 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo Shots: Few-Shot Learning with Auxiliary Data
Jan 16, 2021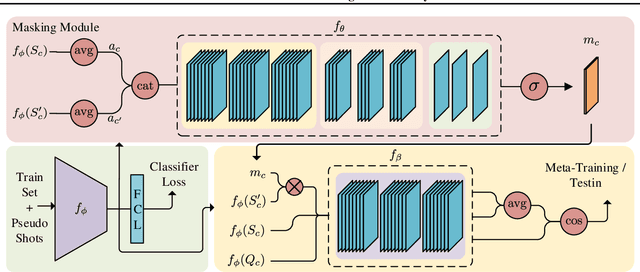
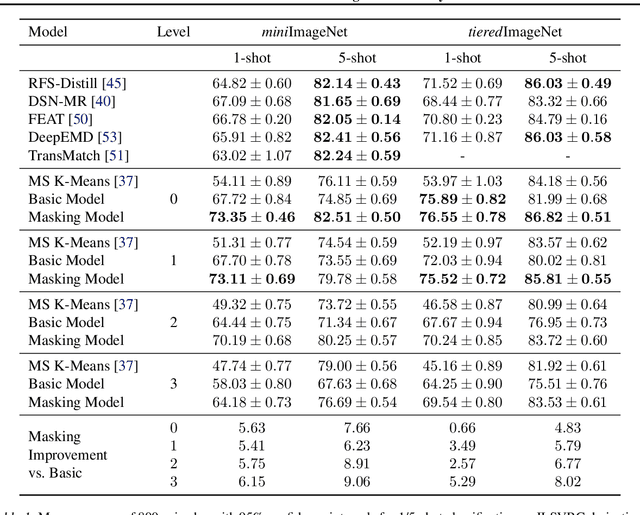
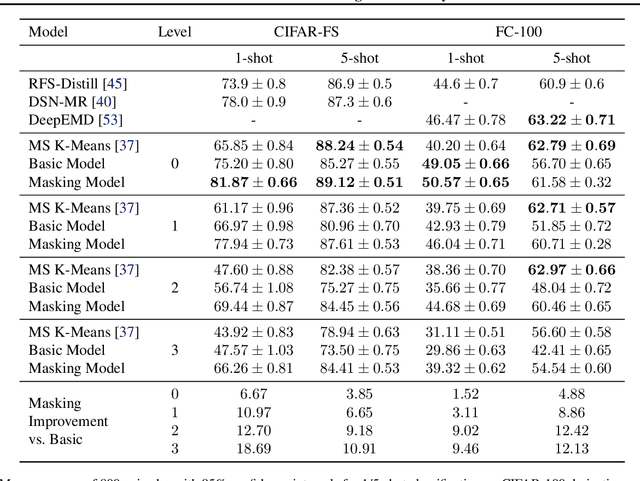

In many practical few-shot learning problems, even though labeled examples are scarce, there are abundant auxiliary data sets that potentially contain useful information. We propose a framework to address the challenges of efficiently selecting and effectively using auxiliary data in image classification. Given an auxiliary dataset and a notion of semantic similarity among classes, we automatically select pseudo shots, which are labeled examples from other classes related to the target task. We show that naively assuming that these additional examples come from the same distribution as the target task examples does not significantly improve accuracy. Instead, we propose a masking module that adjusts the features of auxiliary data to be more similar to those of the target classes. We show that this masking module can improve accuracy by up to 18 accuracy points, particularly when the auxiliary data is semantically distant from the target task. We also show that incorporating pseudo shots improves over the current state-of-the-art few-shot image classification scores by an average of 4.81 percentage points of accuracy on 1-shot tasks and an average of 0.31 percentage points on 5-shot tasks.
