain with applications such as converting simple line drawing to oil painting has attracted significant attention. The quality of translated images is directly related to two crucial issues. First, the consistency of the output distribution with that of the target is essential. Second, the generated output should have a high correlation with the input. Conditional Generative Adversarial Networks, cGANs, are the most common models for translating images. The performance of a cGAN drops when we use a limited training dataset. In this work, we increase the Pix2Pix (a form of cGAN) target distribution modeling ability with the help of dynamic neural network theory. Our model has two learning cycles. The model learns the correlation between input and ground truth in the first cycle. Then, the model's architecture is refined in the second cycle to learn the target distribution from noise input. These processes are executed in each iteration of the training procedure. Helping the cGAN learn the target distribution from noise input results in a better model generalization during the test time and allows the model to fit almost perfectly to the target domain distribution. As a result, our model surpasses the Pix2Pix model in segmenting HC18 and Montgomery's chest x-ray images. Both qualitative and Dice scores show the superiority of our model. Although our proposed method does not use thousand of additional data for pretraining, it produces comparable results for the in and out-domain generalization compared to the state-of-the-art methods.
MSGDD-cGAN: Multi-Scale Gradients Dual Discriminator Conditional Generative Adversarial Network
Sep 12, 2021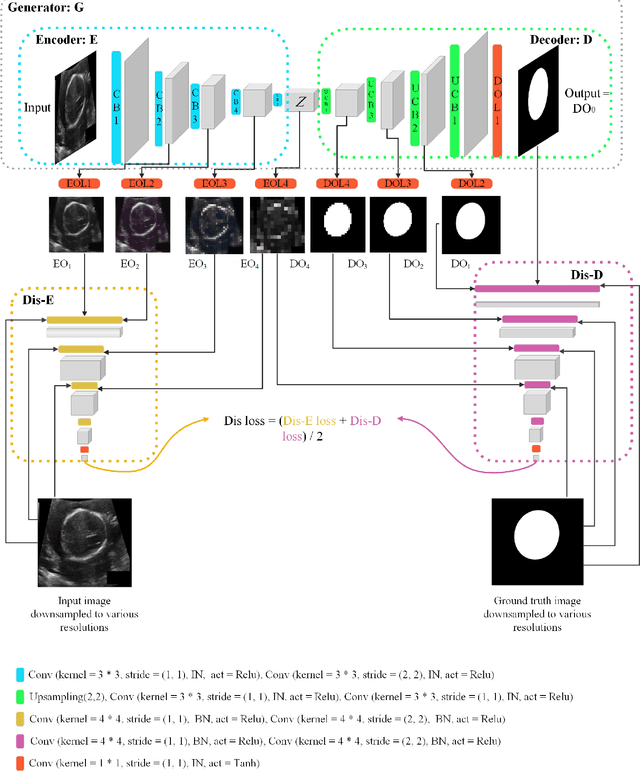

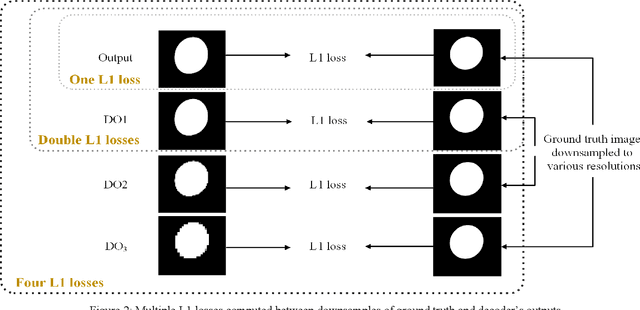

Conditional Generative Adversarial Networks (cGANs) have been used in many image processing tasks. However, they still have serious problems maintaining the balance between conditioning the output on the input and creating the output with the desired distribution based on the corresponding ground truth. The traditional cGANs, similar to most conventional GANs, suffer from vanishing gradients, which backpropagate from the discriminator to the generator. Moreover, the traditional cGANs are sensitive to architectural changes due to previously mentioned gradient problems. Therefore, balancing the architecture of the cGANs is almost impossible. Recently MSG-GAN has been proposed to stabilize the performance of the GANs by applying multiple connections between the generator and discriminator. In this work, we propose a method called MSGDD-cGAN, which first stabilizes the performance of the cGANs using multi-connections gradients flow. Secondly, the proposed network architecture balances the correlation of the output to input and the fitness of the output on the target distribution. This balance is generated by using the proposed dual discrimination procedure. We tested our model by segmentation of fetal ultrasound images. Our model shows a 3.18% increase in the F1 score comparing to the pix2pix version of cGANs.