Classification of Diabetic Retinopathy Using Unlabeled Data and Knowledge Distillation
Sep 01, 2020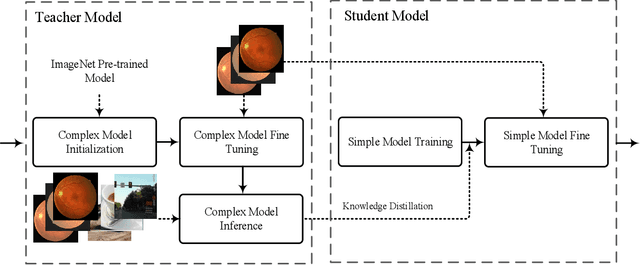
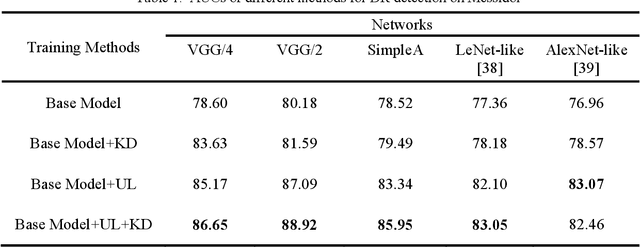
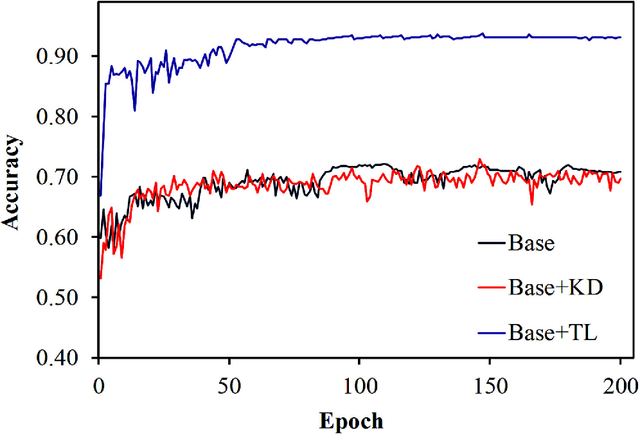
Knowledge distillation allows transferring knowledge from a pre-trained model to another. However, it suffers from limitations, and constraints related to the two models need to be architecturally similar. Knowledge distillation addresses some of the shortcomings associated with transfer learning by generalizing a complex model to a lighter model. However, some parts of the knowledge may not be distilled by knowledge distillation sufficiently. In this paper, a novel knowledge distillation approach using transfer learning is proposed. The proposed method transfers the entire knowledge of a model to a new smaller one. To accomplish this, unlabeled data are used in an unsupervised manner to transfer the maximum amount of knowledge to the new slimmer model. The proposed method can be beneficial in medical image analysis, where labeled data are typically scarce. The proposed approach is evaluated in the context of classification of images for diagnosing Diabetic Retinopathy on two publicly available datasets, including Messidor and EyePACS. Simulation results demonstrate that the approach is effective in transferring knowledge from a complex model to a lighter one. Furthermore, experimental results illustrate that the performance of different small models is improved significantly using unlabeled data and knowledge distillation.
Acceleration of Convolutional Neural Network Using FFT-Based Split Convolutions
Apr 03, 2020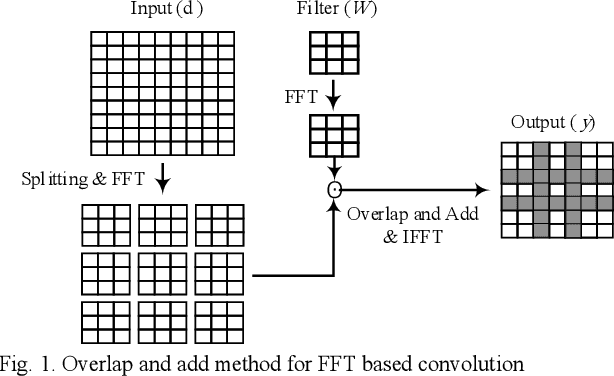
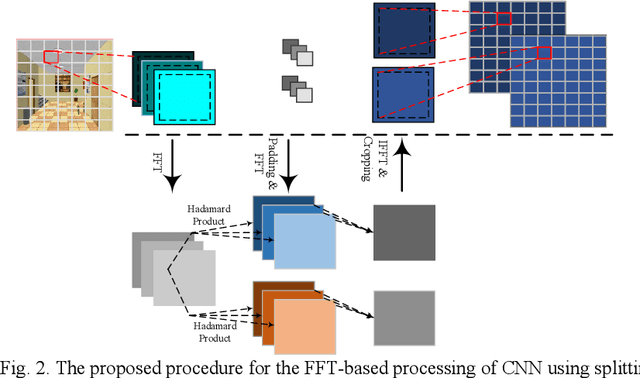
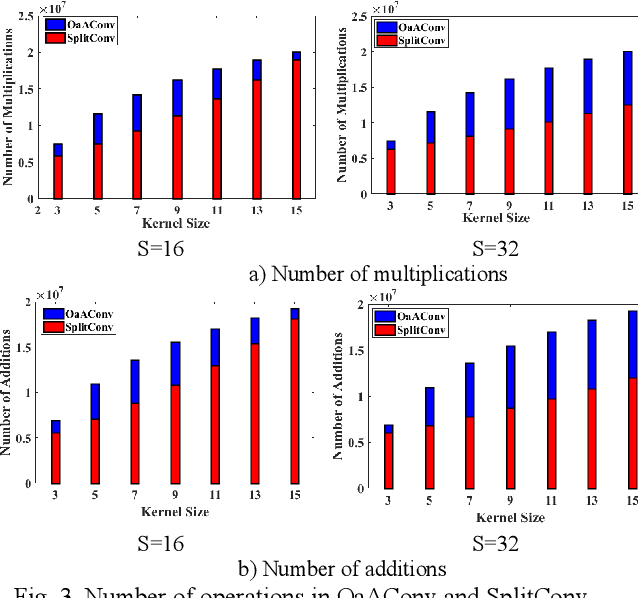
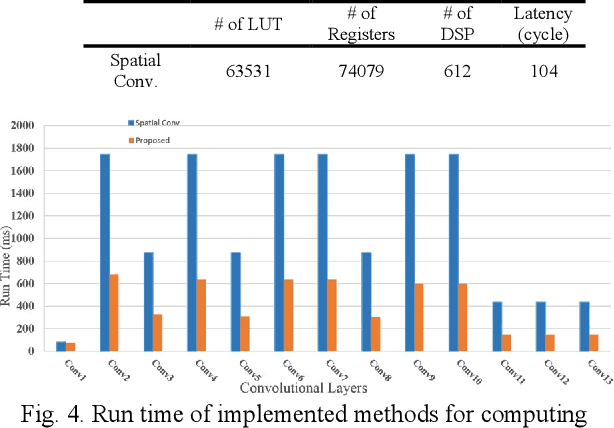
Convolutional neural networks (CNNs) have a large number of variables and hence suffer from a complexity problem for their implementation. Different methods and techniques have developed to alleviate the problem of CNN's complexity, such as quantization, pruning, etc. Among the different simplification methods, computation in the Fourier domain is regarded as a new paradigm for the acceleration of CNNs. Recent studies on Fast Fourier Transform (FFT) based CNN aiming at simplifying the computations required for FFT. However, there is a lot of space for working on the reduction of the computational complexity of FFT. In this paper, a new method for CNN processing in the FFT domain is proposed, which is based on input splitting. There are problems in the computation of FFT using small kernels in situations such as CNN. Splitting can be considered as an effective solution for such issues aroused by small kernels. Using splitting redundancy, such as overlap-and-add, is reduced and, efficiency is increased. Hardware implementation of the proposed FFT method, as well as different analyses of the complexity, are performed to demonstrate the proper performance of the proposed method.
Unlabeled Data Deployment for Classification of Diabetic Retinopathy Images Using Knowledge Transfer
Feb 09, 2020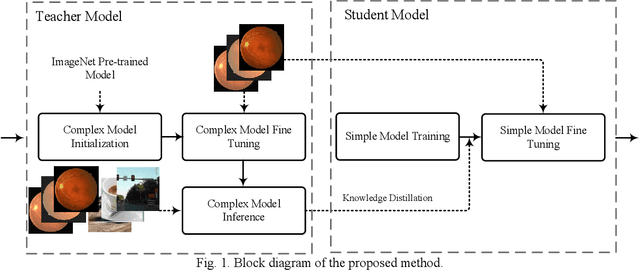
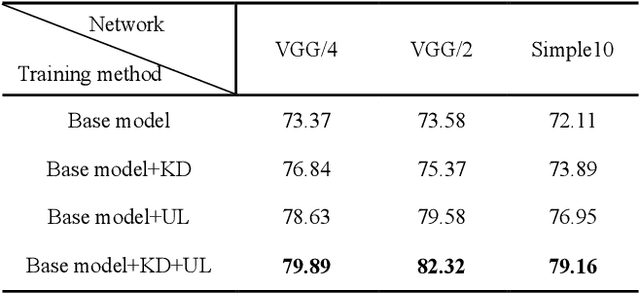
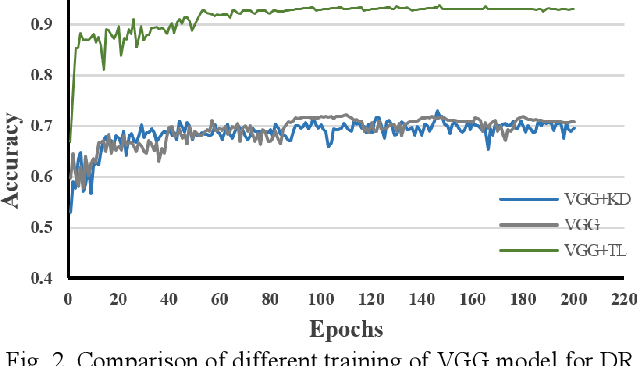
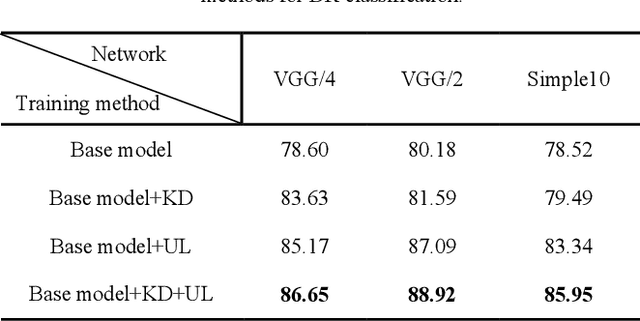
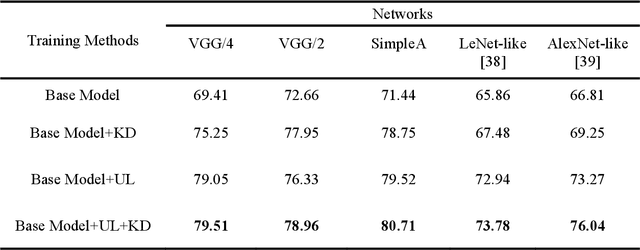
Convolutional neural networks (CNNs) are extensively beneficial for medical image processing. Medical images are plentiful, but there is a lack of annotated data. Transfer learning is used to solve the problem of lack of labeled data and grants CNNs better training capability. Transfer learning can be used in many different medical applications; however, the model under transfer should have the same size as the original network. Knowledge distillation is recently proposed to transfer the knowledge of a model to another one and can be useful to cover the shortcomings of transfer learning. But some parts of the knowledge may not be distilled by knowledge distillation. In this paper, a novel knowledge distillation using transfer learning is proposed to transfer the whole knowledge of a model to another one. The proposed method can be beneficial and practical for medical image analysis in which a small number of labeled data are available. The proposed process is tested for diabetic retinopathy classification. Simulation results demonstrate that using the proposed method, knowledge of an extensive network can be transferred to a smaller model.
Splitting Convolutional Neural Network Structures for Efficient Inference
Feb 09, 2020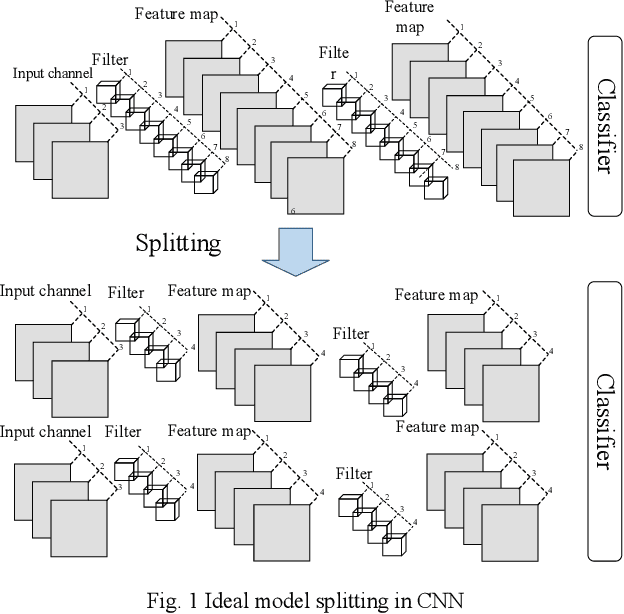
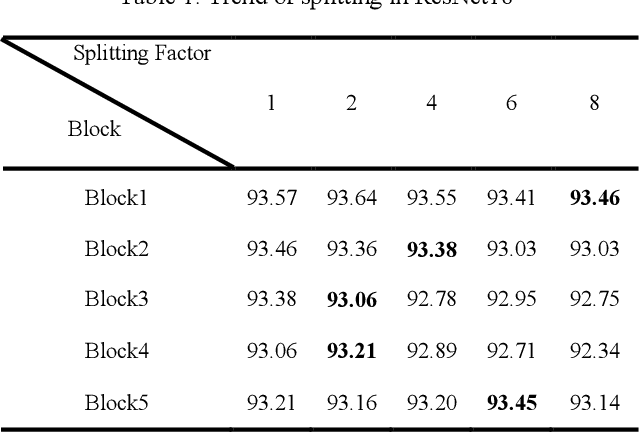
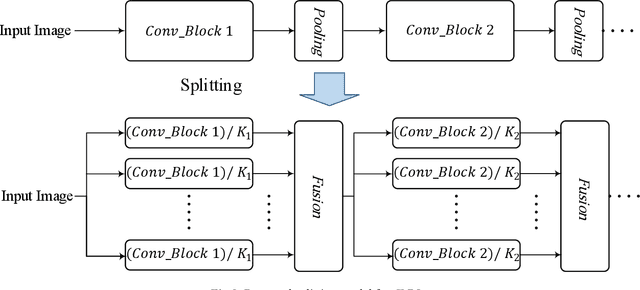
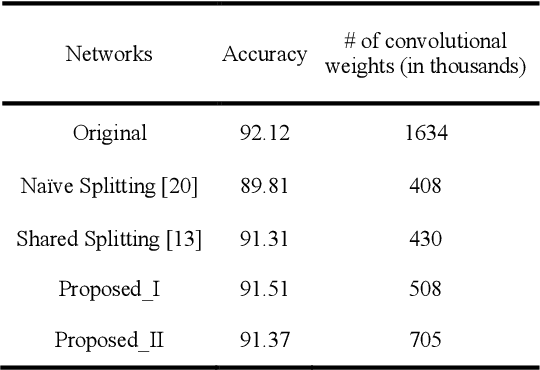
For convolutional neural networks (CNNs) that have a large volume of input data, memory management becomes a major concern. Memory cost reduction can be an effective way to deal with these problems that can be realized through different techniques such as feature map pruning, input data splitting, etc. Among various methods existing in this area of research, splitting the network structure is an interesting research field, and there are a few works done in this area. In this study, the problem of reducing memory utilization using network structure splitting is addressed. A new technique is proposed to split the network structure into small parts that consume lower memory than the original network. The split parts can be processed almost separately, which provides an essential role for better memory management. The split approach has been tested on two well-known network structures of VGG16 and ResNet18 for the classification of CIFAR10 images. Simulation results show that the splitting method reduces both the number of computational operations as well as the amount of memory consumption.
Convolutional Neural Network Pruning Using Filter Attenuation
Feb 09, 2020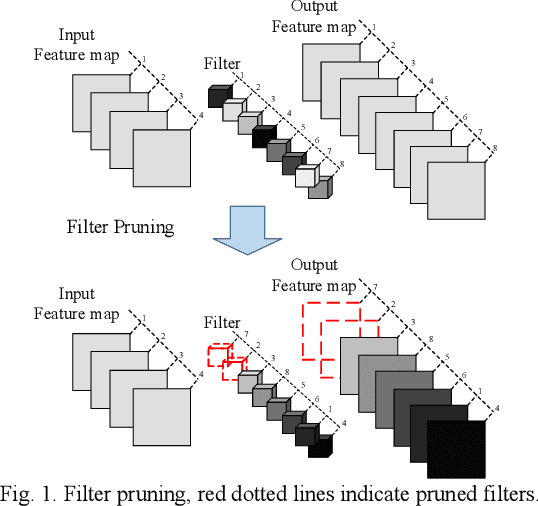
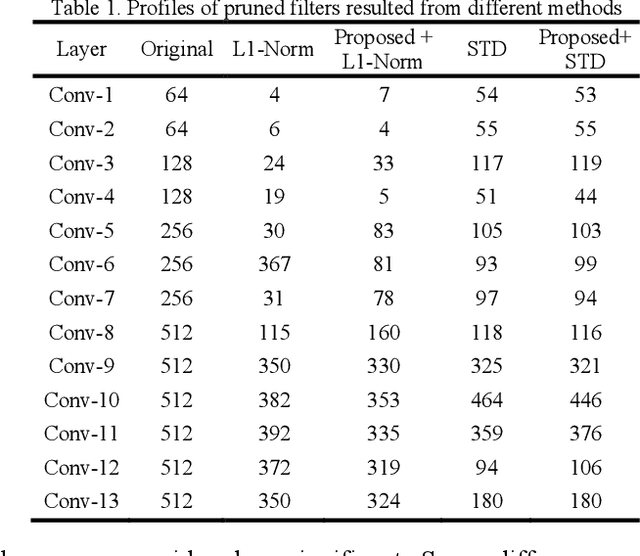
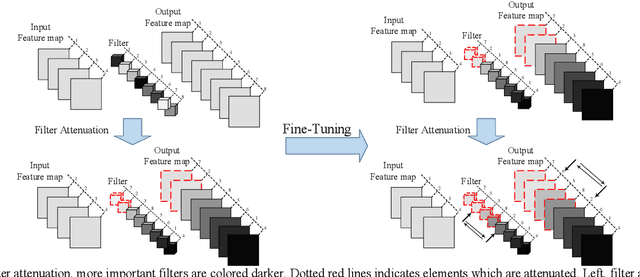

Filters are the essential elements in convolutional neural networks (CNNs). Filters are corresponded to the feature maps and form the main part of the computational and memory requirement for the CNN processing. In filter pruning methods, a filter with all of its components, including channels and connections, are removed. The removal of a filter can cause a drastic change in the network's performance. Also, the removed filters cannot come back to the network structure. We want to address these problems in this paper. We propose a CNN pruning method based on filter attenuation in which weak filters are not directly removed. Instead, weak filters are attenuated and gradually removed. In the proposed attenuation approach, weak filters are not abruptly removed, and there is a chance for these filters to return to the network. The filter attenuation method is assessed using the VGG model for the Cifar10 image classification task. Simulation results show that the filter attenuation works with different pruning criteria, and better results are obtained in comparison with the conventional pruning methods.
Modeling of Pruning Techniques for Deep Neural Networks Simplification
Jan 13, 2020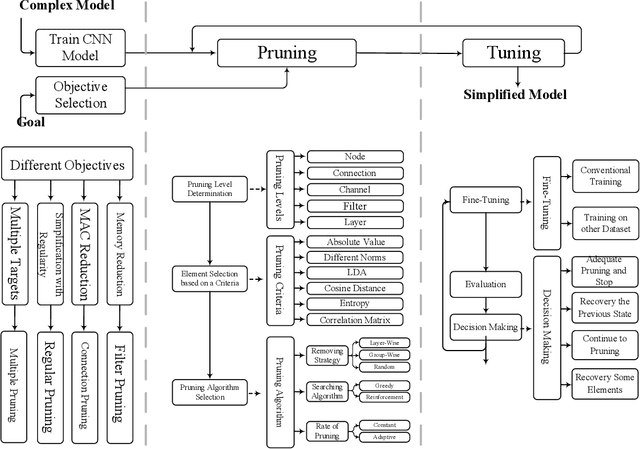
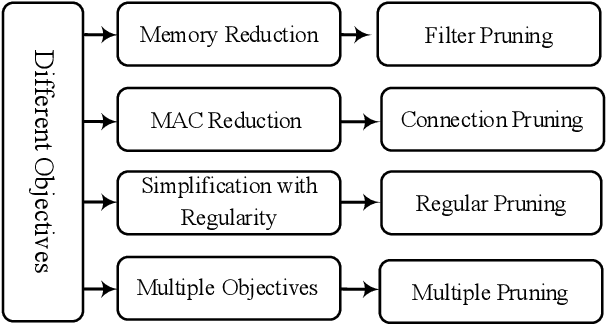
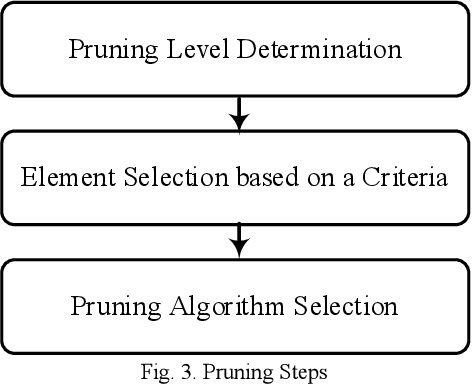
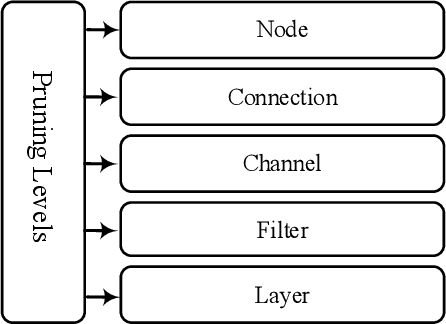
Convolutional Neural Networks (CNNs) suffer from different issues, such as computational complexity and the number of parameters. In recent years pruning techniques are employed to reduce the number of operations and model size in CNNs. Different pruning methods are proposed, which are based on pruning the connections, channels, and filters. Various techniques and tricks accompany pruning methods, and there is not a unifying framework to model all the pruning methods. In this paper pruning methods are investigated, and a general model which is contained the majority of pruning techniques is proposed. The advantages and disadvantages of the pruning methods can be identified, and all of them can be summarized under this model. The final goal of this model is to provide a general approach for all of the pruning methods with different structures and applications.
Modeling Neural Architecture Search Methods for Deep Networks
Dec 31, 2019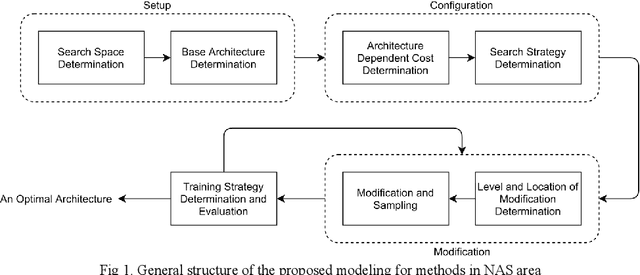
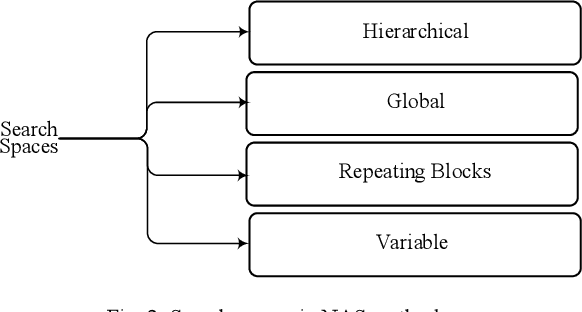
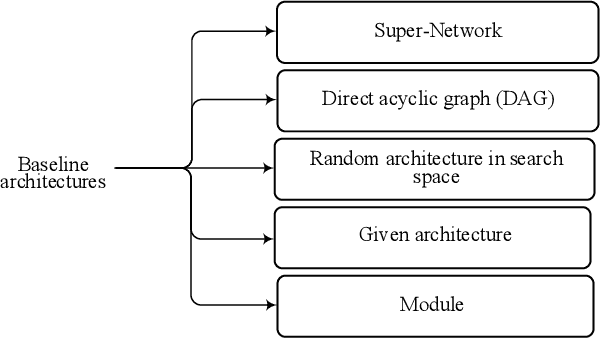
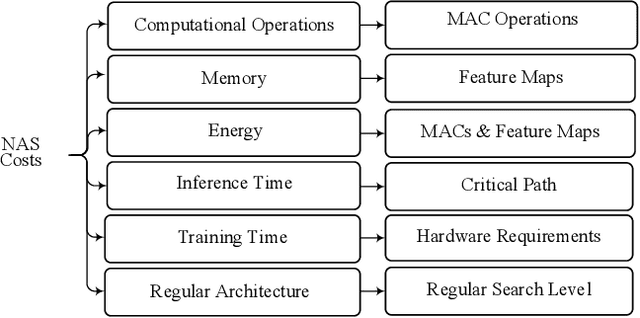
There are many research works on the designing of architectures for the deep neural networks (DNN), which are named neural architecture search (NAS) methods. Although there are many automatic and manual techniques for NAS problems, there is no unifying model in which these NAS methods can be explored and compared. In this paper, we propose a general abstraction model for NAS methods. By using the proposed framework, it is possible to compare different design approaches for categorizing and identifying critical areas of interest in designing DNN architectures. Also, under this framework, different methods in the NAS area are summarized; hence a better view of their advantages and disadvantages is possible.
Modeling Teacher-Student Techniques in Deep Neural Networks for Knowledge Distillation
Dec 31, 2019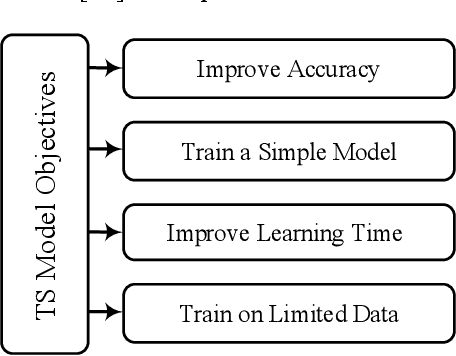
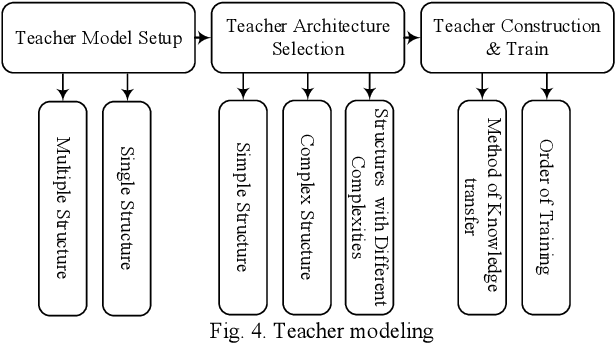
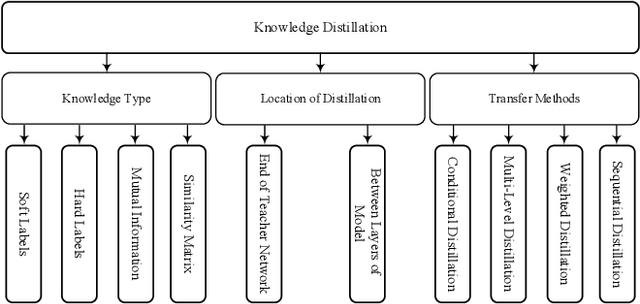
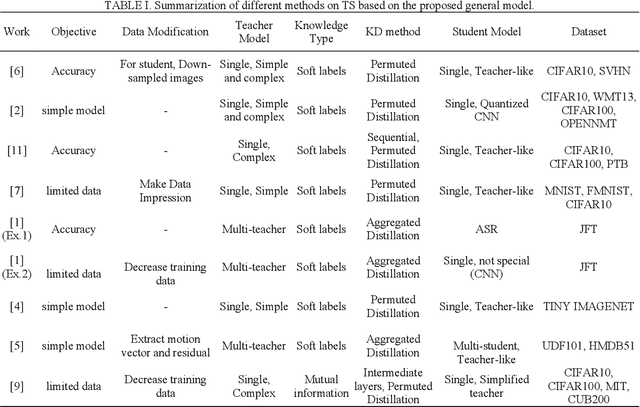
Knowledge distillation (KD) is a new method for transferring knowledge of a structure under training to another one. The typical application of KD is in the form of learning a small model (named as a student) by soft labels produced by a complex model (named as a teacher). Due to the novel idea introduced in KD, recently, its notion is used in different methods such as compression and processes that are going to enhance the model accuracy. Although different techniques are proposed in the area of KD, there is a lack of a model to generalize KD techniques. In this paper, various studies in the scope of KD are investigated and analyzed to build a general model for KD. All the methods and techniques in KD can be summarized through the proposed model. By utilizing the proposed model, different methods in KD are better investigated and explored. The advantages and disadvantages of different approaches in KD can be better understood and develop a new strategy for KD can be possible. Using the proposed model, different KD methods are represented in an abstract view.
Multiple Abnormality Detection for Automatic Medical Image Diagnosis Using Bifurcated Convolutional Neural Network
Oct 15, 2018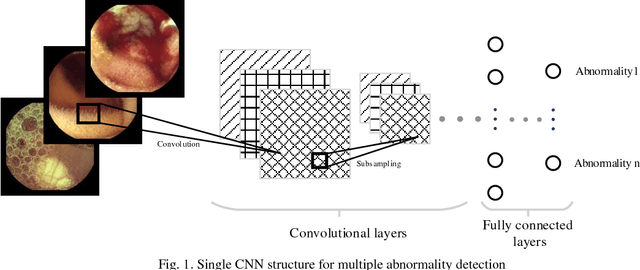
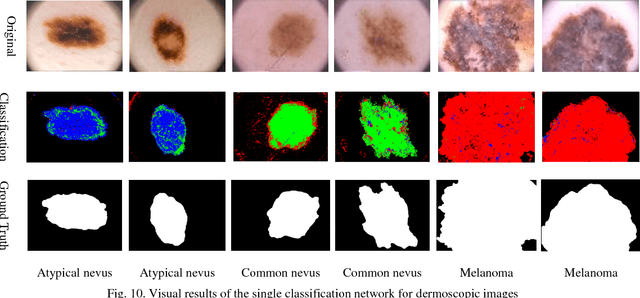
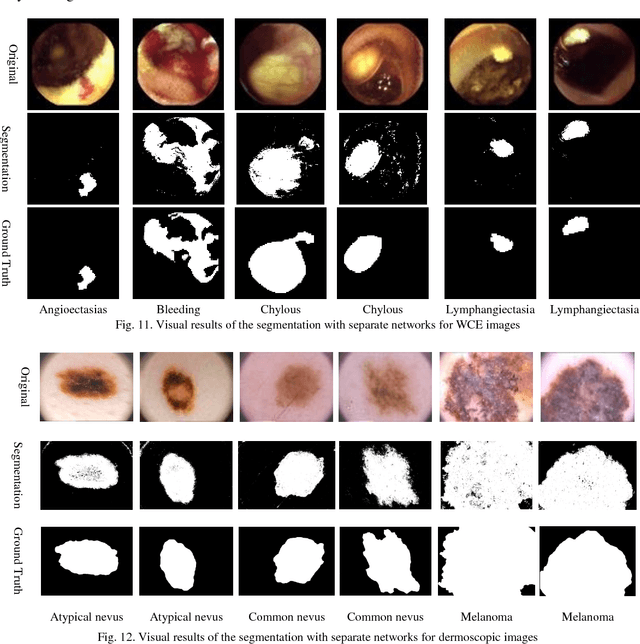
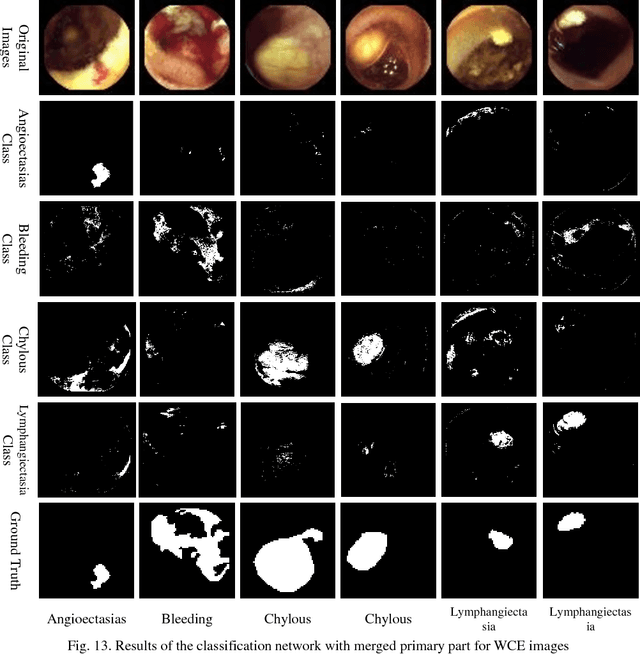
Automating classification and segmentation process of abnormal regions in different body organs has a crucial role in most of medical imaging applications such as funduscopy, endoscopy, and dermoscopy. Detecting multiple abnormalities in each type of images is necessary for better and more accurate diagnosis procedure and medical decisions. In recent years portable medical imaging devices such as capsule endoscopy and digital dermatoscope have been introduced and made the diagnosis procedure easier and more efficient. However, these portable devices have constrained power resources and limited computational capability. To address this problem, we propose a bifurcated structure for convolutional neural networks performing both classification and segmentation of multiple abnormalities simultaneously. The proposed network is first trained by each abnormality separately. Then the network is trained using all abnormalities. In order to reduce the computational complexity, the network is redesigned to share some features which are common among all abnormalities. Later, these shared features are used in different settings (directions) to segment and classify the abnormal region of the image. Finally, results of the classification and segmentation directions are fused to obtain the classified segmentation map. Proposed framework is simulated using four frequent gastrointestinal abnormalities as well as three dermoscopic lesions and for evaluation of the proposed framework the results are compared with the corresponding ground truth map. Properties of the bifurcated network like low complexity and resource sharing make it suitable to be implemented as a part of portable medical imaging devices.